Command Palette
Search for a command to run...
GENIUS:生成式流体智能评估套件
GENIUS:生成式流体智能评估套件
摘要
统一多模态模型(Unified Multimodal Models, UMMs)在视觉生成任务中已取得显著进展。然而,现有评估基准主要侧重于“晶体智力”(Crystallized Intelligence)的衡量,即依赖于对已有知识与习得范式的回忆能力。这一取向忽视了“生成流体智力”(Generative Fluid Intelligence, GFI)——即在瞬时情境中归纳隐含模式、基于约束进行推理,并灵活适应新场景的能力。为系统评估这一关键能力,我们提出 GENIUS(GEN Fluid Intelligence Evaluation Suite),旨在建立对 GFI 的严谨评测体系。我们首次将 GFI 形式化为三种基本能力的综合:1)隐含模式的归纳能力(Inducing Implicit Patterns),例如推断个性化的视觉偏好;2)临时约束的执行能力(Executing Ad-hoc Constraints),例如可视化抽象隐喻;3)情境知识的适应能力(Adapting to Contextual Knowledge),例如模拟违背直觉的物理规律。这三项能力共同要求模型在完全依赖即时上下文的前提下解决新颖问题,而非依赖预存知识。我们对12种代表性模型的系统性评估表明,这些模型在上述任务中普遍存在显著性能短板。通过深入的诊断分析,我们揭示了这些失败的根本原因:并非生成能力不足,而是对上下文理解能力有限。为弥补这一差距,我们提出一种无需额外训练的注意力干预策略(training-free attention intervention),有效提升模型在动态推理任务中的表现。最终,GENIUS 建立起衡量生成流体智力的严格标准,推动该领域从“知识调用”向“动态、通用推理”迈进。相关数据集与代码将公开发布于:https://github.com/arctanxarc/GENIUS。
一句话总结
清华大学及合作团队提出 GENIUS,这是一个通过模式归纳、约束执行和上下文适应来评估多模态模型生成流体智力的基准;他们引入一种无需训练的注意力干预方法,以解决上下文理解不足的问题,推动动态推理能力超越静态知识回忆。
主要贡献
- 我们引入 GENIUS,首个专为评估多模态模型中生成流体智力(GFI)设计的基准套件,通过三个基本能力形式化 GFI:归纳隐式模式、执行临时约束、适应上下文知识,任务与静态知识解耦,以隔离动态推理能力。
