HyperAI
HyperAI
主区域
首页
GPU
控制台
文档
价格
Pulse
报道
资源
论文
教程
数据集
百科
基准测试
SOTA
大语言模型(LLM)
GPU 排行榜
社区
活动
开源
实用工具
搜索
关于
服务条款
隐私政策
中文
HyperAI
HyperAI
Toggle Sidebar
⌘
K
Command Palette
Search for a command to run...
登录
HyperAI
论文
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势
HyperAI
HyperAI
主区域
首页
GPU
控制台
文档
价格
Pulse
报道
资源
论文
教程
数据集
百科
基准测试
SOTA
大语言模型(LLM)
GPU 排行榜
社区
活动
开源
实用工具
搜索
关于
服务条款
隐私政策
中文
HyperAI
HyperAI
Toggle Sidebar
⌘
K
Command Palette
Search for a command to run...
登录
HyperAI
论文
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势
PrivateXR:通过可解释AI引导的差分隐私防御扩展现实中的隐私攻击
情绪识别
多模态
Ripan Kumar Kundu, Istiak Ahmed, Khaza Anuarul Hoque
时间摩擦与司法结果:基于2020—2024年库克县刑事判决中时间延迟影响的分析
数据集
建模
Yifei Tong
元强化学习在语言智能体中激发探索行为
强化学习
LLM
Yulun Jiang, Liangze Jiang, Damien Teney, et al.
LLMCache:面向Transformer推理中加速复用的分层缓存策略
LLM
Transformer
Harsh Vardhan Bansal
OPENTOUCH:将全手触觉带入现实世界交互
多模态
视频理解
Yuxin Ray Song, Jinzhou Li, Rao Fu, et al.
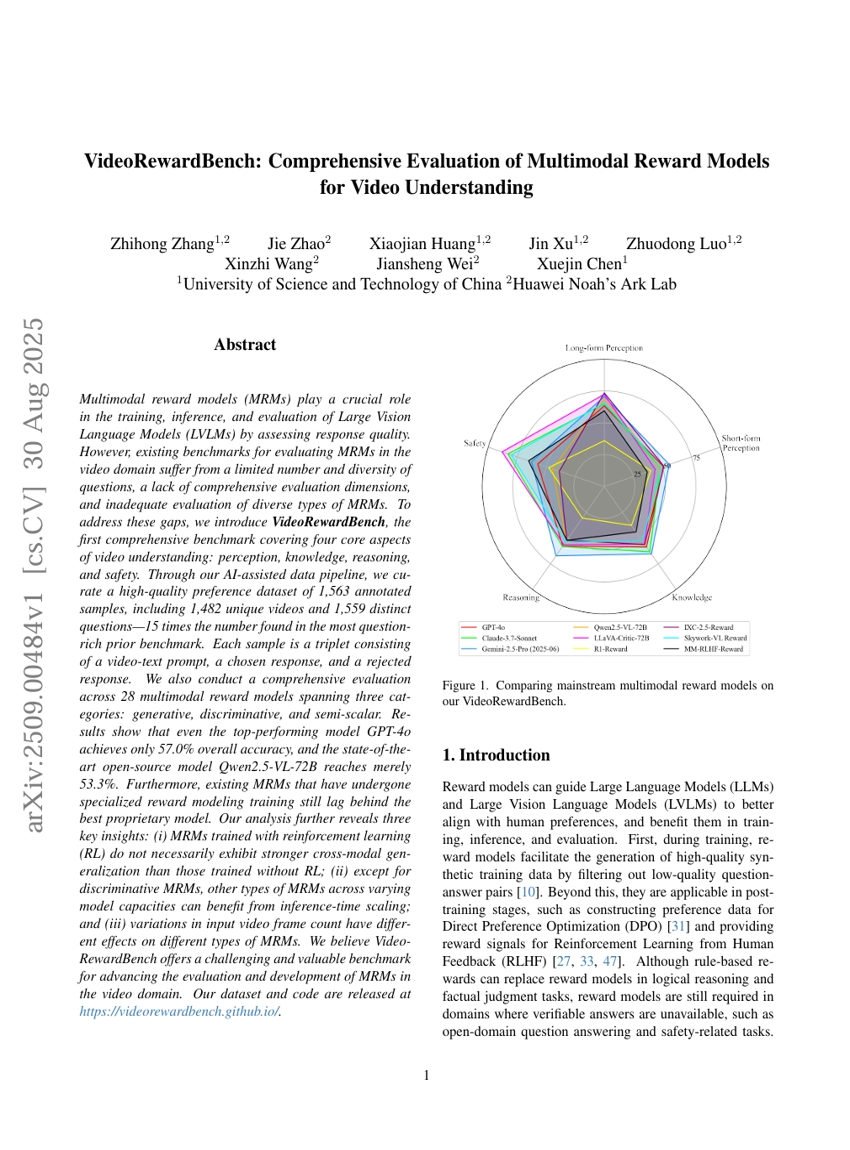
VideoRewardBench:面向视频理解的多模态Reward模型综合评估
视频理解
视觉问答
Zhihong Zhang, Xiaojian Huang, Jin Xu, et al.
