Command Palette
Search for a command to run...
基于自蒸馏的强化学习
基于自蒸馏的强化学习
摘要
大型语言模型在可验证领域(如代码和数学)中正越来越多地通过强化学习进行后续训练。然而,现有的可验证奖励强化学习(RLVR)方法仅基于每次尝试的标量结果奖励进行学习,导致严重的信用分配瓶颈。事实上,许多可验证环境会提供丰富的文本反馈,例如运行时错误信息或评分员的评价,这些反馈能够解释尝试失败的原因。我们首次将这一场景形式化为“基于丰富反馈的强化学习”,并提出自蒸馏策略优化(Self-Distillation Policy Optimization, SDPO)。SDPO无需外部教师模型或显式的奖励模型,即可将分词后的反馈转化为密集的学习信号。SDPO将当前模型在给定反馈条件下的输出视为自教师,将其基于反馈生成的下一词预测结果回传并蒸馏到策略中。通过这种方式,SDPO充分利用了模型在上下文中回溯识别自身错误的能力。在LiveCodeBench v6上的科学推理、工具使用和竞赛编程任务中,SDPO在样本效率和最终准确率方面均显著优于现有的强基准RLVR方法。值得注意的是,即使在仅返回标量反馈的标准RLVR环境中,SDPO也通过将成功轨迹作为失败尝试的隐式反馈,超越了现有基线方法的表现。最后,在测试阶段对单个问题应用SDPO,可显著加速复杂二元奖励任务中的探索过程,仅用三倍于基线的尝试次数,即可达到与“最佳k次采样”或多轮对话方法相当的发现概率。
一句话总结
来自苏黎世联邦理工学院、马克斯·普朗克研究所、麻省理工学院和斯坦福大学的研究人员提出了 SDPO,这是一种自蒸馏方法,可将丰富的文本反馈转化为大语言模型的密集训练信号,通过让模型在上下文内分析自身错误进行学习,从而在代码和数学任务中提升样本效率和准确性,无需外部教师。
主要贡献
- SDPO 引入了一种新颖的强化学习框架,适用于可验证领域,利用丰富的文本反馈(如运行时错误或评判评论)克服仅依赖标量奖励方法的信用分配瓶颈,形式化为“带丰富反馈的强化学习”(RLRF)。
- 该方法将当前模型作为自教师:在接收反馈后,逐标记重新评估自身生成内容,并将反馈条件下的下一标记预测蒸馏回策略中,实现无需外部教师或奖励模型的密集、logit 级别学习。
- 在 LiveCodeBench v6 上评估,涵盖科学推理、工具使用和竞赛编程任务,SDPO 在样本效率和最终准确率上优于 RLVR 基线,甚至在标量奖励设置中通过将成功生成视为隐式反馈提升性能,同时相比 best-of-k 采样将测试时尝试次数减少 3 倍。
引言
