HyperAI
Command Palette
Search for a command to run...
WideSearch 信息搜集基准数据集
*该数据集支持在线使用,点击此处跳转。
WideSearch 是由字节跳动 Seed 团队于 2025 年发布的首个专为「广域信息搜集(broad info-seeking)」设计的智能体评测基准数据集,相关论文成果为「WideSearch:Benchmarking Agentic Broad Info-Seeking」,旨在系统评估并推动大语言模型在大规模事实收集、综合与可核验的结构化输出上的可靠性与完整性。
该基准包含研究团队从真实用户查询中精心挑选并手工清洗出 200 个高质量问题(100 个英文问题、 100 个中文问题),这些问题来自 15 个以上的不同领域。
数据字段:
- instance_id:任务唯一 ID(与 gold CSV 文件名对应)。
- query:自然语言指令,通常明确所需列名与 Markdown 表格输出要求。
- evaluation:用于自动评测的序列化(字符串)对象,包含:
- unique_columns:主键列(用于行对齐);
- required:必须出现的列名;
- eval_pipeline:列级评测配置(如 preprocess 、 metric 、 criterion)。
- language:任务语言,取值为 en 或 zh 。
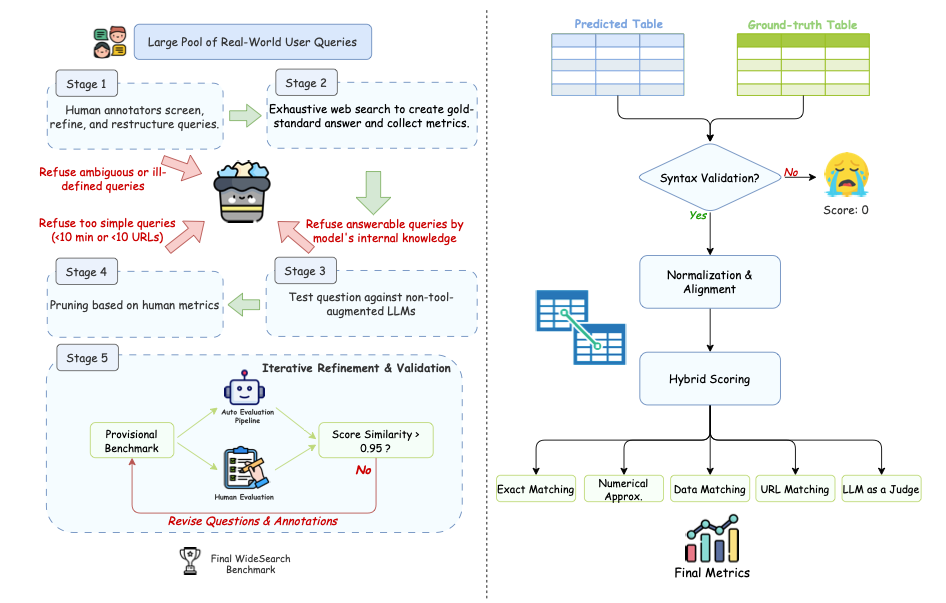
数据构建与自动评测流程图
该数据集由社区用户贡献,仅供交流学习使用。如内容涉及侵权,请联系邮箱 support@hyper.ai 以便及时审查和下架。