Soul:为数字人注入生命力以实现高保真长期多模态动画
统一多模态
图生视频
Jiangning Zhang, Junwei Zhu, Zhenye Gan, et al.
IF-Bench:基于生成视觉的红外图像MLLMs基准测试与增强
视觉问答
基准
Tao Zhang, Yuyang Hong, Yang Xia, et al.
RecGPT-V2 技术报告
LLM
推理
Chao Yi, Dian Chen, Gaoyang Guo, et al.
向量棱镜:通过分层语义结构实现向量图形的动画化
图像分割
文生视频
Jooyeol Yun, Jaegul Choo
OpenDataArena:用于评估后训练数据集价值的公平开放平台
LLM
开源
Mengzhang Cai, Xin Gao, Yu Li, et al.
视频现实性测试:AI生成的ASMR视频能否欺骗视觉语言模型(VLMs)与人类?
多模态
视频处理
Jiaqi Wang, Weijia Wu, Yi Zhan, et al.
WorldPlay:迈向实时交互式世界建模的长期几何一致性
视频生成
3D 生成
Wenqiang Sun, Haiyu Zhang, Haoyuan Wang, et al.
MMGR:多模态生成推理
视频生成
推理
Zefan Cai, Haoyi Qiu, Tianyi Ma, et al.
前沿科学:评估AI执行专家级科学任务的能力
基准
推理
Miles Wang, Joy Jiao, Neil Chowdhury, et al.
FACTS排行榜:大语言模型事实性综合基准
基准
检索增强生成
Aileen Cheng, Alon Jacovi, Amir Globerson, et al.
