Command Palette
Search for a command to run...
何时记忆,何时停止:面向长上下文推理的门控循环记忆
何时记忆,何时停止:面向长上下文推理的门控循环记忆
Leheng Sheng Yongtao Zhang Wenchang Ma Yaorui Shi Ting Huang Xiang Wang An Zhang Ke Shen Tat-Seng Chua
摘要
尽管在长上下文上的推理对于多种现实应用场景至关重要,大型语言模型(LLMs)在处理长文本时仍面临显著挑战,其性能会随着上下文长度的增加而显著下降。近期工作 MemAgent 尝试通过类似循环神经网络(RNN)的迭代方式,将上下文分块处理,并持续更新一个文本记忆以支持最终回答。然而,这种简单的循环记忆更新机制存在两个关键缺陷:(i)记忆内容可能迅速膨胀,因为模型会在缺乏有效证据的文本块上仍 indiscriminately(无差别地)进行更新;(ii)循环过程缺乏明确的退出机制,导致即使已收集到足够证据,仍会继续执行不必要的计算。为解决上述问题,我们提出 GRU-Mem,该方法引入两个受文本控制的门控机制,以实现更稳定且高效的长上下文推理。具体而言,在 GRU-Mem 中,记忆仅在更新门(update gate)开启时才进行更新,而一旦退出门(exit gate)被激活,循环过程将立即终止。为赋予模型上述行为能力,我们在端到端强化学习框架中引入两个奖励信号:rupdate 用于奖励正确的记忆更新行为,rexit 用于奖励恰当的退出行为。在多种长上下文推理任务上的实验结果表明,GRU-Mem 具有显著的性能优势与效率提升,其推理速度相较原始 MemAgent 最高可提升 400%,同时在多数任务上表现更优。
一句话总结
来自字节跳动Seed、新加坡国立大学和中国科学技术大学的研究人员提出了GRU-Mem,这是一种通过受控更新和早期退出稳定大语言模型长上下文推理的门控记忆代理,在推理速度上比MemAgent快达400%,同时减少内存膨胀和冗余计算。
主要贡献
- GRU-Mem通过引入两个文本控制的门——更新门(仅在相关文本块上更新以防止内存爆炸)和退出门(一旦收集到足够证据即停止计算)——解决了MemAgent等先前循环记忆方法的关键局限。
- 该模型通过强化学习端到端训练,使用两种不同的奖励信号 rupdate 和 rexit,明确指导代理学习何时更新记忆、何时终止循环。
- 在长上下文问答任务上评估,GRU-Mem优于原始MemAgent,同时实现高达400%的推理加速,展现出更高的准确性和计算效率。
引言
作者利用循环记忆架构解决长上下文推理问题,其中大语言模型需在数百万token中定位稀疏证据——这一挑战被称为“大海捞针”问题。先前工作如MemAgent逐块处理上下文,但存在内存无控制增长和无早期退出的问题,即使已找到足够证据仍浪费计算资源。他们的主要贡献GRU-Mem引入两个文本控制的门——更新门用于选择性刷新记忆,退出门用于提前终止处理——通过端到端强化学习训练,每个行为有独立奖励信号。这使得准确率更高,推理速度比原始MemAgent快达400%。
