Command Palette
Search for a command to run...
在13个参数中进行推理学习
在13个参数中进行推理学习
John X. Morris Niloofar Mireshghallah Mark Ibrahim Saeed Mahloujifar
摘要
近期研究发现,语言模型能够通过强化学习(reinforcement learning)学会推理。部分研究甚至尝试为推理任务训练低秩参数化模型,但传统的LoRA方法无法将参数规模缩小至模型维度以下。我们质疑:在学习推理的过程中,是否真的需要秩为1的LoRA?为此,我们提出了TinyLoRA——一种可将低秩适配器缩放到仅含一个参数的新型方法。在我们提出的新参数化框架下,仅使用13个bf16精度的可训练参数(总计26字节),即可使Qwen2.5模型(80亿参数规模)在GSM8K基准上达到91%的准确率。我们发现这一趋势具有普遍性:在AIME、AMC和MATH500等更具挑战性的学习推理基准上,仅需训练更少的参数,即可恢复超过90%的性能提升。值得注意的是,仅通过强化学习(RL)才能实现如此优异的性能;若采用监督微调(SFT)训练,则需要更大的参数更新才能达到相近效果。
一句话总结
来自 Meta FAIR、康奈尔大学和卡内基梅隆大学的研究人员提出了 TinyLoRA,通过强化学习(RL)仅用 13 个训练参数即可在 8B 参数的 Qwen2.5 模型上实现推理能力,在 GSM8K 上达到 91% 的准确率。该方法利用 RL 更新的信息密集特性,不同于监督微调(SFT),并将低秩适配扩展到接近零参数的极端场景。
主要贡献
- TinyLoRA 通过将低秩适配器扩展到秩小于 1 的范围,仅需 13 个训练参数即可在大型语言模型中实现有效推理,在 Qwen2.5-8B 上通过强化学习达到 GSM8K 91% 的准确率。
- 该方法在 AIME 和 MATH500 等具有挑战性的基准测试中表现出一致的高效性,在训练参数比传统方法少 1000 倍的情况下仍能恢复 90% 的性能增益,但仅在使用 RL 时有效——监督微调无法实现类似效果。
- 实验结果表明,通过 RL 训练的大型模型只需极小的参数更新即可达到高性能,揭示推理能力可在小于 1KB 的更新规模下被解锁,这一规模此前被认为不足。
引言
作者利用强化学习证明,大型语言模型可以通过极少量参数(某些情况下仅 13 个可训练参数)学习复杂的推理任务。以往的低秩适配方法(如 LoRA)通常在 10K 至 10M 参数规模下运行,难以在低于模型维度的规模下扩展,限制了其在极端参数约束下的效率。他们提出的 TinyLoRA 方法通过利用过参数化模型在 RL 下固有的低内在维度性,实现了千字节以下规模的有效适配,性能优于监督微调(后者需 100–1000 倍更多参数才能达到同等效果)。他们的工作表明,RL 而非 SFT 才能解锁这种极端效率——尤其在应用于大型主干模型时,挑战了“需要多少参数更新才能教会模型推理”的传统假设。
方法
作者基于低秩适配技术构建了一个参数高效的微调框架,提出 TinyLoRA 方法,以大幅减少可训练参数数量,同时保持模型性能。核心思想源于一个观察:即使像 LoRA-XS 这样的极低秩适配方法,每个模块仍至少需要一个参数,当扩展到大型 Transformer 架构的多层和注意力/MLP 组件时,这一开销变得不可接受。
TinyLoRA 通过将 LoRA-XS 中的可训练矩阵 R∈Rr×r 替换为一个低维可训练向量 v∈Ru,并通过固定随机张量 P∈Ru×r×r 投影实现低秩更新。更新后的权重矩阵为:
W′=W+UΣ(i=1∑uviPi)V⊤其中 U,Σ,V 由原始冻结权重矩阵 W 的截断 SVD 得到。该公式允许每个模块仅用 u 个可训练参数进行适配,与模型宽度 d 或秩 r 无关。
为进一步减少参数数量,作者在模块间实现权重共享。在 LLaMA-3 等标准 Transformer 架构中,LoRA 通常每层应用于七个不同模块(注意力中的查询、键、值、输出;MLP 中的上、下、门)。若不共享,即使 u=1,80 层模型也将产生 560 个参数。通过在所有模块间共享向量 v(无论是在单层内还是整个模型中),总可训练参数数量缩放为 O(nmu/ntie),其中 ntie 是共享同一个 v 的模块数量。当完全共享权重(ntie=nm)时,整个模型仅需 u 个参数即可微调——甚至可能仅需 1 个参数。
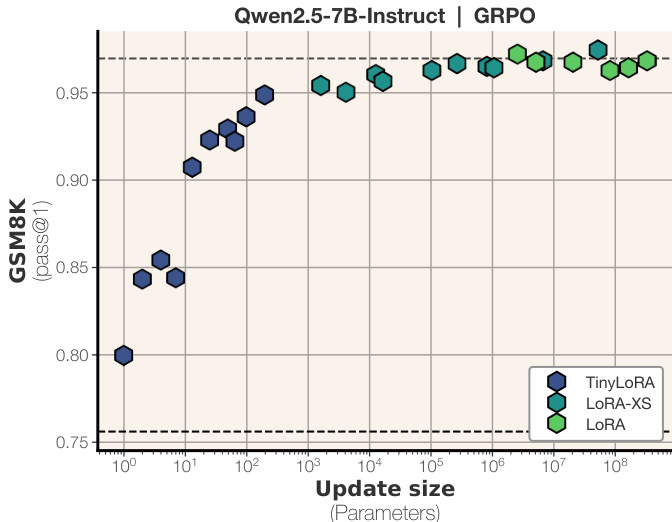
请参阅每层参数使用对比图,该图说明了在不同秩、投影维度和权重共享配置下,TinyLoRA 相较于 LoRA 和 LoRA-XS 如何减少可训练参数。
实验
- 强化学习(RL)相比监督微调(SFT)能实现更小的模型更新,仅需 13 个参数即可实现强大的数学推理性能。
- TinyLoRA 作为一种超低秩变体,可平滑扩展至仅 1 个训练参数,并在 GSM8K 上用不足 100 个参数恢复 95% 的全微调性能。
- 基于 RL 的训练(使用 GRPO)在低参数场景下效果独特;SFT 无法在相似更新规模下匹配性能,表明 RL 产生的更新信息更密集。
- 性能随模型规模提升:如 Qwen-2.5-7B 等更大模型用更少的绝对参数即可接近完整性能,暗示万亿规模模型可能仅需极小更新即可训练。
- 在小更新规模下,Qwen 模型优于 LLaMA,可能源于架构或预训练差异,达到同等增益仅需约 1/10 的参数。
- 参数共享策略至关重要:按深度分块共享优于按模块类型结构共享;尽管体积更大,fp32 精度优于 bf16/float16。
- 消融实验显示,冻结秩越高收益越递减;最优 TinyLoRA 设计优先最大化每模块表达能力(更高的 u),再增加参数共享(n_tie)。
- 当前发现仅限于数学推理任务;在科学或创意写作等其他领域的泛化能力尚未验证。
作者使用强化学习结合 TinyLoRA 在数学推理任务上微调 Qwen 模型,仅用 13 至 196 个参数即达到接近全微调的性能。结果表明,较小的参数更新在 RL 下远比监督微调更有效,尤其对于大型模型,其仅需极少参数变动即可达到高准确率。性能随更新规模平滑提升,且 Qwen 模型在低参数数量下始终优于其他模型,表明预训练差异可能促成了其高效性。