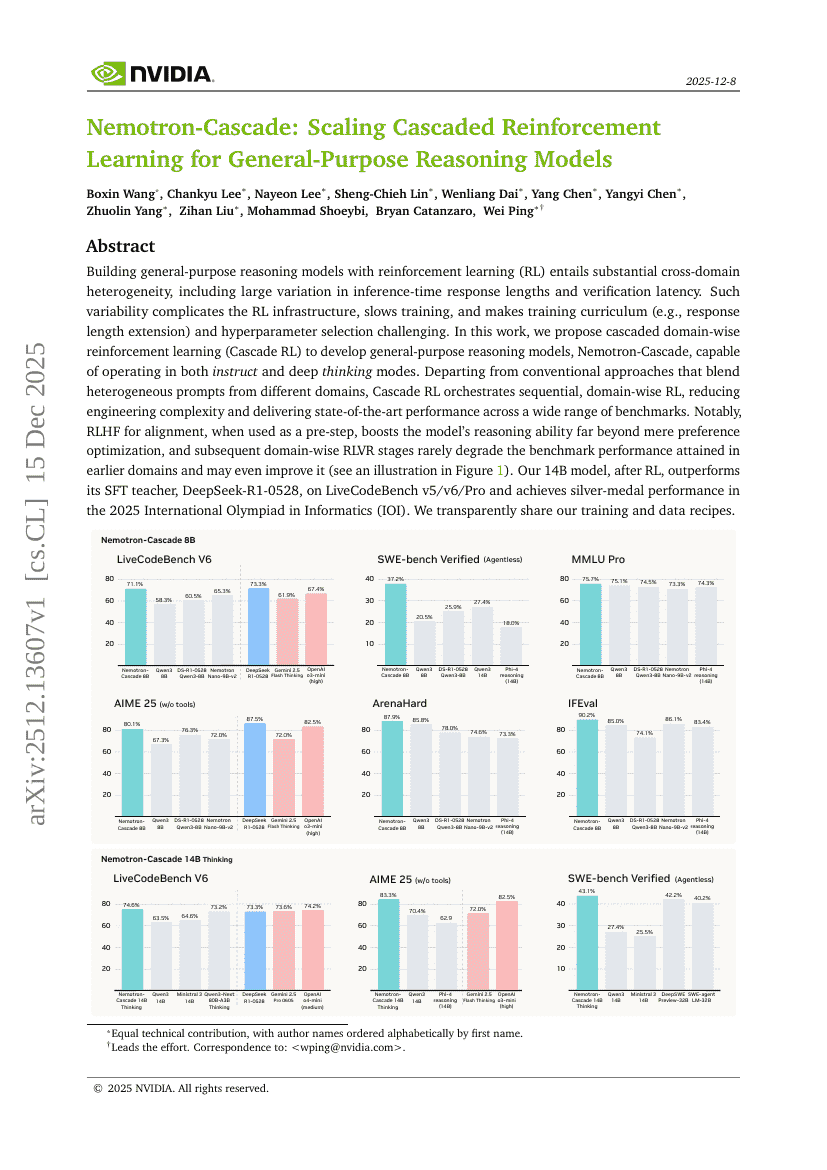
Nemotron-Cascade:面向通用推理模型的级联强化学习扩展
强化学习
推理
Boxin Wang, Chankyu Lee, Nayeon Lee, et al.
KlingAvatar 2.0 技术报告
文生视频
视频生成
Kling Team, Jialu Chen, Yikang Ding, et al.
QwenLong-L1.5:长上下文推理与记忆管理的后训练方案
推理
监督式微调
Weizhou Shen, Ziyi Yang, Chenliang Li, et al.
ReFusion:一种具有并行自回归解码的扩散型大语言模型
扩散模型
LLM
Jia-Nan Li, Jian Guan, Wei Wu, et al.
无错误的线性注意力机制:从连续时间动力学中获得的精确解
Transformer
LLM
Jingdi Lei, Di Zhang, Soujanya Poria
AI Agent时代中的记忆
Agent
检索增强生成
Yuyang Hu, Shichun Liu, Yanwei Yue, et al.
LongVie 2:多模态可控超长视频世界模型
视频生成
多模态
Jianxiong Gao, Zhaoxi Chen, Xian Liu, et al.
FirstAidQA:面向低连接性环境的急救与应急响应合成数据集
数据集
监督式微调
Saiyma Sittul Muna, Rezwan Islam Salvi, Mushfiqur Rahman Mushfique, et al.
