Command Palette
Search for a command to run...
AlphaEdit:针对语言模型的零空间约束知识编辑
AlphaEdit:针对语言模型的零空间约束知识编辑
Junfeng Fang Houcheng Jiang Kun Wang Yunshan Ma Shi Jie Xiang Wang Xiangnan He Tat-seng Chua
摘要
大型语言模型(LLMs)常常因存在错误或过时的知识而产生幻觉。为此,模型编辑方法应运而生,以实现对知识的精准更新。目前主流的范式是“定位-编辑”方法:首先定位对模型输出具有重要影响的参数,然后通过引入扰动来修改这些参数。尽管该方法有效,但现有研究已表明,这种扰动不可避免地会破坏模型中原本保留的知识,尤其是在连续编辑场景下问题更为显著。为解决这一问题,我们提出 AlphaEdit,一种新颖的解决方案:在将扰动应用于参数之前,先将其投影到已保留知识的零空间中。我们从理论上证明,该投影机制可确保在对保留知识进行查询时,编辑后模型的输出保持不变,从而有效缓解知识破坏问题。在多种大型语言模型(包括 LLaMA3、GPT2-XL 和 GPT-J)上的大量实验表明,仅通过添加一行代码实现投影,AlphaEdit 即可使大多数“定位-编辑”方法的性能平均提升 36.7%。相关代码已开源,地址为:this https URL。
一句话总结
中国科学技术大学与新加坡国立大学的研究人员提出 AlphaEdit,一种通过将参数扰动投影到零空间以在大语言模型编辑过程中保留已有知识的技术,显著提升 LLaMA3 和 GPT-J 等模型的性能达 36.7%,且代码开销极小。
主要贡献
- AlphaEdit 通过将参数扰动投影到保留知识的零空间,解决大语言模型编辑中知识破坏的问题,确保未修改查询的输出保持不变,从而防止在连续编辑过程中模型遗忘。
