Command Palette
Search for a command to run...
PhyCritic:面向物理AI的多模态批评者模型
PhyCritic:面向物理AI的多模态批评者模型
Tianyi Xiong Shihao Wang Guilin Liu Yi Dong Ming Li Heng Huang Jan Kautz Zhiding Yu
摘要
随着大规模多模态模型的快速发展,可靠的任务评判与批评模型已成为开放式评估与偏好对齐的关键,能够为模型生成的回应提供成对偏好、数值评分以及解释性理由。然而,现有批评模型主要在通用视觉领域(如图像描述生成或视觉问答)中进行训练,导致涉及感知、因果推理与规划等物理智能任务的研究仍处于相对空白状态。为此,我们提出 PhyCritic——一种面向物理智能任务优化的多模态批评模型,其采用两阶段强化学习与视觉评估(RLVR)流程:第一阶段为物理技能预热阶段,旨在增强模型在物理导向感知与推理方面的能力;第二阶段为自指式批评微调,即批评模型在评估候选响应前,先生成自身预测作为内部参考,从而提升判断的稳定性与物理合理性。在涵盖物理任务与通用多模态评判基准的多项测试中,PhyCritic 在性能上显著优于开源基线模型;当作为策略模型使用时,其进一步提升了在物理情境下任务的感知与推理能力。
一句话总结
卡内基梅隆大学与 NVIDIA 的熊天一等人提出 PhyCritic,这是一种通过 RLVR 训练优化的多模态评判器,通过自指微调增强感知与推理能力,在物理与通用评判基准上超越基线模型,并在具身任务中提升策略表现。
主要贡献
- PhyCritic 通过引入两阶段 RLVR 流程解决多模态评判器缺乏物理感知评估的问题:首先预热物理推理能力,然后训练评判器在评判响应前先生成自身预测,从而提升稳定性与物理正确性。
- 该模型引入自指评判器微调,其内部预测将判断锚定于物理现实,相比在字幕或问答任务上训练的通用评判器,能更准确评估因果有效性与视觉对齐。
- 在 PhyCritic-Bench(基于 RoboVQA 和 BridgeData V2 等具身数据集构建的新基准)上评估,PhyCritic 超越开源基线模型,并在具身任务中作为策略模型部署时提升感知与推理能力。
引言
