Command Palette
Search for a command to run...
长度无偏序列策略优化:揭示与控制RLVR中的响应长度变异
长度无偏序列策略优化:揭示与控制RLVR中的响应长度变异
Fanfan Liu Youyang Yin Peng Shi Siqi Yang Zhixiong Zeng Haibo Qiu
摘要
近期,强化学习结合可验证奖励(Reinforcement Learning with Verifiable Rewards, RLVR)在大型语言模型(Large Language Models, LLMs)与视觉-语言模型(Vision-Language Models, VLMs)中的应用,已在提升复杂任务推理能力方面展现出显著成效。在RLVR训练过程中,响应长度的增加通常被视为推动推理能力提升的关键因素。然而,不同RLVR算法在训练过程中响应长度的变化模式存在显著差异。为深入揭示这一现象的根本原因,本文对主流RLVR算法的组成部分进行了系统性分析,提出了关于影响响应长度因素的理论解释,并通过大量实验验证了该理论的有效性。基于上述理论发现,本文提出一种新型优化算法——无长度偏置序列策略优化(Length-Unbiased Sequence Policy Optimization, LUSPO)。该方法针对组序列策略优化(Group Sequence Policy Optimization, GSPO)中存在的长度偏置问题进行了修正,使其损失函数在响应长度上保持无偏性,从而有效缓解了响应长度坍缩(response length collapse)的问题。我们在多个数学推理基准测试及多模态推理场景中开展了广泛实验,结果表明,LUSPO在各项任务中均持续取得优于现有方法的性能表现。实证结果充分证明,LUSPO相较于GRPO、GSPO等现有方法,是一种新颖且处于领先水平的优化策略。
一句话总结
美团的研究人员提出了LUSPO,一种无长度偏差的RLVR算法,可纠正GSPO的响应长度偏差,使大语言模型和视觉语言模型在数学和多模态任务中实现稳定的推理能力增长,且在无长度崩溃的情况下优于GRPO和GSPO。
主要贡献
- 我们识别并从理论上解释了GRPO和GSPO在RLVR训练中如何引入长度偏差:GSPO使模型偏向更短的响应,从而损害推理性能。
- 我们提出了LUSPO,一种无长度偏差的策略优化方法,通过按响应长度缩放序列损失来消除该偏差,从而实现稳定训练并加速推理深度增长。
- 在AIME24、MathVista和MathVision等基准测试中,密集模型和MoE模型的实证结果表明,LUSPO优于GRPO和GSPO,在推理任务上最高可提升6.9%的准确率。
引言
作者利用可验证奖励强化学习(RLVR)来提升大语言模型和视觉语言模型的推理能力,其中响应长度通常与推理深度相关。先前的方法如GRPO和GSPO存在隐式长度偏差:GRPO惩罚更长的正确响应,而GSPO的序列级裁剪通过不成比例地抑制负样本加剧了偏差,导致训练过程中响应崩溃。为解决此问题,他们提出了长度无偏序列策略优化(LUSPO),通过按响应长度缩放每个序列的损失来中和偏差。LUSPO在密集模型和MoE模型中稳定训练,加速响应长度增长,并在数学和多模态基准测试中提高准确率,无需架构更改。
数据集
- 作者使用两个主要数据集:DAPO-MATH-17K用于训练主模型,ViRL39K用于训练视觉语言(VL)模型。
- 两个数据集均来源于近期学术工作(Yu等,2025;Wang等,2025),专注于科学问题解决,尤其侧重数学和逻辑。
- 这些数据集作为核心评估基准,因其严谨性及可扩展至其他领域而被选中。
- 本节未提供子集规模、过滤规则或处理步骤的进一步细节。
方法
作者采用策略优化框架处理自回归语言模型,将模型视为策略 πθ,在查询 x 条件下生成响应 y。每个响应由验证器评估并赋予标量奖励 r(x,y),作为强化学习更新的基础。核心创新在于设计基于组的策略优化目标,通过比较每个查询的多个响应计算相对优势,从而稳定训练并减少方差。