- 我们对 12 个最先进模型的评估显示其在 GFI 任务中普遍存在缺陷,诊断分析表明失败源于上下文理解能力不足,而非生成能力薄弱,突显当前多模态模型在动态推理能力上的关键缺口。
- 为解决此问题,我们提出一种无需训练的注意力干预策略,通过增强对上下文规则的关注,提升模型在 GENIUS 任务上的表现,验证了我们的理论见解:注意力不平衡会削弱隐式上下文学习。
引言
作者基于 Cattell-Horn-Carroll 理论,将生成流体智力(GFI)定义为归纳模式、执行临时约束、适应新颖上下文知识的能力——这些能力对视觉生成中的真正通用智能至关重要。以往基准大多评估晶体智力(知识回忆),忽略 GFI,且缺乏正式定义、细粒度任务或失败模式的诊断分析。其主要贡献是 GENIUS,首个专为评估 GFI 设计的基准,涵盖 510 个专家策划样本,横跨三个维度,揭示即使顶级模型也因上下文理解能力不足而非生成能力薄弱而失败——并提出一种无需训练的注意力干预方法,提升各任务表现。
数据集

作者使用 GENIUS,一个旨在评估灵活智力(FI)的多模态基准,包含三个核心维度:隐式模式归纳、临时约束执行、上下文知识适应。每个维度包含新颖的专家策划任务,需视觉与文本模态紧密整合——缺少任一模态任务将无法求解。
-
隐式模式归纳 包含隐式模式生成:模型必须从交错的图文输入中推断未明示的风格偏好,并在生成中应用。仅依赖单一模态将导致失败——仅图像会导致特征混淆,仅文本则偏好未定义。
-
临时约束执行 包含两个任务:视觉约束生成与符号约束生成。模型必须在新颖、上下文定义的规则下推理(例如,“蓝色方块”表示“移除一个对象”,或函数 f 表示“融化一个对象”)。这些规则故意使用语义中性元素以测试抽象推理;缺失任一模态将破坏规则建立。
-
上下文知识适应 包含先验冲突生成(例如,“重量由颜色决定”)和多义生成(例如,将“绿色的手”解释为新手或肤色)。模型必须覆盖预训练知识或根据上下文解决歧义——若任一模态缺失则失败。
GENIUS 包含 3 个维度下的 5 项任务,总计 20 个子任务。数据集结构旨在测试动态推理、适应性与跨模态整合——未指定训练划分或混合比例,因其为纯评估基准。未提及裁剪或元数据构建;重点在于精心设计、依赖模态的测试案例。
方法