作者利用多模态评判模型应对物理 AI 中日益增长的可靠评估需求——系统需在现实环境中对感知、因果和行动进行推理。先前的评判器主要在通用视觉任务(如字幕或问答)上训练,缺乏物理感知,无法评估响应是否符合物理合理性、空间约束或因果序列。PhyCritic 引入两阶段 RLVR 流程:首先在物理推理任务上预热模型,然后微调其在评估候选响应前先生成自身具备物理感知的预测——从而构建自指、具身的判断过程。该方法提升了物理评估的稳定性与正确性,作者还发布了 PhyCritic-Bench——一个包含可验证物理推理任务的新基准,证明其在开源 7B/8B 模型中达到最先进水平。
数据集
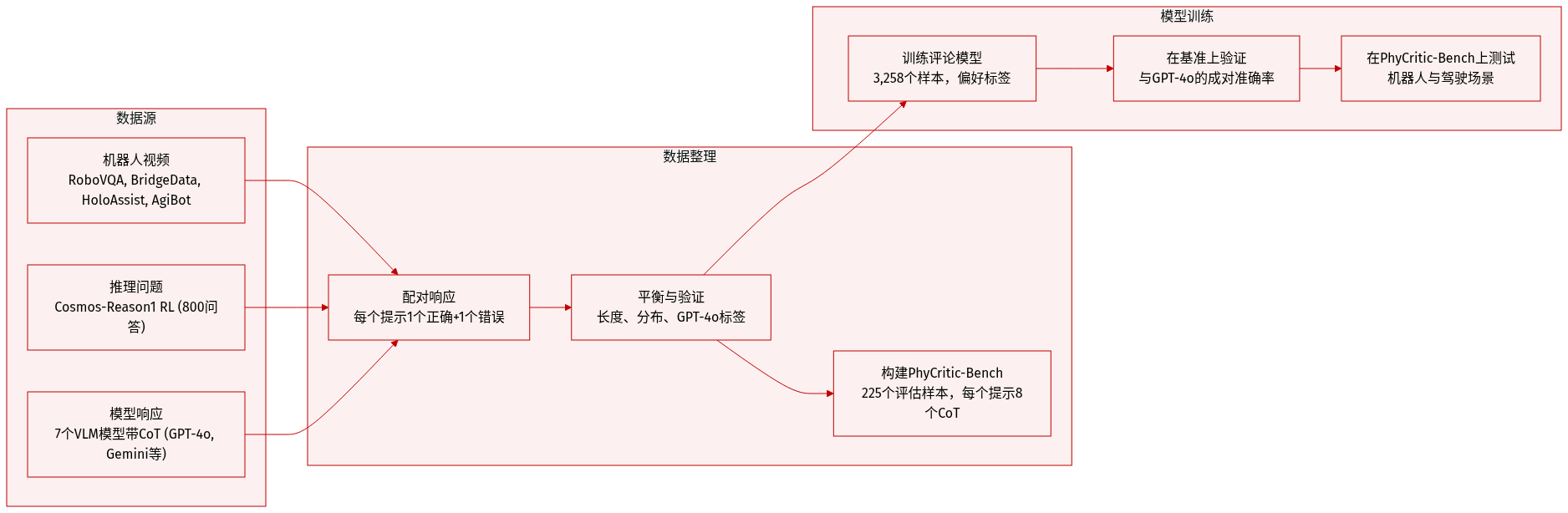
作者使用自定义的评判器训练数据集与新评估基准 PhyCritic-Bench,二者均针对物理 AI 推理任务构建。结构与用途如下:
-
数据集组成与来源
- 训练数据来自四个机器人/具身数据集:RoboVQA、Bridge-Data V2、HoloAssist 与 AgiBot World —— 覆盖第一/第三人称视角及操作任务(抓取、堆叠等),涵盖模拟与真实环境。
- 问题源自 Cosmos-Reason1 RL,提供 800 个高质量、推理密集型问答对。
- 模型响应由七个多模态模型生成:GPT-4o、Gemini-2.5-Flash、Qwen2.5-VL-72B、InternVL3-38B、Cosmos-Reason1-7B、Video-R1 与 MiMo-VL-7B —— 均使用思维链提示生成推理轨迹。
-
关键子集详情
- 训练集(3,258 个样本):每个样本为元组 (Q, L_A, L_B, A_Q, P),其中 Q 为多模态提示,L_A/L_B 为候选响应,A_Q 为真实答案,P 表示偏好响应。
- 响应配对为一个正确(经 GPT-4o 验证)与一个错误,然后按长度与分布平衡。
- PhyCritic-Bench(225 个样本):评估物理 AI 场景——机器人(RoboVQA、BridgeData V2、HoloAssist、AgiBot、RoboFail)与自动驾驶(LingoQA)。问题改编自 CosmosReason1-Bench。