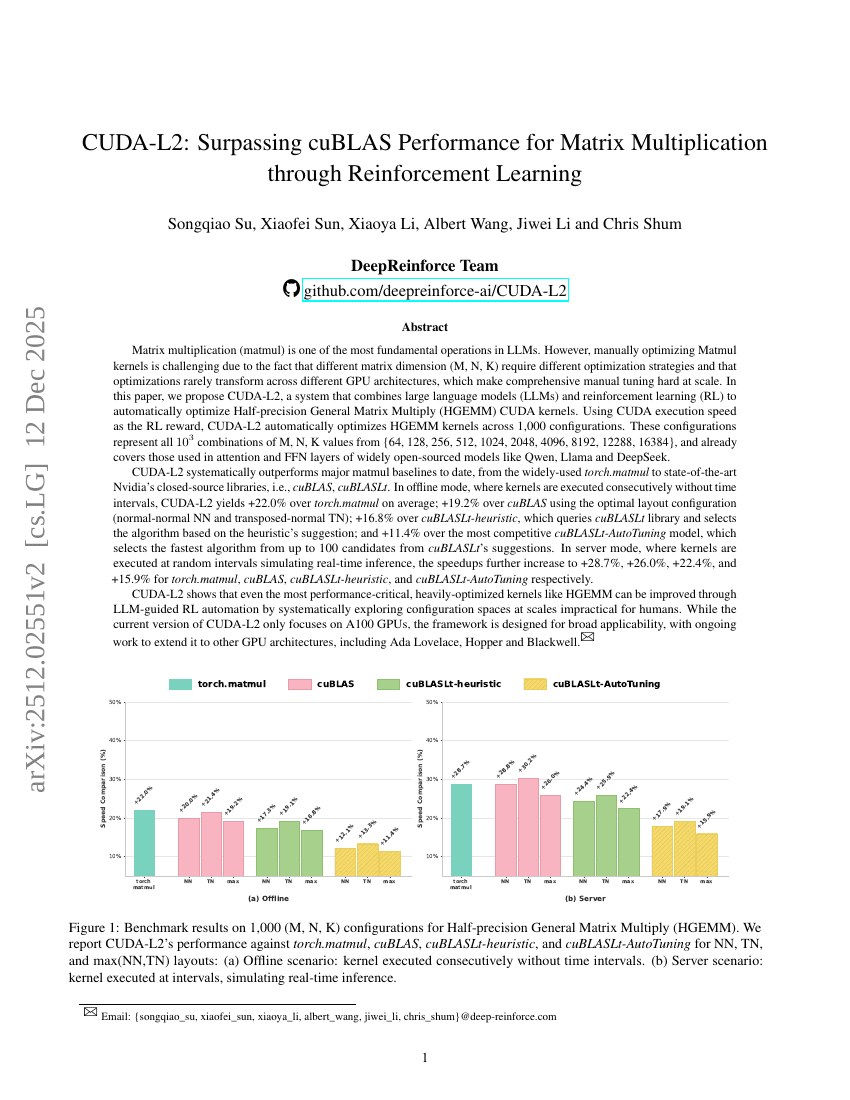
CUDA-L2:通过强化学习超越cuBLAS的矩阵乘法性能
LLM
高性能计算
Songqiao Su, Xiaofei Sun, Xiaoya Li, et al.
X-VLA:作为可扩展跨具身视觉-语言-动作模型的软提示Transformer
Transformer
机器人技术
Jinliang Zheng, Jianxiong Li, Zhihao Wang, et al.
Nemotron 3 Nano:面向Agent推理的开源、高效混合专家Mamba-Transformer模型
Transformer
监督式微调
NVIDIA
基于追踪的结构:视频生成中的结构保持性运动知识蒸馏
视频生成
扩散模型
Yang Fei, George Stoica, Jingyuan Liu, et al.
基于MetaCanvas的MLLM-Diffusion信息传递探索
扩散模型
图像生成
Han Lin, Xichen Pan, Ziqi Huang, et al.