- 该方法引入理论支撑的约束,无需平衡更新误差与保留误差,使优化可专注于新知识,同时保持大语言模型各层隐藏表示的稳定性。
- 在 LLaMA3、GPT2-XL 和 GPT-J 上评估,AlphaEdit 平均将多数“定位后编辑”方法的性能提升 36.7%,仅需一行代码,展现即插即用兼容性,且无需修改架构即可获得显著性能增益。
引言
作者利用零空间投影技术解决现有大语言模型编辑方法的一个关键缺陷:在更新目标事实时容易破坏保留的知识。当前“定位后编辑”方法在连续编辑过程中常过度拟合新知识,导致隐藏表示偏移,最终模型崩溃。AlphaEdit 通过从优化目标中移除保留约束,转而将参数更新投影到保留知识的零空间——保证未编辑查询的输出不变。这一单行代码增强使多个大语言模型的平均性能提升 36.7%,成为现有编辑框架的即插即用升级方案。
数据集
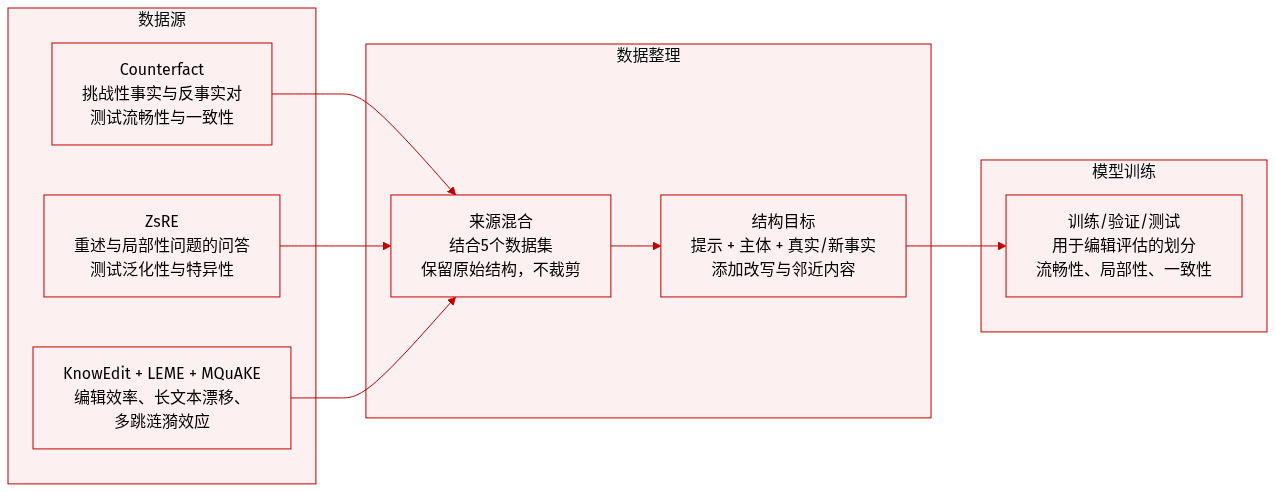
作者使用五个关键数据集的精选组合,从多个维度评估知识编辑性能:
-
Counterfact(Meng 等,2022):一个具有挑战性的数据集,对比事实与反事实陈述。通过替换主语实体生成超出范围的示例,同时保留谓语。包含多个改写生成提示,用于测试流畅性与一致性。用于评估泛化性与特异性。
-
ZsRE(Levy 等,2017):一个问答数据集,使用回译问题作为等价邻居。每个样本包含主语、目标答案、改写问题(用于泛化)和局部性问题(用于特异性)。自然问题作为超出范围数据,用于测试局部性。
-
KnowEdit(Zhang 等,2024d):一个综合基准,评估编辑方法在外部、内在及合并知识更新中的表现。作者特别使用其 wiki_recent 和 wikibio 子集,测试编辑效率与整体模型性能的保留。
-