- 每个评估实例为元组 (q, l_a, l_b, p),其中 p 为通过 GPT-4o 验证每提示 8 个 CoT 响应(一个正确,一个错误)分配的偏好标签。
-
数据使用方式
- 训练数据集用于训练评判模型,区分基于推理准确性与视觉对齐的高质量与低质量响应。
- PhyCritic-Bench 通过成对偏好准确率评估模型性能:模型选择必须匹配 GPT-4o 基于正确性的标签。
- 两个数据集均使用 GPT-4o 进行真实标注——通过与参考答案对比为响应分配二元偏好得分。
-
处理细节
- 所有模型响应均使用思维链提示生成。
- 响应对构造确保每个提示对应一个正确与一个错误答案。
- 训练数据在响应长度与分布上平衡。
- 未提及裁剪或元数据构建——重点是带偏好标签的多模态提示-响应元组。
方法
作者采用两阶段强化微调流程,使视觉语言模型具备物理具身的评判能力。该框架旨在首先培养基础物理推理,然后通过将判断锚定于自身内部预测,精炼模型评估竞争响应的能力。请参阅框架图以了解端到端训练流程概览。
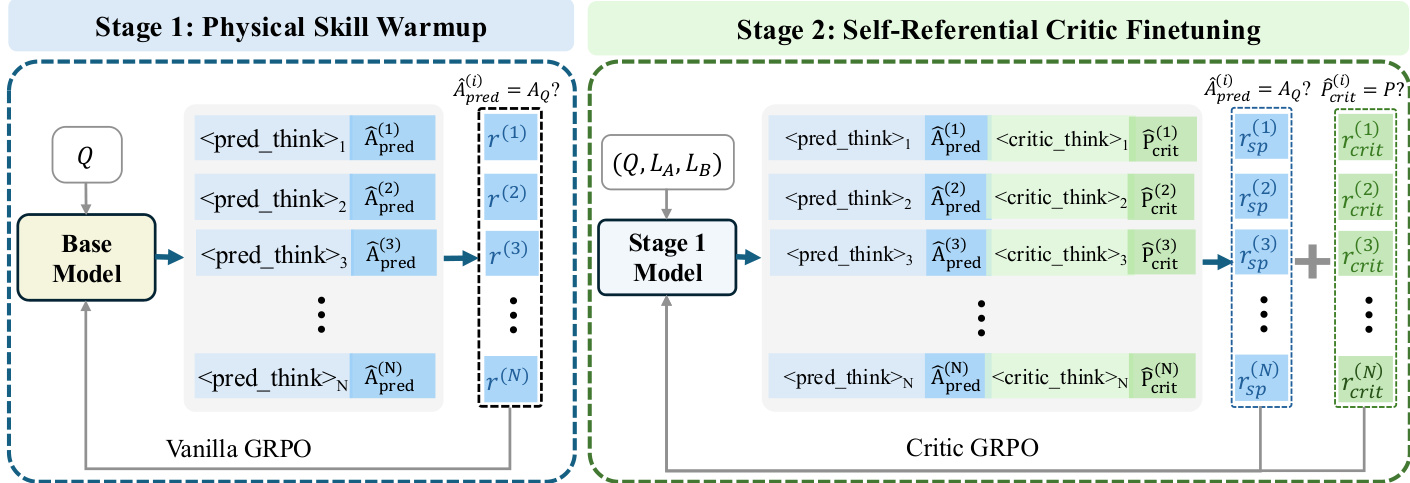
在第一阶段,称为物理技能预热,基础模型在可验证的问题-答案对 (Q,AQ) 数据集上使用标准强化学习设置进行微调。模型为每个问题 Q 生成自预测 A^pred,并获得二元准确性奖励:
r=I(A^pred(Q)=AQ)该阶段使用 Vanilla GRPO 优化策略,确保模型在参与评判任务前发展出可靠的物理推理能力。输出结构包括推理轨迹 <pred_think>,后接预测答案 A^pred,与真实答案对比评估。
第二阶段,自指评判器微调,在第一阶段模型基础上引入更复杂的任务:评估给定问题 Q 的两组模型响应 (LA,LB)。模型被提示先生成自身预测 A^pred,然后在两个响应间生成偏好判断 P^crit,明确指示其批评应基于自身预测。总奖励由准确性奖励 racc 与格式奖励 rform 组成:
rtotal=racc+rform∗αform准确性奖励是两部分的加权和:自预测奖励 rsp=I(A^pred=AQ) 与评判奖励 rcrit=I(P^crit(Q,LA,LB)=P)。这些鼓励模型既成为有能力的解题者,也成为可靠的评判者。格式奖励强制输出结构包含 <pred_think>、、