方法
作者采用门控循环记忆框架GRU-Mem,以解决原始循环长上下文推理中存在的不稳定性和低效性。核心创新在于为记忆代理增加两个文本控制的二值门——更新门(UG)和退出门(EG)——动态调节记忆演化和工作流终止。该设计借鉴了GRU中的门控机制,旨在缓解内存爆炸并在收集到足够证据时实现早期退出。
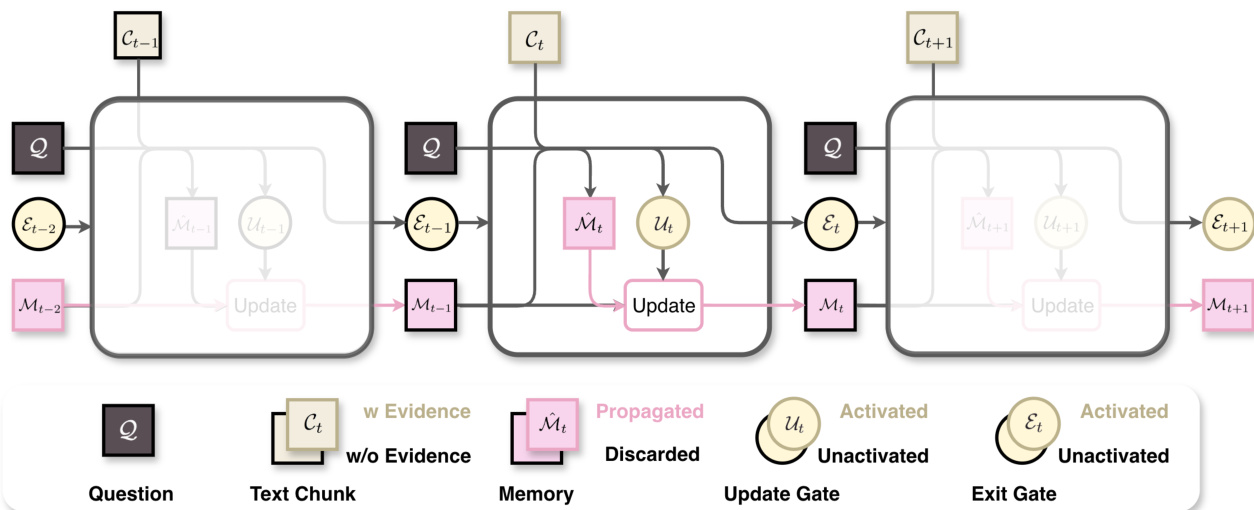
工作流首先将长上下文 C 拆分为 T 个固定大小的块 {C1,⋯,CT}。在每一步 t,记忆代理 ϕθ 在问题 Q、当前块 Ct 和前一记忆 Mt−1 的条件下,生成三个输出:候选记忆 M^t、更新门状态 Ut 和退出门状态 Et。形式化表示如下:
Ut,M^t,Et=ϕθ(Q,Ct,Mt−1).更新门决定是否覆盖记忆:若 Ut 为True,则 Mt←M^t;否则 Mt←Mt−1。退出门控制工作流是否继续:若 Et 为True,则循环终止,答案代理 ψθ 立即从 Mt 和 Q 生成最终答案 A^。这种选择性更新和条件终止对维持记忆稳定性和减少不必要计算至关重要。
请参阅框架图,图中展示了更新门如何丢弃无关候选记忆,以及退出门如何在遇到最后证据时停止处理,从而防止内存爆炸并避免冗余块处理。
为强制这种结构化行为,记忆代理被约束输出预定义格式。如提示规范所示,代理必须先在 <tool_call> 标签内推理,然后输出 yes 或 no 以激活或停用更新门,接着在 标签内输出候选记忆,最后输出 continue 或 end 以控制退出门。这种结构化输出确保可解析性,并在推理期间强制执行门控逻辑。
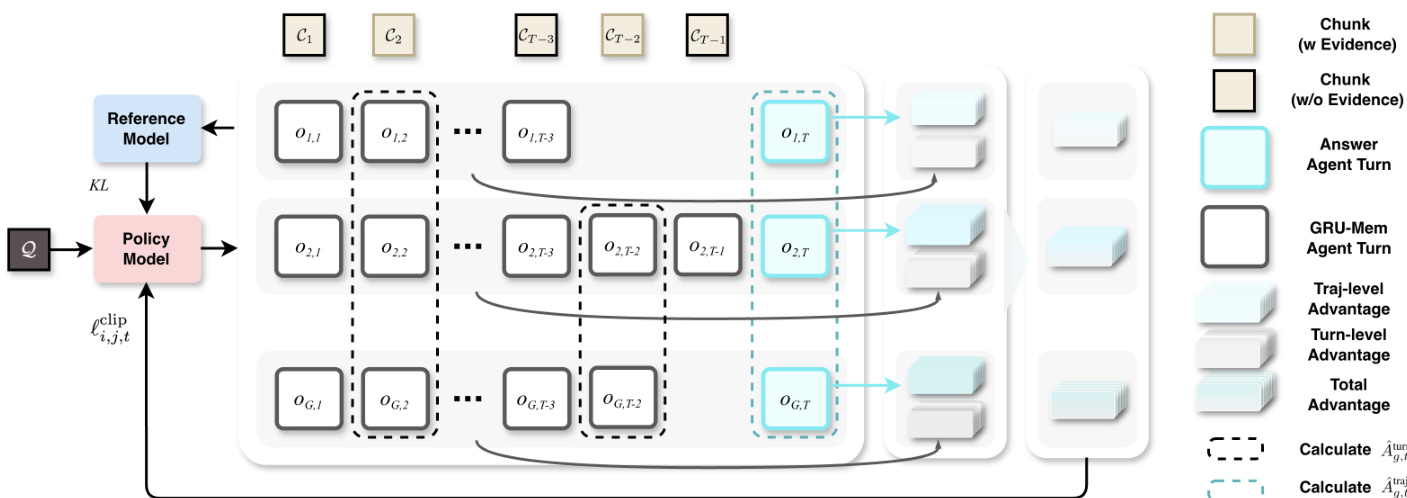
训练通过强化学习端到端进行,扩展了Multi-Conv DAPO算法。策略模型使用包含多个奖励信号的复合损失进行优化:结果奖励(答案正确性)、更新奖励(每轮门激活准确性)、退出奖励(在正确证据块终止)、格式奖励(遵守结构化输出)。优势计算解耦为轨迹级和回合级组件,结合超参数 α 平衡全局和局部优化信号。这种双重优势结构通过分别评估门决策在回合和轨迹层面的影响来稳定训练。
如优势计算图所示,策略模型从轨迹级优势(比较整个工作流)和回合级优势(比较每步门决策)接收反馈,从而实现对门控行为的细粒度控制。

在推理阶段,作者提供灵活性支持两种模式:带退出门(w EG)和不带退出门(w/o EG)。w EG模式在 Et 为True时提前终止,而w/o EG模式无论门状态如何均处理所有块,以适应需要完整上下文遍历的任务。这种双模式推理确保在不同长上下文推理场景中的适应性。
实验