作者利用带丰富反馈的强化学习——环境中提供标记化解释,如运行时错误或评判评论——克服了 GRPO 等标量奖励方法的信用分配瓶颈。先前方法要么依赖稀疏奖励,要么需要外部教师提供密集监督,限制了在线学习的可扩展性和实用性。其主要贡献是自蒸馏策略优化(SDPO),使用模型自身作为自教师:在接收反馈后,它在上下文内重新评估自身生成内容,并将修正后的下一标记预测蒸馏回策略中。这实现了无需外部监督的密集、logit 级别信用分配,提升了推理和编码任务中的样本效率和最终准确率——即使在标量奖励设置中——同时可作为即插即用模块集成到现有 RLVR 流程中。
方法
作者采用自蒸馏框架——自蒸馏策略优化(SDPO),复用同一策略模型担任双重角色:作为学生生成初始响应,同时作为自教师利用丰富反馈回溯评估这些响应。该架构通过比较学生在每个标记上的概率分布与教师在原始问题和反馈条件下的分布,实现密集的标记级信用分配。
核心机制始于采样一个问题 x 并从学生策略生成一个轨迹 y∼πθ(⋅∣x)。环境随后提供反馈 f,可能包括运行时错误、先前轨迹的样本解或任务特定指令。自教师定义为 πθ(⋅∣x,f),通过将反馈附加到相同问题中进行提示,使其能在额外上下文中重新评估学生的输出。如框架图所示,这形成了闭环训练信号,教师的评估指导学生的参数更新。

训练目标是最小化学生在每个时间步 t 的下一标记分布与教师分布之间的 KL 散度,教师参数在梯度计算中被分离以防止退化。损失公式如下:
LSDPO(θ):=t∑KL(πθ(⋅∣x,y<t)∣∣stopgrad(πθ(⋅∣x,f,y<t)))该梯度通过得分函数估计器推导,对应于 logit 级别的策略梯度,其中每个标记 y^t 的优势由 logπθ(y^t∣x,f,y<t)πθ(y^t∣x,y<t) 给出。正优势表示教师认为比学生更可能的标记,负优势标记学生过度自信偏离教师精炼判断的标记。
为控制计算成本,作者通过限制蒸馏仅针对学生在每个位置预测的前 K 个标记,并添加尾部项以覆盖剩余概率质量,近似完整 KL 散度。这减少了内存开销而不牺牲性能,因为在任何给定时间步,大多数词汇标记都是无关的。
训练稳定性通过两项关键修改增强。首先,自教师通过学生参数的指数移动平均(EMA)或与初始参考教师插值进行正则化,有效在分布空间中强制实施信任区域。其次,采用对称的 Jensen-Shannon 散度作为蒸馏损失,已被证明在类似蒸馏设置中改善收敛。
SDPO 梯度可通过 PPO 风格的裁剪重要性采样扩展到离策略数据,其中每个标记优势按旧策略与新策略概率的比率加权。此泛化允许 SDPO 利用经验回放,同时保持密集、反馈驱动的信用分配,区别于 GRPO 等标量奖励方法。
如训练流程图所示,SDPO 迭代优化策略:每个轨迹生成反馈,用于计算教师 log 概率,所得每个标记优势驱动参数更新。此过程重复进行,教师与学生同步改进,使模型能逐步内化反馈信号,在细粒度级别纠正自身错误。

实验
- SDPO 在推理和编码任务中优于 GRPO,以显著更短的响应长度实现更高准确率,表明推理更高效。
- 在无丰富反馈的环境中,SDPO 将批次内成功尝试作为隐式反馈,实现更快学习,某些任务训练时间加速达 10 倍。
