Command Palette
Search for a command to run...
上下文强制:基于长上下文的一致性自回归视频生成
上下文强制:基于长上下文的一致性自回归视频生成
Shuo Chen Cong Wei Sun Sun Ping Nie Kai Zhou Ge Zhang Ming-Hsuan Yang Wenhu Chen
摘要
近期实现实时长视频生成的方法通常采用流式微调策略,试图通过一个短上下文(无记忆)的教师模型来训练具备长上下文能力的学生模型。在这些框架中,学生模型能够执行长时间的生成推演,但其训练监督信号仅来自局限于5秒短窗口的教师模型。这种结构上的不匹配导致了严重的师生不一致问题:由于教师模型无法访问长期历史信息,难以指导学生模型捕捉全局时间依赖关系,从而实质上限制了学生模型的上下文长度。为解决这一问题,我们提出一种名为上下文强制(Context Forcing)的新框架,该框架通过具备长上下文能力的教师模型来训练长上下文学生模型。通过确保教师模型能够感知完整的生成历史,我们有效消除了监督信号的不匹配,从而实现对具备长期一致性能力模型的稳定训练。为使该方法在极长生成时长(如2分钟)下具备计算可行性,我们引入了一种上下文管理机制,将线性增长的上下文结构重构为慢-快记忆架构(Slow-Fast Memory),显著降低了视觉内容的冗余度。大量实验结果表明,我们的方法可实现超过20秒的有效上下文长度——相较当前最先进方法(如LongLive和Infinite-RoPE)提升了2至10倍。借助这一扩展的上下文能力,Context Forcing在长时间生成过程中显著保持了更优的一致性表现,在多种长视频评估指标上均超越了现有最先进基线模型。
一句话总结
来自加州大学默塞德分校和清华大学的陈烁、魏聪等人提出了 Context Forcing 框架,利用长上下文教师模型训练学生模型,实现 20 秒以上的视频生成,并通过 Slow-Fast Memory 机制克服遗忘漂移问题,在长期一致性方面优于 LongLive 和 Infinite-RoPE。
主要贡献
- 我们识别并解决了长视频生成中学生-教师模型的关键不匹配问题:短上下文教师无法监督长上下文学生学习全局时间依赖关系。为此,我们引入了 Context Forcing——一种使用知晓完整生成历史的长上下文教师训练学生的框架。
- 为支持极端时长(如 2 分钟)的高效计算训练,我们设计了 Slow-Fast Memory 架构,通过减少视觉冗余压缩线性增长的上下文,使模型在 20+ 秒有效上下文下稳定训练与推理。