作者基于“上下文学习(ICL)作为隐式微调”的理论框架,分析并增强采用混合专家(MoE)Transformer 架构的 Bagel 模型的生成能力。其核心见解是:多模态生成过程中的 ICL 可数学形式化为对特定模型参数(即 Up 投影层和解码器块中的偏置项)的隐式梯度下降。这一理论基础源自模型的前向传播,揭示上下文标记诱导参数更新,从而引导生成轨迹。作者通过定理 4.1 形式化此关系,指出上下文输入 u 的扰动可通过 Up 和偏置参数的相应扰动补偿,使输出保持不变。该等价性表达为 LUp+ΔUp,b+Δb(u′,g)=LUp,b(u,g),其中扰动 ΔUp 和 Δb 明确由归一化注意力差异 δA 和注意力函数 A(u,g) 定义。
在此基础上,定理 4.2 进一步细化分析,推导出这些参数在迭代上下文标记处理过程中的梯度下降更新规则。作者表明 Up 和偏置参数按 Upi+1=Upi−h∇UpLi(Upi) 和 bi+1=bi−∇b(tr(δi⊤bi)) 演化,其中学习率 h 和损失函数 Li 由注意力机制输出导出。该理论分析揭示了引导微调(GFI)中的关键缺陷:上下文标记注意力分布不平衡导致噪声化、随机梯度更新,无法克服预训练先验。
为解决此问题,作者提出一种无需训练的注意力调整机制,旨在通过抑制无关“噪声”标记的影响,重新校准隐式梯度方向。该机制采用三阶段流水线。第一阶段为关键词提炼,模型被提示从上下文图像中提取任务关键视觉线索,生成一组区域特定关键词 K。此步骤由结构化提示模板引导,指示模型解析多模态指令并将每张图像映射至其特定角色——作为目标画布、特征来源或无关参考。提示强制采用严格 JSON 输出格式,确保精确、机器可读的关键词生成。

第二阶段为相关性映射,模型通过评估提炼关键词与视觉上下文标记的对齐度,计算语义相关性图 S。该图作为标记对有效梯度信号贡献的代理。最后,在偏置注入阶段,作者将空间偏置 F(S) 直接注入选定解码层和生成步骤的注意力 logits。调制后的注意力 logits A^l,h 计算为 A^l,h(i,j)=Al,h(i,j)+λ⋅F(Si),其中函数 F(⋅) 将相关性分数归一化为双极分布,有效放大信号标记的注意力权重并抑制噪声标记。最终注意力权重通过标准 Softmax 操作计算,确保噪声的梯度范数贡献呈指数级衰减。

该干预将隐式梯度从噪声化、信号加噪声组合转变为干净、信号主导的更新,如概念图所示。作者证明该方法可确定性引导优化轨迹,使模型克服预训练先验,实现更准确、符合指令的生成。整个过程无需修改模型权重,是一种轻量级、后处理增强现有多模态架构的方法。
实验
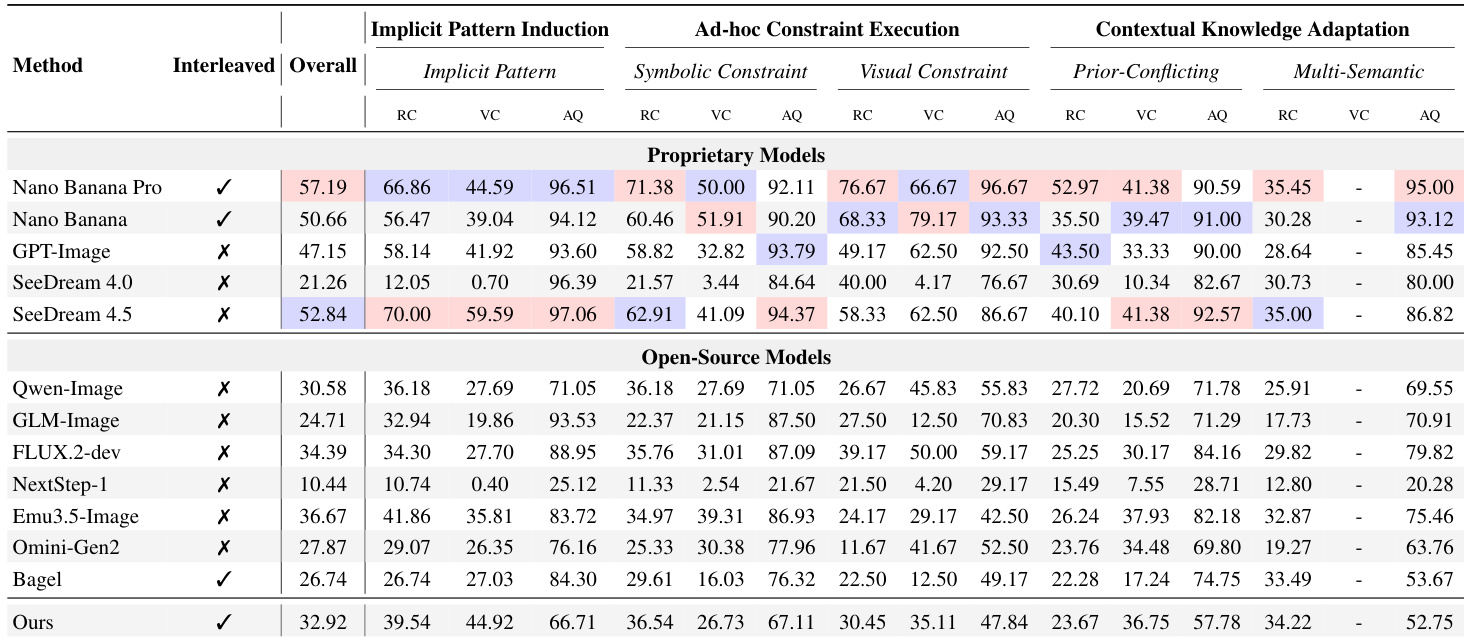
- 使用混合 LMM 框架(Gemini-3-Pro)评估 12 个模型,采用三项指标:规则遵守、视觉一致性、美学质量,基于人工策划提示确保严谨性。
