Command Palette
Search for a command to run...
描述任何事物:详细局部化图像与视频字幕生成
描述任何事物:详细局部化图像与视频字幕生成
摘要
在图像和视频中为特定区域生成详细且准确的描述,仍是视觉-语言模型面临的一项基本挑战。为此,我们提出了描述一切模型(Describe Anything Model, DAM),该模型专为详细局部化描述(Detailed Localized Captioning, DLC)任务而设计。DAM通过两项关键创新,有效保留了局部细节与全局上下文:一是焦点提示(focal prompt),确保目标区域的高分辨率编码;二是局部视觉主干网络(localized vision backbone),将精确的空间定位与整体上下文信息深度融合。为应对高质量DLC数据稀缺的问题,我们提出了一种基于半监督学习(Semi-supervised Learning, SSL)的数据构建流程——DLC-SDP。该流程以现有的分割数据集为基础,利用SSL技术逐步扩展至大量未标注的网络图像,从而大规模生成高质量的DLC训练数据。此外,我们构建了DLC-Bench,一个专门用于评估DLC任务的基准测试平台,其设计不依赖于参考描述(reference captions),从而更真实地反映模型的生成能力。实验结果表明,DAM在涵盖关键词级、短语级以及详细多句描述的7个不同基准测试中均取得了新的最先进性能(state-of-the-art),显著推动了局部化描述技术的发展。
一句话总结
来自NVIDIA、加州大学伯克利分校和旧金山加州大学的作者提出了Describe Anything Model (DAM),这是一种用于详细局部描述的新框架,通过结合焦点提示和局部视觉主干网络,保留细粒度细节与全局上下文,并利用半监督数据流水线克服数据稀缺问题,在图像和视频描述任务的七个基准上实现了最先进性能。
主要贡献
- 详细局部描述(DLC)仍然具有挑战性,因为需要在保留细粒度区域细节与维持全局上下文之间取得平衡,而先前的模型在从全局图像表示中提取特征或依赖边界框等粗略定位线索时往往难以兼顾。
- Describe Anything Model (DAM) 通过引入焦点提示以高密度编码目标区域,并采用融合精确定位与上下文感知能力的局部视觉主干网络,解决了这一问题,即使对于小尺寸或非显著物体也能生成丰富且准确的描述。
- 为克服数据稀缺问题,作者提出了 DLC-SDP,一种半监督数据流水线,利用分割数据集和网络图像自训练生成高质量的局部描述,并引入 DLC-Bench,一个基于属性级正确性评估、无需参考描述的新评估基准,实现更公平、更全面的模型评估。
引言