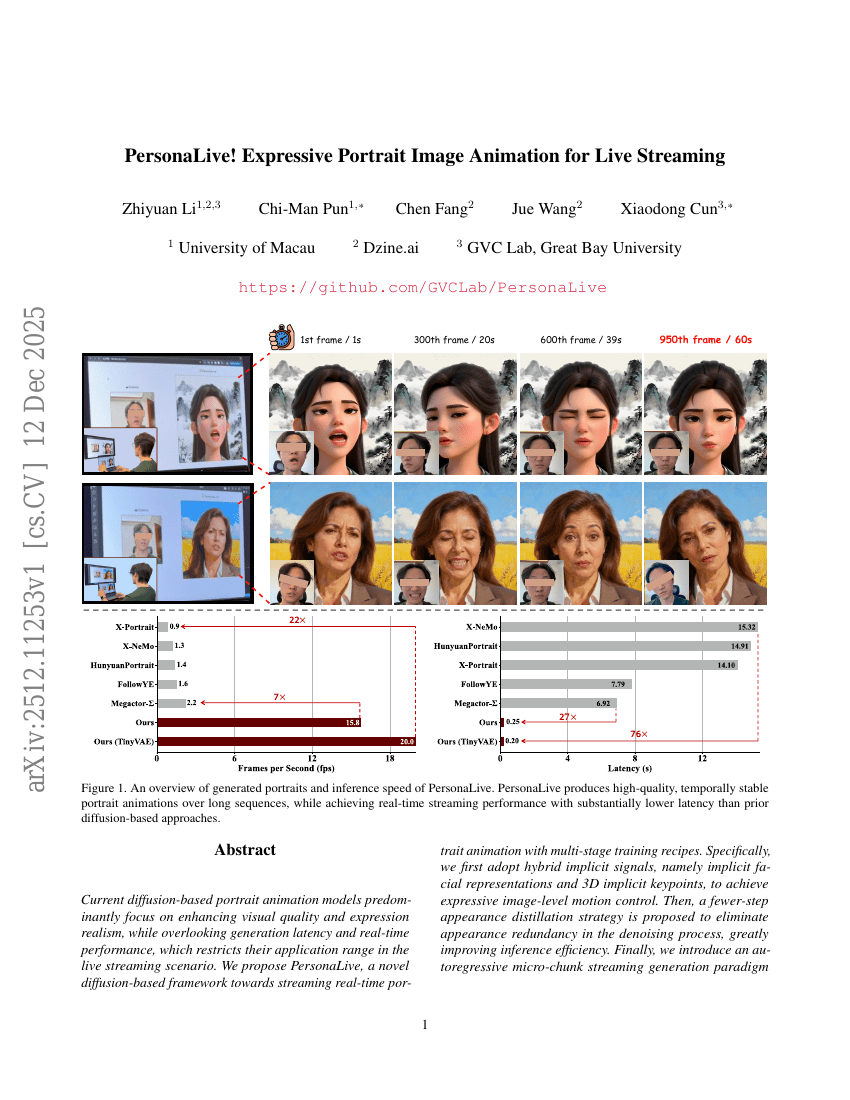
PersonaLive!用于直播的生动肖像图像动画
扩散模型
图生视频
Zhiyuan Li, Chi-Man Pun, Chen Fang, et al.
V-RGBX:基于内在属性精确控制的视频编辑
视频生成
视频处理
Ye Fang, Tong Wu, Valentin Deschaintre, et al.
SVG-T2I:在无需变分自编码器的情况下扩展文本到图像的潜在扩散模型
文生图
扩散模型
Minglei Shi, Haolin Wang, Borui Zhang, et al.
1
7
8
9
10
11
12
13
49
PrivateXR:通过可解释AI引导的差分隐私防御扩展现实中的隐私攻击
情绪识别
多模态
Ripan Kumar Kundu, Istiak Ahmed, Khaza Anuarul Hoque
时间摩擦与司法结果:基于2020—2024年库克县刑事判决中时间延迟影响的分析
数据集
建模
Yifei Tong
元强化学习在语言智能体中激发探索行为
强化学习
LLM
Yulun Jiang, Liangze Jiang, Damien Teney, et al.
LLMCache:面向Transformer推理中加速复用的分层缓存策略
LLM
Transformer
Harsh Vardhan Bansal
OPENTOUCH:将全手触觉带入现实世界交互
多模态
视频理解
Yuxin Ray Song, Jinzhou Li, Rao Fu, et al.
VideoRewardBench:面向视频理解的多模态Reward模型综合评估
视频理解
视觉问答
Zhihong Zhang, Xiaojian Huang, Jin Xu, et al.
Soul:为数字人注入生命力以实现高保真长期多模态动画
统一多模态
图生视频
Jiangning Zhang, Junwei Zhu, Zhenye Gan, et al.
IF-Bench:基于生成视觉的红外图像MLLMs基准测试与增强
视觉问答
基准
Tao Zhang, Yuyang Hong, Yang Xia, et al.