- 包括 Nano Banana Pro 在内的最先进模型得分低于及格线,揭示尽管美学输出强,但流体智力存在根本性缺口。
- 模型在面对冲突或新颖规则时始终无法覆盖预训练先验,显示认知惯性而非适应性推理。
- 美学质量掩盖深层失败:模型生成视觉上合理的图像但违反逻辑或基于规则的约束,暴露对表面真实性的偏好而非上下文保真度。
- 推理时策略如预规划或后反思仅带来微小提升,表明架构在利用推理生成方面存在局限。
- 人工策划提示显著提升表现,尤其对更强模型,确认上下文理解至关重要——但缺乏稳健生成能力则不足。
- 将任务重构为 VQA 显示模型常理解指令但无法视觉执行,指向解码器效率中的“知而不能画”缺口。
- LMM 作为评估者验证显示与人工评分高度相关(r > 0.96),跨评估者一致性(Qwen2.5-VL-72B)确认结果反映模型内在缺陷而非评估者偏差。
- 注意力可视化揭示基线模型上下文处理噪声化、不聚焦;所提干预使注意力集中于关键标记,提升表现而无需参数更新。
- 上下文消融确认其必要性:移除上下文输入导致严重性能下降,尤其在需归纳推理或覆盖先验的任务中。
作者使用大型多模态模型作为评估者,评估 12 个图像生成模型在生成流体智力多个维度的表现,揭示即使顶级专有模型总体得分也低于 60%,且在规则遵守和上下文适应方面表现挣扎。结果显示模型理解指令的能力与其生成视觉准确输出的能力之间存在持续差距,美学质量常掩盖深层逻辑失败。改善注意力聚焦的干预措施带来可测量提升,表明上下文处理架构改进是提升生成适应性的关键。
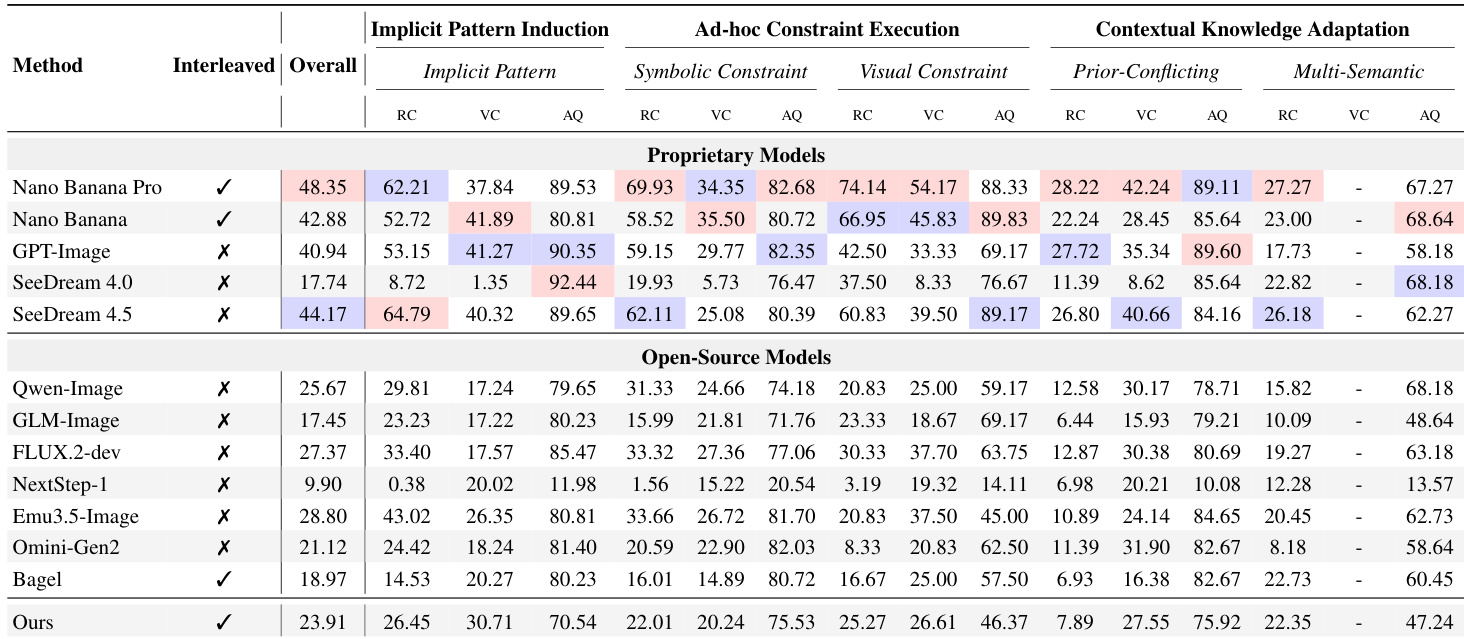
作者使用结构化评估框架,以大型多模态模型作为评估者,评估 12 个模型在生成流体智力任务中的表现,揭示即使顶级专有模型总体得分也低于 60%,因无法适应新颖规则和上下文。结果显示模型理解指令的能力与其生成视觉符合输出的能力之间存在持续差距,美学质量常掩盖深层逻辑失败。所提出的 GENIUS 基准引入多模态交错上下文和混合评估,暴露这些局限,确认当前架构在面对冲突或临时指令时难以覆盖预训练先验。
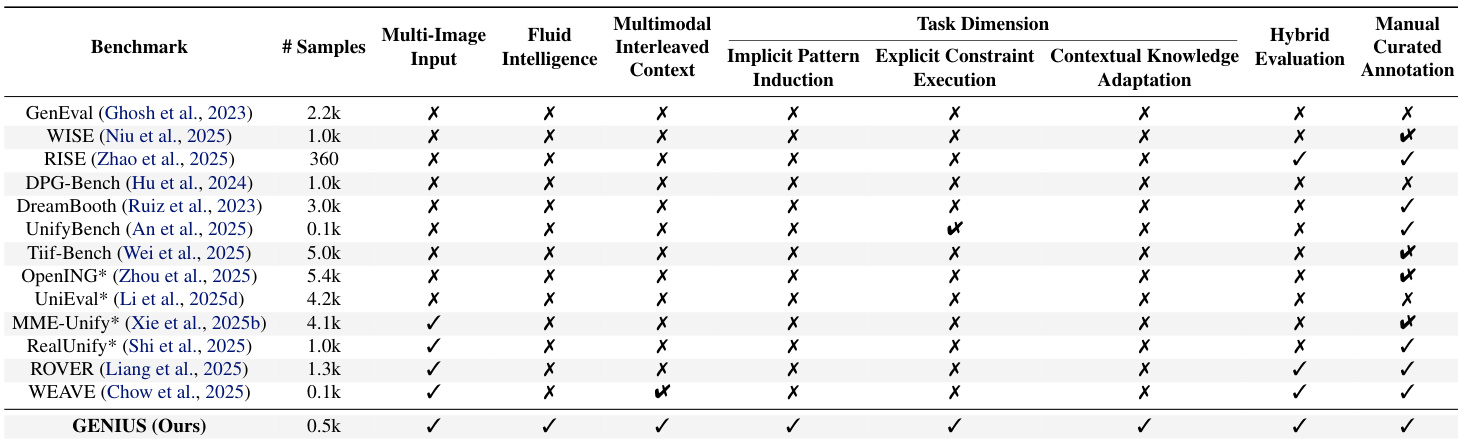
作者使用大型多模态模型作为评估者,评估 12 个图像生成模型在三个维度上的表现:规则遵守、视觉一致性、美学质量。结果显示,即使 Nano Banana Pro 等顶级专有模型总体得分也低于 60,揭示流体智力存在显著缺口——尤其在适应新颖或冲突规则方面——而开源模型表现更差。美学质量得分常掩盖逻辑遵守方面的深层失败,表明当前模型优先考虑表面真实而非上下文推理。