作者致力于解决在图像和视频中为特定区域生成详细、准确描述的挑战——这是细粒度视觉理解与交互式AI系统的关键能力。先前的视觉-语言模型在精确定位方面表现不佳,常因从全局表示中提取区域特征时丢失细节,或依赖边界框等弱定位线索,导致生成模糊或上下文错误的描述。此外,现有数据集缺乏对非显著或小区域的高质量、详细描述,而标准基准对模型在参考描述中未包含的正确细节进行惩罚,导致评估结果具有误导性。为解决这些问题,作者提出了Describe Anything Model (DAM),该模型结合焦点提示以高分辨率编码用户指定区域,以及局部视觉主干网络以同时保留局部细节与全局上下文。作者进一步提出 DLC-SDP,一种利用分割数据集和未标注网络图像的半监督数据流水线,以生成多样且高质量的局部描述。最后,作者引入 DLC-Bench,一种基于属性级评分的无参考评估框架,实现对详细区域描述的更公平评估。这些贡献共同在图像与视频的详细局部描述任务中建立了新的最先进水平。
数据集
- 数据集通过两阶段半监督学习流水线(DLC-SDP)构建,结合现有分割数据集与自标注技术,生成高质量、详细的局部描述。
- 第一阶段使用四个实例与语义分割数据集,利用现成的视觉-语言模型(VLM)在20.2万张图像中注释60.3万个区域。额外合并来自PACO的8.1万个实例,以增强部件描述能力,总计获得68.4万个标注区域。
- 第二阶段对SA-1B的10%进行自标注,在59.3万张图像上生成77.4万个标注。作者不使用原始掩码,而是采用OWL-ViT v2进行开放词汇检测,SAM生成掩码,再通过ViTDet + Cascade Mask R-CNN进行实例分割,以过滤部分物体掩码。
- 对每个区域,作者使用裁剪图像和掩码图像作为VLM输入,并在提示中包含物体类别名称以减少歧义。提示包含详细指令,如“详细描述被掩码区域”,并附加15种变体,根据句子或词数进行条件控制,以提升泛化能力。
- 数据质量通过基于OWL-ViT v2、SAM和SigLIP图像-文本相似度的置信度得分进行拒绝采样保障。图像最多包含两个实例,且必须属于不同类别。
- 最终训练数据包含150万个样本,规模与Ferret和RegionGPT等先前工作相当,但性能显著更优,证明了该数据流水线的有效性。
- 对于视频描述,从SA-V中对3.7万视频的9.4万个区域进行标注,每个区域(masklet)代表跨多帧的对象。使用实例分割将masklet与完整对象实例匹配,确保标注准确。
- 训练过程中,模型使用VILA 1.5的训练方案在图像和视频数据上进行微调,将视频视为8个拼接帧。3B和8B版本分别在8和32块A100 GPU上训练1个epoch,批量大小为2048,学习率分别为1e-4和1e-5。
- 采用焦点裁剪策略,将区域扩展1倍宽高(最多扩大至9倍总面积),并确保任一维度最小为48像素,以保留小区域的上下文。
- 模型训练中使用提示增强,随机从15种提示变体中选择,这些变体在表述上有所不同,并根据描述长度添加条件后缀,提升指令遵循能力与泛化性能。
方法
作者利用Describe Anything Model (DAM) 生成图像和视频中用户指定区域的详细局部描述。DAM通过其提出的焦点提示和局部视觉主干网络,有效平衡局部细节与上下文信息。如框架图所示,DAM包含两个关键组件:焦点提示和局部视觉主干网络。焦点提示旨在提供目标区域在其更广泛上下文中的详细表示。它包含完整图像及其对应掩码,以及以指定区域为中心的焦点裁剪图像及其掩码。作者首先提取掩码 M 的边界框 B,并在水平和垂直方向上按因子 α 扩展,以包含更多周围上下文:
B′=ExpandBox(B,α).例如,设置 α=3 时,区域最大可扩大至原始边界框的9倍,受限于图像边界。若扩展后边界框的高度或宽度小于48像素,则在该维度强制最小尺寸为48像素,以确保极小区域仍具备足够上下文。焦点裁剪图像和掩码为:
I′=I∣B′,M′=M∣B′,其中 ∣B′ 表示裁剪至 B′。因此,焦点提示包含:1) 完整图像 I 及其掩码 M;2) 焦点裁剪图像 I′ 及其掩码 M′。通过同时包含完整图像与焦点裁剪图像及其掩码,焦点提示既包含全局上下文,又提供目标区域的详细视图。
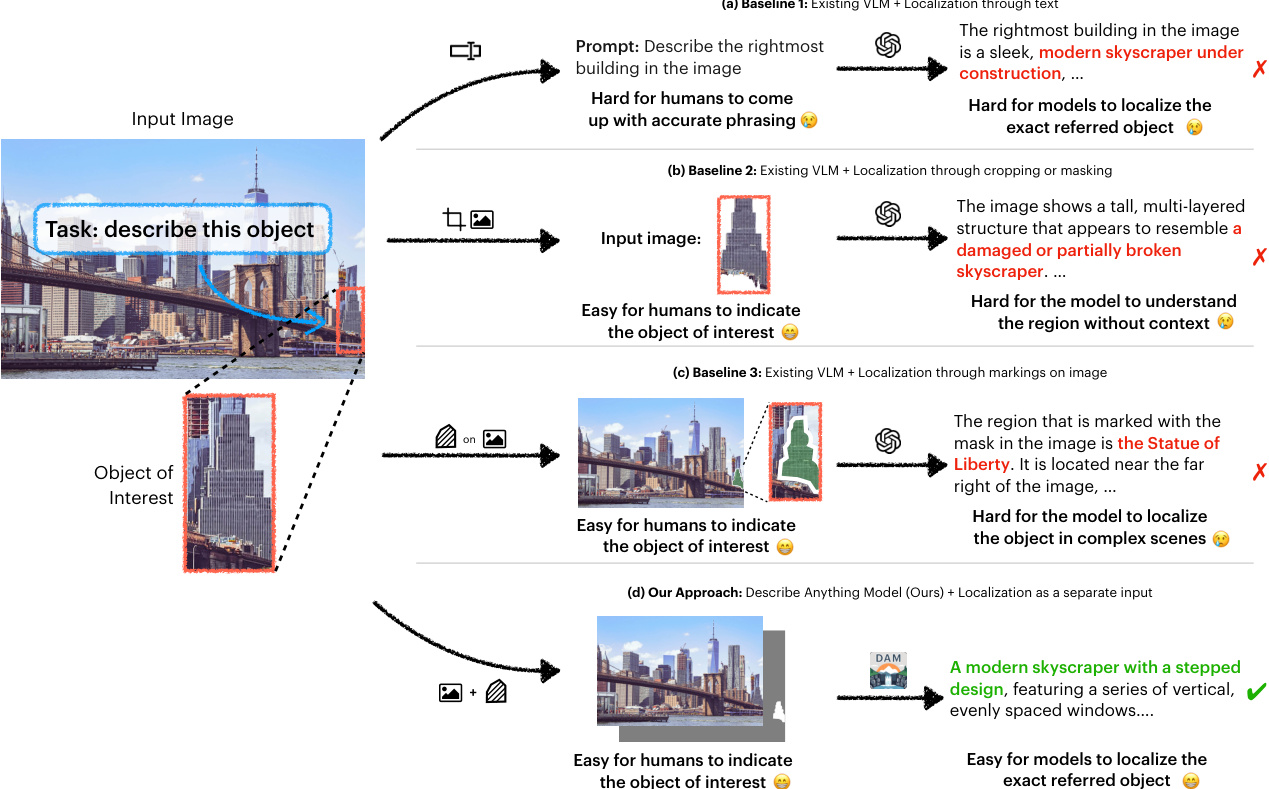
局部视觉主干网络旨在高效处理焦点提示的全部四个组件。完整图像 I 及其掩码 M 经过补丁嵌入层,再通过全局视觉编码器 fG(⋅) 得到全局视觉特征 z。焦点裁剪图像 I′ 及其掩码 M′ 采用类似流程,通过区域视觉编码器 fR(⋅) 处理,但 fR(⋅) 还将 z 作为上下文输入,以获得最终融合的视觉特征 z′。具体而言,作者提出:
x=EI(I)+EM(M)+P,z=fG(x), x′=Ei(I′)+EM(M′)+P,z′=fR(x′,z),其中 EI(⋅) 和 EM(⋅) 分别为图像和掩码的补丁嵌入层,x 和 x′ 为包含图像与掩码信息的全局与焦点嵌入输入,P 表示位置编码。新增的掩码嵌入层 EM 初始化为输出零值,确保在微调前VLM的初始行为不受影响。
为将全局上下文融入目标区域,作者在区域视觉编码器 fR 的每个Transformer块中插入门控交叉注意力适配器。在自注意力与前馈层之后,门控交叉注意力机制允许局部特征关注全局特征:
h(l)′=h(l)+tanh(γ(l))⋅CrossAttn(h(l),z) hAdapter(l)=h(l)′+tanh(β(l))⋅FFN(h(l)′),其中 h(l) 为 fR 中第 l 个自注意力块的输出,γ(l) 与 β(l) 为可学习的缩放参数,初始化为零,CrossAttn 表示查询来自 h(l),键与值来自全局特征 z 的交叉注意力。hAdapter(l) 用于替代 h(l) 进入下一个Transformer块。为减少参数量,fR 与 fG 共享自注意力块权重。通过将 γ(l) 与 β(l) 初始化为零,模型在微调前的行为与原始VLM保持一致。训练过程中,模型学习利用全局上下文增强局部特征表示,从而生成更详细且上下文准确的描述。
来自全局与区域视觉编码器的视觉特征被合并后输入大语言模型,生成详细、上下文感知的描述 T:
T=LLM(t,z′),其中 t 表示文本提示标记。值得注意的是,所提出的组件并未增加视觉标记的序列长度,确保DAM保持高效。通过将新模块(掩码嵌入 EM 与缩放参数 γ(l) 和 β(l))初始化为零,模型在微调前保留了VLM的预训练能力,使得无需重新预训练即可平滑适配现成VLM。得益于这一设计,模型所需训练数据量远低于涉及VLM预训练的先前工作(约150万样本)。