- 在有丰富反馈(如编码环境)时,SDPO 利用密集信用分配提升最终准确率,仅用 4 倍更少生成次数即达到 GRPO 性能,且随着模型规模扩大增益放大。
- SDPO 支持测试时自蒸馏,对于困难的二元奖励问题,相比采样或多轮基线加速解决方案发现 3 倍,即使初始成功率接近零。
- SDPO 中的自教师在训练中持续改进,允许从弱性能启动并逐步提升至强性能,且正则化稳定学习而不冻结教师。
- SDPO 比离策略基线更好地避免灾难性遗忘,在学习新任务时保持先前能力。
- SDPO 的效率源于稀疏的标记级信用分配,消除了 GRPO 中常见的冗长、循环推理模式。
- 性能与模型规模紧密相关——更强模型支持更精确的回溯,使 SDPO 增益随规模涌现。
- 环境反馈与样本解互补;在重提示时排除学生原始尝试可提升探索与多样性。
作者使用 SDPO 训练无丰富环境反馈的推理任务模型,将批次内成功尝试视为失败尝试的反馈。结果表明,SDPO 在各学科和模型规模上始终优于 GRPO,以更短时间实现更高准确率——有时在不到一小时内达到 GRPO 5 小时的性能——并生成显著更短、更高效的响应。即使两种方法均使用在线策略训练,此改进仍成立,表明 SDPO 的自蒸馏机制在无需离策略更新的情况下提升了学习效率。
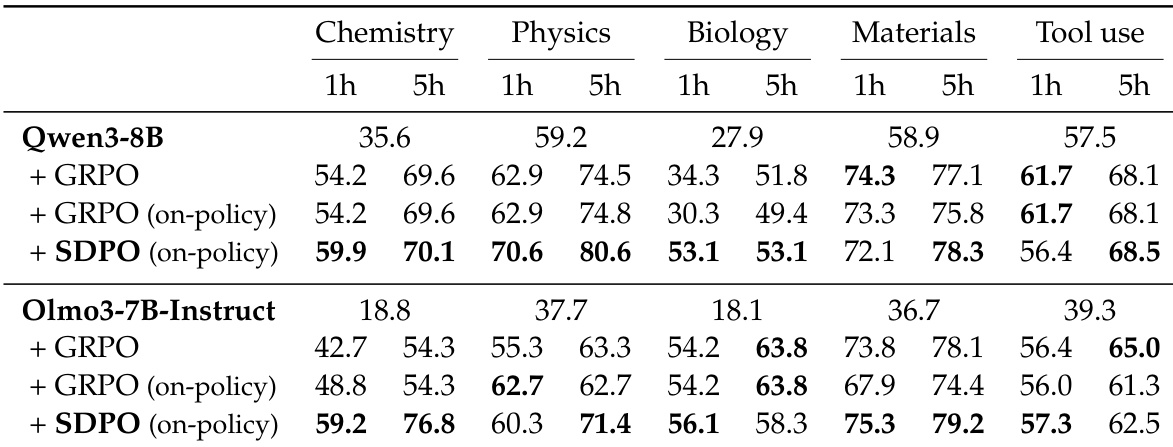
作者使用 SDPO 训练无丰富环境反馈的推理任务模型,将批次内成功尝试视为失败尝试的反馈。结果表明,SDPO 在各学科和模型规模上始终优于 GRPO,以更短时间实现更高准确率和显著更短响应长度,表明推理更高效。此改进在化学任务中尤为突出,SDPO 在不到一小时内达到 GRPO 5 小时的性能。
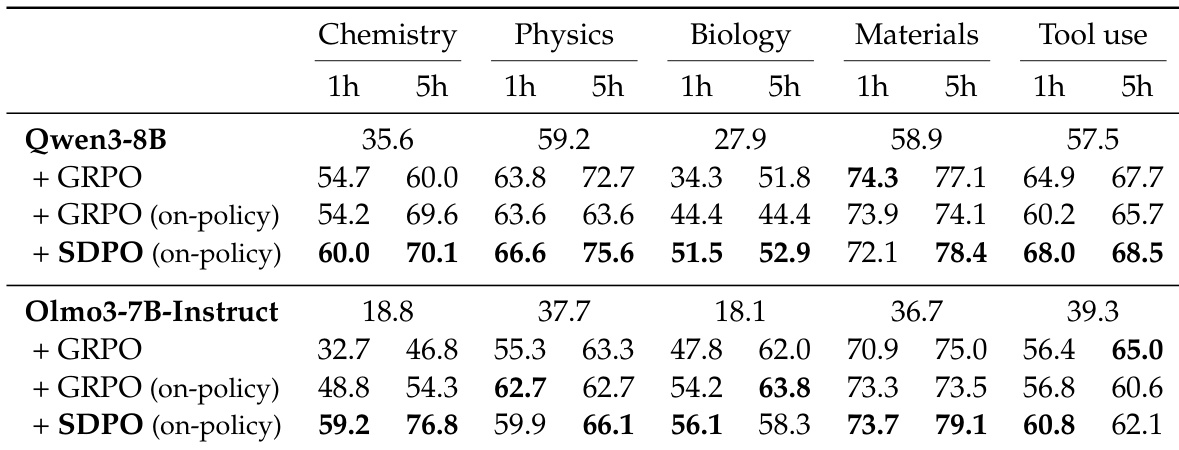
作者使用 SDPO 显著减少响应长度,相比 GRPO 保持或提升准确率,Qwen3-8B 和 Olmo3-7B-Instruct 均显示一致的 3.2 倍生成长度减少。此效率增益反映了 SDPO 通过利用密集标记级信用分配而非依赖冗长探索,生成简洁、无重复推理的能力。结果证实有效推理无需更长输出,SDPO 的自教学机制支持更聚焦、准确的生成。

作者使用 SDPO 提升带丰富反馈编码任务的性能,实现比 GRPO 和其他基线更高的最终准确率。结果表明 SDPO 不仅以更少生成次数达到 GRPO 最终准确率,且随更大模型规模扩展更有效,表明随着基础模型上下文学习能力提升,自教学变得更强大。

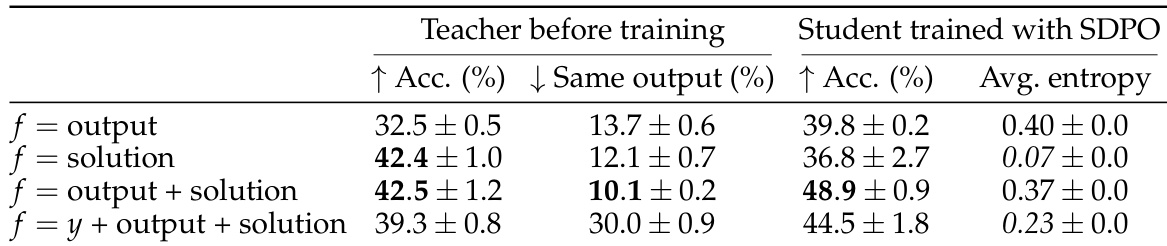
作者使用 SDPO 评估不同类型反馈在训练中对自教学的影响,发现结合环境输出与样本解可获得最高学生准确率和最低熵。结果表明,尽管初始教师性能因反馈类型而异,学生始终能超越教师起始水平,最有效的反馈带来最强增益。自教师在训练中精炼自身输出的能力支持迭代策略改进,即使初始准确率较低。