- 在长视频基准测试中,Context Forcing 的可用上下文长度比 LongLive 和 Infinite-RoPE 等最先进方法长 2–10 倍,显著提升长期一致性,并在关键时间连贯性指标上优于基线方法。
引言
作者利用因果视频扩散模型解决生成长时、时间一致视频的挑战——这对数字叙事和专业剪辑等应用至关重要,而现有方法常因遗忘历史上下文或误差累积导致漂移。现有方法依赖短上下文教师训练长上下文学生,造成不匹配,限制了可学习的时间依赖性,并迫使在记忆与稳定性之间权衡。其主要贡献是 Context Forcing,该框架使用长上下文教师训练长上下文学生,消除此不匹配,通过 Slow-Fast Memory 架构压缩冗余视觉信息同时保持全局一致性,实现 20+ 秒的稳健生成。
方法
作者在因果自回归框架内采用两阶段课程训练,构建可维持长时间一致性视频扩散模型。整体目标是最小化学生模型诱导分布 pθ(X1:N) 与真实数据分布 pdata(X1:N) 之间的全局 KL 散度,其中 N 跨越数十至数百秒。直接优化该全局目标计算不可行,作者将其分解为局部动力学 Llocal 和全局延续动力学 Lcontext,实现可处理的分阶段训练过程。
第一阶段,学生通过最小化 Llocal 进行预热,使短视频窗口 X1:k(通常 1–5 秒)的分布与高质量教师分布 pT(X1:k) 对齐。通过分布匹配蒸馏(DMD)实现,其中梯度通过学生与教师模型在扩散帧上的分数匹配估算。该阶段确保学生生成高保真短序列,为后续阶段提供稳定上下文。
第二阶段针对 Lcontext,强制学生延续分布 pθ(Xk+1:N∣X1:k) 与真实数据延续 pdata(Xk+1:N∣X1:k) 对齐。由于任意学生生成上下文的真实数据延续不可获取,作者引入预训练的上下文教师 T,提供可靠代理 pT(Xk+1:N∣X1:k)。这基于两个假设:(1)当条件上下文接近真实数据流形时,教师保持准确;(2)第一阶段确保学生生成轨迹保持在该可靠区域内。由此得到的上下文 DMD(CDMD)目标使用条件分数梯度估计器优化,学生与教师分数均在相同学生生成上下文上计算,缓解暴露偏差。
为处理长上下文的计算负担,作者设计了上下文管理系统,将 KV 缓存组织为三个功能组件:注意力沉降区、慢速内存和快速内存。注意力沉降区保留初始标记以稳定注意力,快速内存作为滚动 FIFO 队列用于即时局部上下文。慢速内存通过基于惊奇度的合并策略存储高熵关键帧:若新标记 xt 的键向量 kt 与前一标记键 kt−1 的相似度低于阈值 τ,则将其晋升至慢速内存,确保仅保留显著时间过渡。该架构在不增加线性内存或注意力成本下实现高效上下文保留。