基础方法“组相对策略优化”(GRPO)为每个查询从旧策略 πθold 中采样一组 G 个响应,计算其奖励,并构建包含裁剪重要性采样权重的词元级目标。词元 yi,t 的重要性比率 wi,t(θ) 定义为当前策略与旧策略概率的比值,而优势 Ai,t 在响应 yi 的所有词元间共享,并相对于组内奖励的均值和标准差进行归一化。该设计鼓励模型偏好优于组平均值的响应。
在此基础上,“组序列策略优化”(GSPO)将词元级重要性权重替换为序列级对应项 si(θ),定义为整个响应中词元级比率的几何平均值。这更自然地与序列级奖励对齐,并为裁剪提供理论基础。GSPO目标保留基于组的优势估计,但直接将序列级重要性比率应用于优势,简化梯度计算并提高奖励信号一致性。
然而,GRPO和GSPO均表现出响应长度偏差:较短响应在损失中获得更高的每词元权重,导致模型偏好简洁性,尤其在GSPO的序列级裁剪机制下更为明显。为解决此问题,作者引入“长度无偏序列策略优化”(LUSPO),通过按每个序列自身的长度 ∣yi∣ 缩放其对损失的贡献。这一简单修改确保较长响应不会因长度而受罚,从而消除GSPO固有的梯度偏差。
梯度分析证实,LUSPO目标产生的梯度表达式中,长度归一化因子相互抵消,最终仅剩由序列级优势和重要性比率加权的词元级策略梯度之和。相比之下,GSPO梯度保留 1/∣yi∣ 因子,引入长度依赖缩放。这一理论洞察验证了LUSPO设计作为对长度偏差的原理性修正。
训练期间,奖励函数结合三个部分:准确性(Raccuracy∈{0,1})、格式符合度(Rformat∈{0,0.5})以及对过长响应的惩罚 Roverlong(y),后者对超过缓冲长度 Lbuffer 的响应按最大允许长度 Lmax 线性惩罚。该复合奖励鼓励正确性与简洁性,同时保持对提示要求的结构合规性。
实验
- LUSPO在密集模型、MoE模型和视觉语言模型中始终优于GSPO和GRPO,在纯文本和多模态基准测试中均表现出强大的泛化能力。
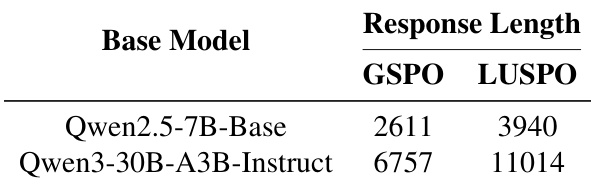
- LUSPO缓解了GSPO的长度偏差,使训练期间响应长度显著更长且更稳定,从而增强探索能力和复杂推理。
- 使用LUSPO训练的模型获得更高的准确率奖励和更好的验证分数,表明其学习和泛化能力提升而非过拟合。
- 消融研究证实LUSPO在不同数据集上的鲁棒性,即使训练数据中不存在长度崩溃,仍保持优越性能。
作者在多模态基准测试中使用Qwen2.5-VL-7B-Instruct评估LUSPO与GRPO和GSPO,显示在各项任务中持续性能提升。LUSPO在LogicVista上比GSPO最高提升6.0%,在WeMath上提升5.1%,同时训练期间保持更长的响应长度。这些结果表明LUSPO通过缓解GSPO固有的长度偏差,在视觉语言设置中具有更优的泛化能力。

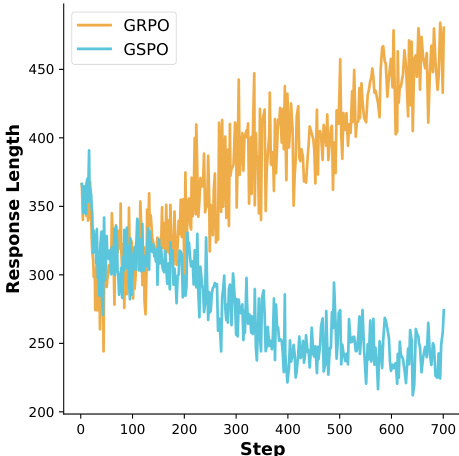
作者使用LUSPO训练密集模型和MoE模型,观察到LUSPO在各类模型中生成的响应长度均显著长于GSPO。响应长度增加与验证基准测试中更好的性能相关,表明LUSPO缓解了GSPO固有的长度偏差。结果表明,LUSPO通过在训练期间支持更广泛的探索和复杂推理,提升了模型能力。
作者在多模态基准测试中使用Qwen2.5-VL-7B-Instruct评估LUSPO与GSPO,显示在所有任务中持续性能提升。LUSPO在特定基准测试上比GSPO最高提升6.0%,平均提升2.3分。这些结果凸显了LUSPO在视觉语言设置中相比基线的优越泛化能力。

作者使用LUSPO训练密集模型和MoE模型,在多个纯文本基准测试中持续优于GSPO。结果表明,LUSPO不仅提高平均分数,还在AIME25和MATH500等具有挑战性的任务上实现更大绝对提升,表明更强的泛化能力。在MoE模型中,LUSPO在AIME基准测试上的性能相比GSPO显著提升。