LEME(Rosati 等,2024):聚焦长文本生成,揭示事实漂移与词汇连贯性问题。强调短文本指标不能反映长文本编辑的成功,为评估增加关键维度。
-
MQuAKE(Zhong 等,2023):测试多跳推理,评估事实编辑后的涟漪效应。衡量推断信念的一致性,暴露处理复杂关系依赖的局限性。
数据集经过处理,包含结构化编辑目标:每个样本包含提示、主语、真实与新目标事实,以及多种提示变体(改写、邻居、属性和生成提示)。这些变体支持对流畅性、泛化性、局部性和一致性的评估。作者未对原始数据集结构之外应用裁剪或元数据构建。训练划分与混合比例未在文本中指定,但数据集共同用于在多个性能维度上基准测试编辑方法。
方法
作者利用零空间投影机制约束大语言模型中的模型编辑,确保事实知识更新不会干扰已保留或先前编辑的知识。核心洞察是:应用于模型前馈网络权重 W 的扰动可投影到 K0 —— 编码保留知识的矩阵 —— 的零空间中,使 (W+ΔP)K0=WK0=V0,从而保持现有关联不变。
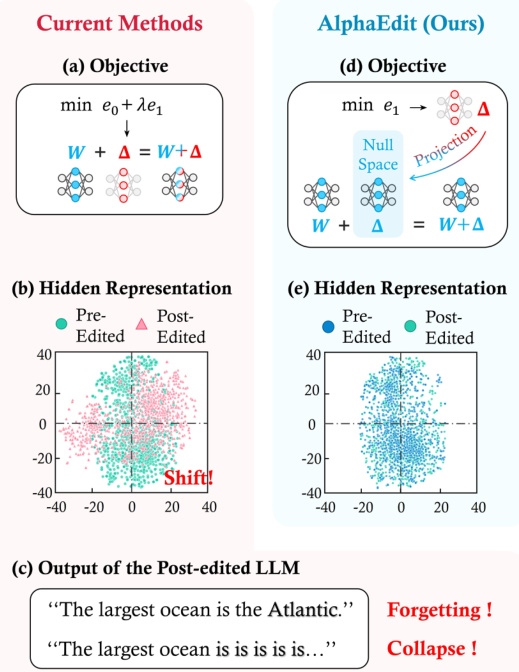
该方法始于认识到标准模型编辑目标(如 MEMIT 所用)需在更新知识(K1,V1)的保真度与保留知识(K0,V0)之间取得平衡。这种双重目标常导致次优收敛或意外副作用,如当前方法与 AlphaEdit 的对比图所示。在当前方法中,扰动 Δ 被计算以最小化更新知识和保留知识的误差,这可能导致表示漂移和输出崩溃——如“编辑后大语言模型输出”面板所示,模型编辑后生成不连贯文本。
如下图所示,AlphaEdit 通过首先计算标准扰动 Δ~,然后通过投影矩阵 P 将其投影到 K0 的零空间,得到 ΔP。该投影确保扰动对 K0 无影响,使优化目标可专注于更新知识 K1 和先前编辑知识 Kp,无需显式保留项。最终目标变为:
Δ=Δ~argmin(∣∣(W+Δ~P)K1−V1∣∣2+∣∣Δ~P∣∣2+∣∣Δ~PKp∣∣2).此重构消除了优化过程中计算或存储 K0 的需要,降低计算开销的同时提高编辑保真度。
投影矩阵 P 由非中心协方差矩阵 K0K0T 的奇异值分解推导,该矩阵与 K0 共享相同的零空间,但因其维度较小而计算可行。具体而言,通过 SVD 计算 U 和 Λ 后,作者仅保留对应零特征值的特征向量以构建 U^,并定义 P=U^U^T。该矩阵每模型计算一次,并在所有编辑任务中重复使用,使 AlphaEdit 高效。
最终扰动 ΔAlphaEdit 以闭式获得:
ΔAlphaEdit=RK1TP(KpKpTP+K1K1TP+I)−1,其中 R=V1−WK1 为残差误差。该解在结构上与 MEMIT 更新相似,仅因包含 P 而不同,从而可无缝集成到现有编辑管道中。如附图强调,此修改仅需一行代码——投影步骤——即可将任何标准编辑方法转换为其零空间约束变体。

实验
- AlphaEdit 在顺序编辑任务中优于基线方法,显著提升有效性与泛化性,同时缓解模型遗忘与崩溃。
- 编辑后模型在广泛 NLP 任务中保持强大通用能力,即使经过大量编辑,而基线方法迅速退化。
- AlphaEdit 通过保留隐藏表示分布防止对更新知识的过拟合,维持模型稳定性与连贯性。
- 将 AlphaEdit 的投影策略集成到基线方法中带来显著性能提升,增强编辑准确性和通用能力。
- 该方法在多个大语言模型和数据集上表现稳健,包括涉及多跳推理和长文本生成的挑战性基准。
- 在关键指标数据量减少时性能保持稳定,但数据严重受限时特异性下降。
- AlphaEdit 随模型规模高效扩展,不增加运行时开销,适用于大规模编辑应用。