RecGPT-V2 技术报告
LLM
推理
Chao Yi, Dian Chen, Gaoyang Guo, et al.
向量棱镜:通过分层语义结构实现向量图形的动画化
图像分割
文生视频
Jooyeol Yun, Jaegul Choo
OpenDataArena:用于评估后训练数据集价值的公平开放平台
LLM
开源
Mengzhang Cai, Xin Gao, Yu Li, et al.
视频现实性测试:AI生成的ASMR视频能否欺骗视觉语言模型(VLMs)与人类?
多模态
视频处理
Jiaqi Wang, Weijia Wu, Yi Zhan, et al.
WorldPlay:迈向实时交互式世界建模的长期几何一致性
视频生成
3D 生成
Wenqiang Sun, Haiyu Zhang, Haoyuan Wang, et al.
MMGR:多模态生成推理
视频生成
推理
Zefan Cai, Haoyi Qiu, Tianyi Ma, et al.
前沿科学:评估AI执行专家级科学任务的能力
基准
推理
Miles Wang, Joy Jiao, Neil Chowdhury, et al.
FACTS排行榜:大语言模型事实性综合基准
基准
检索增强生成
Aileen Cheng, Alon Jacovi, Amir Globerson, et al.
Nemotron-Cascade:面向通用推理模型的级联强化学习扩展
强化学习
推理
Boxin Wang, Chankyu Lee, Nayeon Lee, et al.
KlingAvatar 2.0 技术报告
文生视频
视频生成
Kling Team, Jialu Chen, Yikang Ding, et al.
QwenLong-L1.5:长上下文推理与记忆管理的后训练方案
推理
监督式微调
Weizhou Shen, Ziyi Yang, Chenliang Li, et al.
ReFusion:一种具有并行自回归解码的扩散型大语言模型
扩散模型
LLM
Jia-Nan Li, Jian Guan, Wei Wu, et al.
无错误的线性注意力机制:从连续时间动力学中获得的精确解
Transformer
LLM
Jingdi Lei, Di Zhang, Soujanya Poria
AI Agent时代中的记忆
Agent
检索增强生成
Yuyang Hu, Shichun Liu, Yanwei Yue, et al.
LongVie 2:多模态可控超长视频世界模型
视频生成
多模态
Jianxiong Gao, Zhaoxi Chen, Xian Liu, et al.
FirstAidQA:面向低连接性环境的急救与应急响应合成数据集
数据集
监督式微调
Saiyma Sittul Muna, Rezwan Islam Salvi, Mushfiqur Rahman Mushfique, et al.
CUDA-L2:通过强化学习超越cuBLAS的矩阵乘法性能
LLM
高性能计算
Songqiao Su, Xiaofei Sun, Xiaoya Li, et al.
X-VLA:作为可扩展跨具身视觉-语言-动作模型的软提示Transformer
Transformer
机器人技术
Jinliang Zheng, Jianxiong Li, Zhihao Wang, et al.
Nemotron 3 Nano:面向Agent推理的开源、高效混合专家Mamba-Transformer模型
Transformer
监督式微调
NVIDIA
基于追踪的结构:视频生成中的结构保持性运动知识蒸馏
视频生成
扩散模型
Yang Fei, George Stoica, Jingyuan Liu, et al.
基于MetaCanvas的MLLM-Diffusion信息传递探索
扩散模型
图像生成
Han Lin, Xichen Pan, Ziqi Huang, et al.
PersonaLive!用于直播的生动肖像图像动画
扩散模型
图生视频
Zhiyuan Li, Chi-Man Pun, Chen Fang, et al.
V-RGBX:基于内在属性精确控制的视频编辑
视频生成
视频处理
Ye Fang, Tong Wu, Valentin Deschaintre, et al.
SVG-T2I:在无需变分自编码器的情况下扩展文本到图像的潜在扩散模型
文生图
扩散模型
Minglei Shi, Haolin Wang, Borui Zhang, et al.
1
7
8
9
10
11
12
13
49