该模型自然扩展至视频处理,通过处理帧序列及其对应掩码。所有帧的视觉特征在序列维度上拼接后输入语言模型,生成跨视频帧的详细局部描述,与VLM预训练时处理视频的方式兼容。作者利用SAM 2 [62] 将稀疏定位转换为每帧的掩码。
实验
- DLC-Bench 通过基于大语言模型的正向与负向问题评估详细局部描述(DLC)的准确性与幻觉规避能力,无需依赖参考描述。
- 在PACO上,DAM实现73.2%的语义IoU与84.2%的语义相似度,分别超越此前最佳结果23.2%与8.5%。
- 在Ref-L4上,DAM在短语言指标上实现33.4%的相对提升,在长语言指标上实现13.1%的提升。
- 在提出的DLC-Bench上,DAM超越现有开源与仅API模型(包括GPT-4o和o1),在正向与负向准确率上均达到最先进水平。
- 在HC-STVG上,DAM相比此前最佳结果(包括同期工作VideoRefer)实现19.8%的相对提升。
- 在VideoRefer-Bench上,DAM在零样本与域内设置下均超越先前方法,展现出强大的泛化能力。
- 消融实验表明,结合交叉注意力与局部裁剪的焦点提示显著提升性能,达到67.3%的准确率。
- 数据扩展与半监督学习(SSL)进一步提升性能,SSL在使用10%未标注SA-1B数据时将准确率提升至67.3%。
作者使用SA-V数据集(包含36,922个视频与93,969个区域)训练详细局部视频描述模型。该数据集为评估与提升模型在多帧中理解与描述对象的能力提供了大规模视频区域来源。
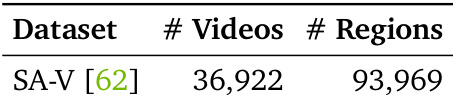
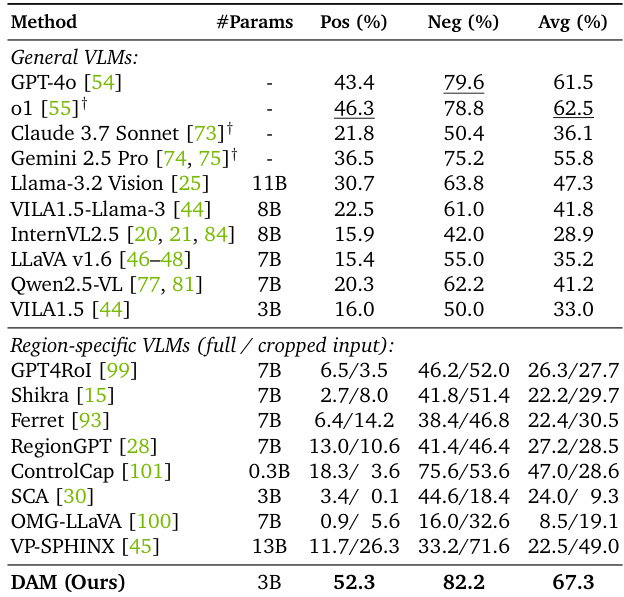
作者使用DLC-Bench评估详细局部描述模型,评估其包含正确细节与排除无关或错误信息的能力。结果表明,DAM实现67.3%的最高平均准确率,优于其他通用与区域特定VLM,正向与负向准确率均表现优异。
作者使用LVIS基准评估模型在开放类别关键词级局部描述上的性能,结果显示,增加额外数据集使正向准确率从34.0%提升至47.5%,平均准确率从53.3%提升至63.8%。进一步在10% SA-1B图像上引入半监督学习,平均准确率提升至67.3%,证明了数据扩展与多样化训练数据的优势。

作者使用DLC-Bench评估详细局部描述,模型根据其包含正确细节与排除无关或错误信息的能力进行评分。结果表明,DAM在多个基准上均达到最先进性能,包括在PACO上实现73.2%的语义IoU与84.2%的语义相似度,并在DLC-Bench上显著超越现有模型,正向与负向准确率均极高。

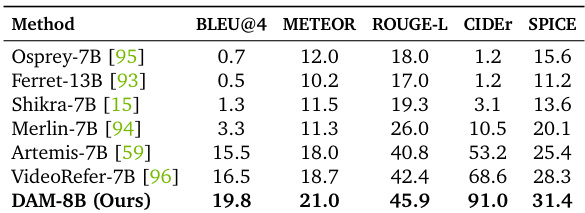
结果表明,DAM-8B在多个指标上均达到最先进水平,优于此前模型如Osprey-7B与Ferret-13B,在BLEU@4、METEOR、ROUGE-L、CIDEr与SPICE上表现更优。模型在详细与局部描述方面展现出卓越的生成质量,短语言与长语言评估指标均有显著提升。