- GRU-Mem在多样化的问答和NIAH任务中优于原始MemAgent,尤其在分布外和多键基准上,长上下文和较小模型尺寸下表现更稳定。
- GRU-Mem实现显著推理加速——借助早期退出最高可达400%——同时不牺牲准确性,得益于高效的内存管理和自适应终止。
- 更新门通过仅更新与证据相关的块抑制内存爆炸,退出门在早期发现证据时实现提前终止,提升在证据分布不均衡场景中的灵活性。
- 消融研究表明,α=0.9平衡更新准确性和奖励稳定性;强化学习训练进一步提升性能,尤其在更难任务中通过训练期间优化门控行为。
- 训练动态显示格式和退出行为快速学习,响应长度和退出偏差随时间稳定,模型学会精确更新和停止。
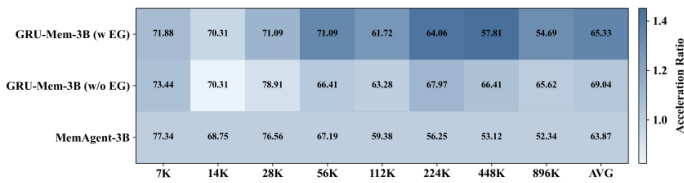
作者使用GRU-Mem在不同上下文长度下提升记忆代理性能和效率,显示在准确性和推理速度上持续优于MemAgent。结果表明GRU-Mem在分布外任务中保持强劲性能,无早期退出时推理速度最高快2倍,启用早期退出时加速更显著。该方法的门控机制有助于控制内存增长并实现及时终止,促进稳定高效的长上下文推理。
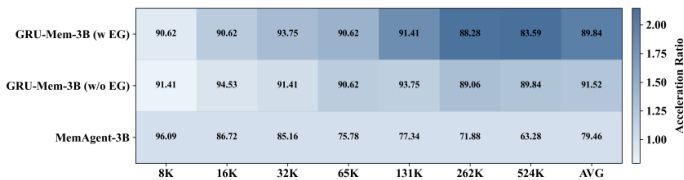
作者使用GRU-Mem在不同上下文长度下提升记忆代理性能和效率,显示在准确性和推理速度上持续优于MemAgent。结果表明GRU-Mem借助早期退出机制实现最高400%的推理加速,同时维持或提升任务性能,尤其在分布外和多键任务中。门控机制实现更选择性的内存更新和更早终止,减少计算开销而不牺牲准确性。
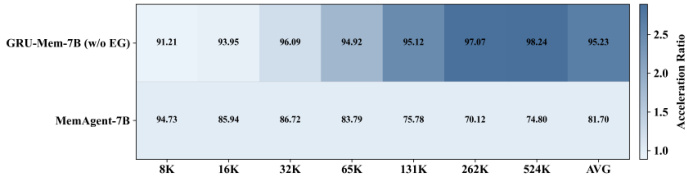
作者使用GRU-Mem在不同上下文长度下提升记忆代理性能和效率,显示在准确性和推理速度上持续优于MemAgent。结果表明GRU-Mem在不牺牲性能的情况下实现最高2倍的推理加速,尤其受益于其控制内存更新和早期退出决策的门控机制。即使上下文规模扩大,模型仍保持稳定性能,效率提升在更长长度下更显著。
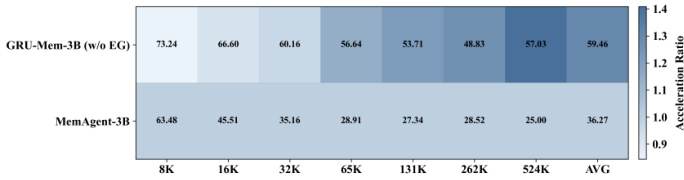
作者使用GRU-Mem在不同上下文长度下提升记忆代理性能和效率,显示在准确性和推理速度上持续优于MemAgent。结果表明,带早期退出的GRU-Mem实现最高4倍的推理加速,同时维持或提升任务性能,尤其在更长上下文中。随着上下文规模增加,效率增益更显著,表明其在长上下文推理任务中具备更好的可扩展性。
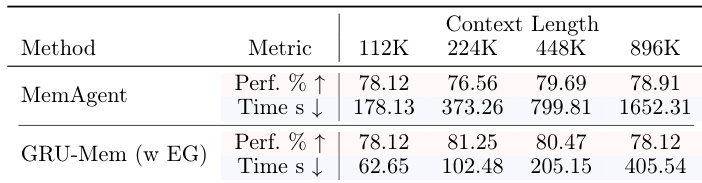
作者使用GRU-Mem在不同上下文长度下提升记忆代理性能和效率,显示在准确性和推理速度上持续优于MemAgent。结果表明GRU-Mem在分布外任务中保持更强性能,借助早期退出机制实现最高400%的推理加速,同时通过门控更新稳定内存增长。该方法在长上下文和证据分布不均衡场景中尤为有效,性能提升随上下文规模扩大而增强。