作者使用 AlphaEdit 进行顺序模型编辑,并在多个大语言模型和数据集上与 MEMIT 比较其运行时效率。结果表明 AlphaEdit 未引入可测量的运行时开销,保持与 MEMIT 几乎相同的每批次编辑时间,同时在知识更新与保留方面表现更优。这证实了 AlphaEdit 在大规模编辑任务中的可扩展性与实用性,且不牺牲速度。

AlphaEdit 在多跳推理和长文本生成任务中持续优于基线方法,展示 GPT-J 和 GPT2-XL 模型中更强的事实一致性与内部连贯性。该方法在复杂推理场景中保持高性能,同时保留生成文本的结构完整性,表明其泛化能力超越简单事实更新。
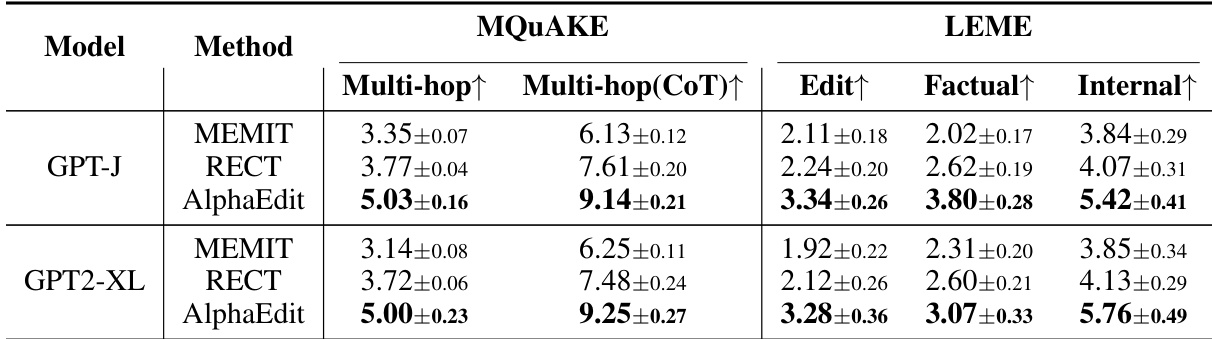
AlphaEdit 在 wiki_recent 和 wikibio 数据集上显著优于 MEMIT 和 RECT 等基线方法,实现最高编辑成功率,同时保持强流畅性与局部性。结果证实 AlphaEdit 有效保留编辑事实周围的模型行为,不降低输出质量,即使在挑战性知识更新任务中。

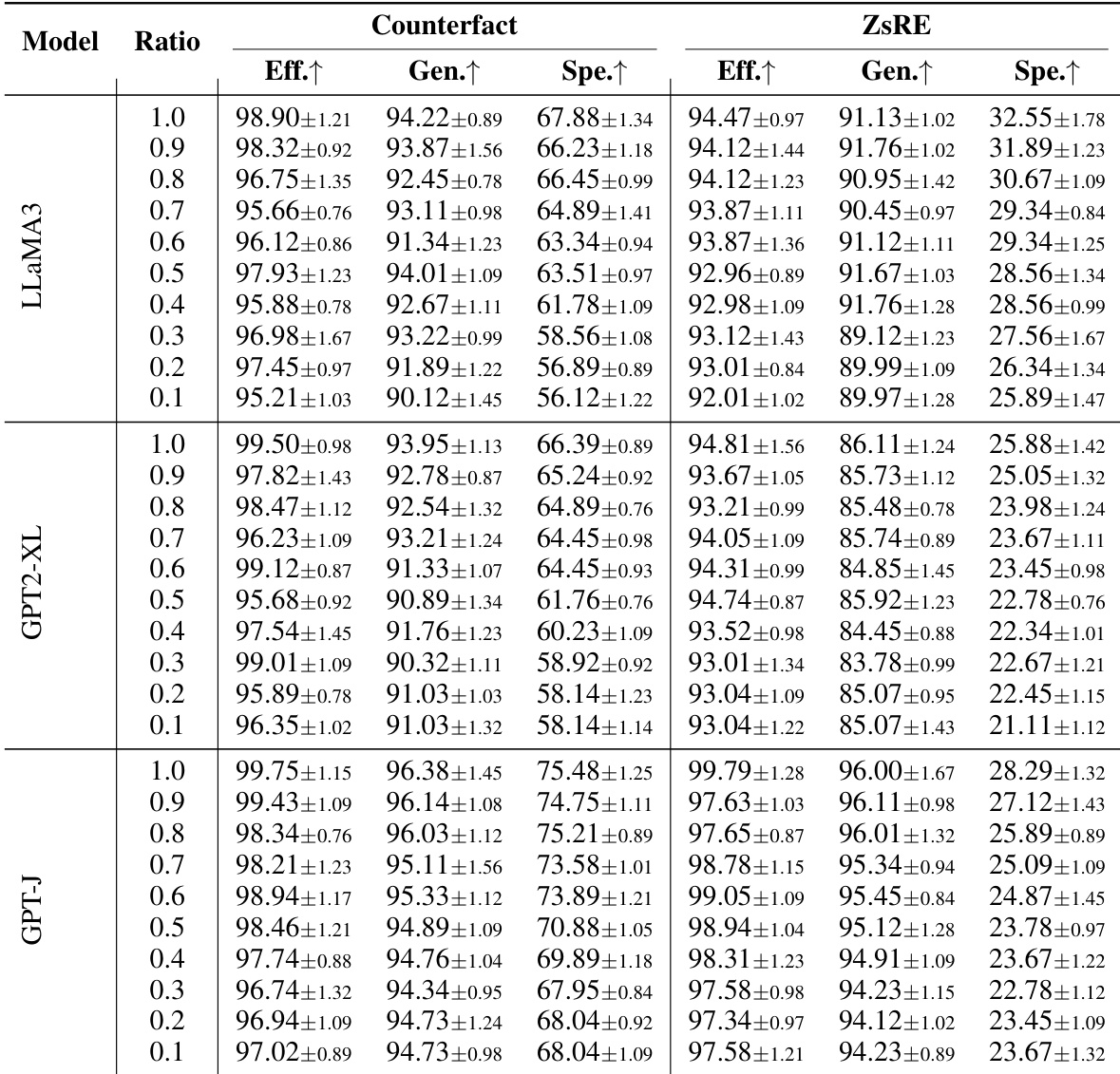
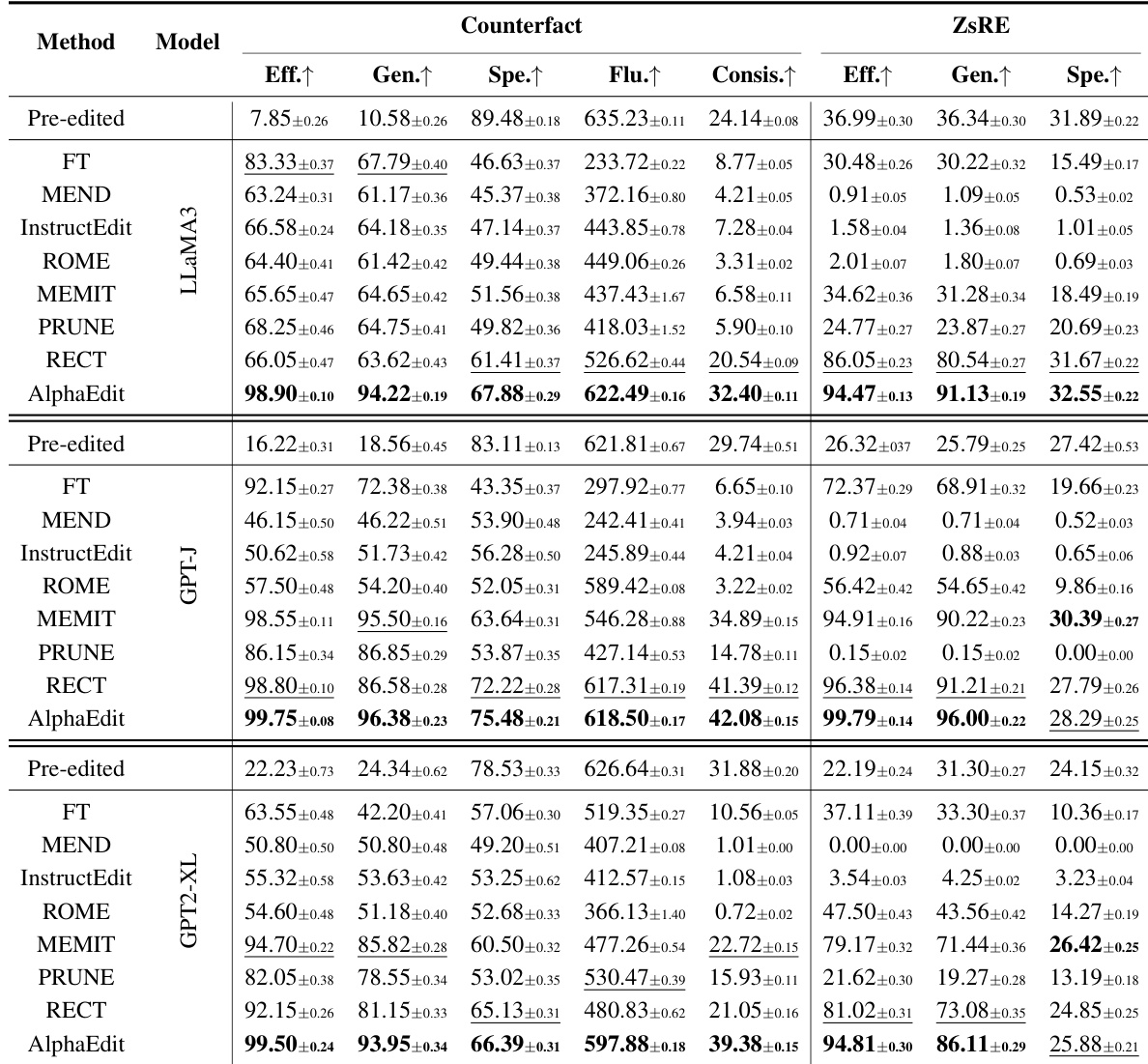
AlphaEdit 在多个大语言模型和数据集上持续优于基线方法,实现最高有效性与泛化性得分,同时保持强流畅性与特异性。该方法在顺序编辑过程中有效保留模型原始能力,避免其他方法常见的退化。其零空间投影技术集成后亦增强基线方法,展现跨模型架构的广泛适用性与稳健性。
作者使用 AlphaEdit 在多个大语言模型上进行顺序知识编辑,并评估其在不同数据比例下对有效性、泛化性与特异性的影响。结果表明,即使训练数据减少,AlphaEdit 仍保持高编辑性能,尤其在有效性和泛化性方面,而特异性在较低数据比例下下降更明显。这表明 AlphaEdit 在知识更新任务中的稳健性及其在有限数据下有效泛化的能力。