请参考框架图,该图说明了从短上下文到长上下文训练的演变及内存管理。图中展示了学生如何通过教师监督和结构化内存系统逐步学习生成更长序列。内存组件动态更新:快速内存滑动通过近期帧,慢速内存将显著事件压缩至固定大小缓冲区。对所有标记应用有界位置编码,将其 RoPE 索引限制在固定范围内,无论生成步骤如何,从而稳定长序列注意力。
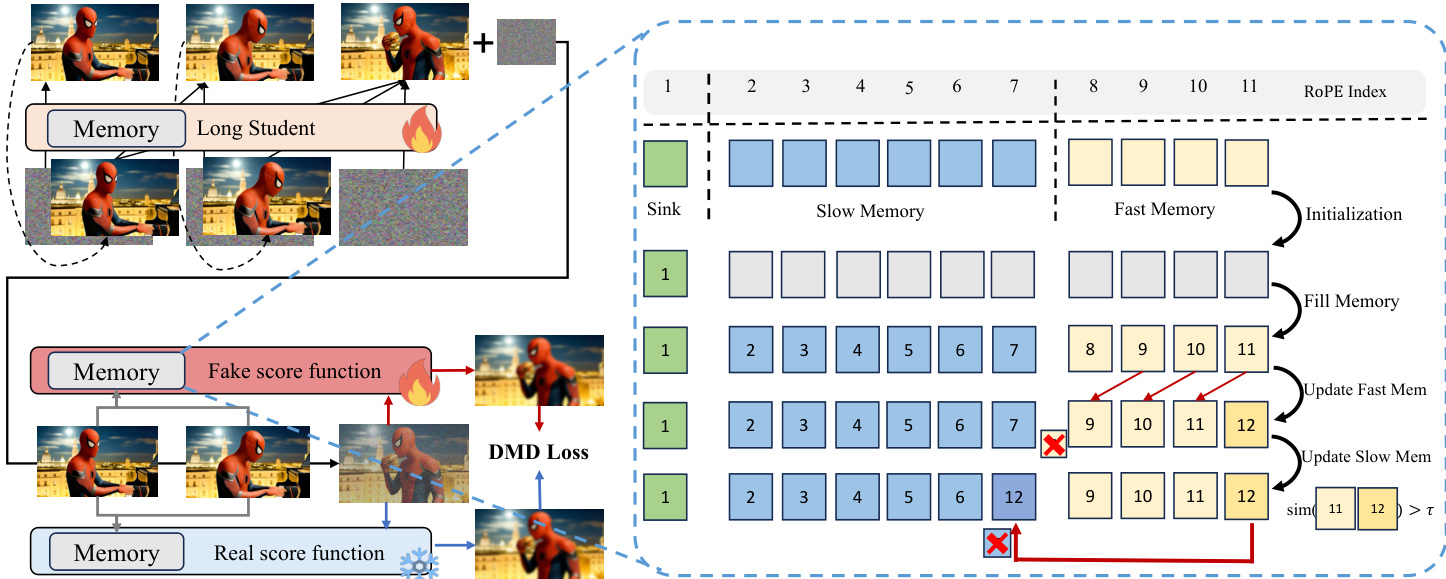
训练过程进一步结合长自展开课程,上下文范围 k 随训练步骤线性增长,逐步暴露模型于长程依赖。清洁上下文策略确保上下文帧 X1:k 完全去噪,而目标帧 Xk+1:N 通过随机时间步选择监督,保持所有扩散步骤的梯度覆盖。为增强上下文教师的鲁棒性,作者采用误差回收微调,在训练中向教师上下文注入真实累积误差,确保其在推理时能纠正学生漂移。
实验
- 鲁棒上下文教师成功从学生生成上下文生成连贯视频延续,验证其在 10 秒序列中维持长期一致性的能力。
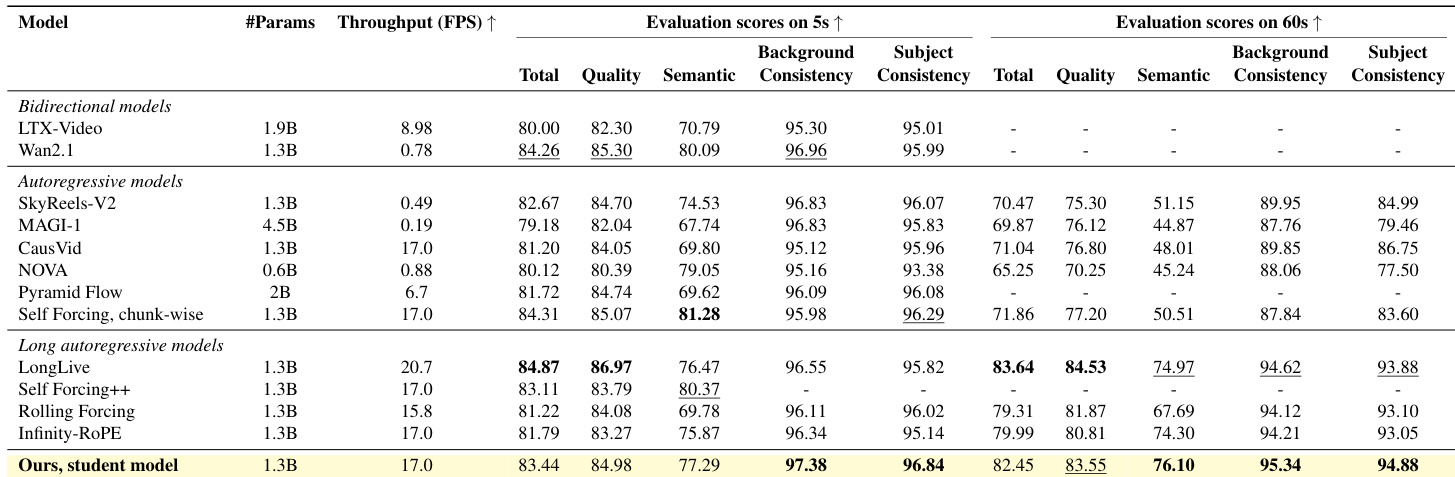
- 该方法在短视频生成(5 秒)上表现具有竞争力,而在 60 秒生成中显著优于基线,尤其在长时间内保持主体与背景一致性。
- 消融研究确认,基于相似度的慢速内存采样、上下文 DMD 蒸馏和有界位置编码各自对维持长视频语义与时间一致性至关重要。
- 误差回收微调增强上下文教师对累积生成误差的鲁棒性,带来更干净的展开和更优的蒸馏质量。
- 与 LongLive 及其他长视频基线相比,所提方法避免突然场景重置和循环运动伪影,尽管定量分数相当,但表现出更优的定性稳定性。
作者评估了其视频生成系统的消融组件,显示完整方法优于缺少上下文蒸馏或有界位置编码等关键机制的变体。结果表明,基于相似度的慢速内存采样和有界位置编码显著提升长序列中的背景与主体一致性。完整模型获得最高综合得分,证实其架构选择在维持时间一致性上的协同有效性。

作者使用鲁棒上下文教师与学生框架生成长视频,在 DINOv2、CLIP-F 和 CLIP-T 分数衡量下实现 60 秒序列的高一致性。结果表明,其方法在维持主体与背景稳定性方面优于 FramePack、LongLive 和 Infinity-RoPE 等基线,尤其在 20 秒后表现更佳。消融研究确认,关键组件——包括基于相似度的内存采样、上下文蒸馏和有界位置编码——对维持长期一致性至关重要。

作者采用两阶段训练方法与鲁棒上下文教师实现长视频生成,在短序列与长序列中均实现高一致性。结果表明,其学生模型在 60 秒视频的背景与主体一致性上优于多数基线,尤其擅长维持随时间推移的稳定语义与结构。消融研究确认,基于相似度的内存采样与有界位置编码等关键组件对维持长期一致性至关重要。