HyperAI
HyperAI
主区域
首页
GPU
控制台
文档
价格
Pulse
报道
资源
论文
教程
数据集
百科
基准测试
SOTA
大语言模型(LLM)
GPU 排行榜
社区
活动
开源
实用工具
搜索
关于
服务条款
隐私政策
中文
HyperAI
HyperAI
Toggle Sidebar
⌘
K
Command Palette
Search for a command to run...
登录
HyperAI
论文
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势
HyperAI
HyperAI
主区域
首页
GPU
控制台
文档
价格
Pulse
报道
资源
论文
教程
数据集
百科
基准测试
SOTA
大语言模型(LLM)
GPU 排行榜
社区
活动
开源
实用工具
搜索
关于
服务条款
隐私政策
中文
HyperAI
HyperAI
Toggle Sidebar
⌘
K
Command Palette
Search for a command to run...
登录
HyperAI
论文
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势
DINOv3
Transformer
多任务学习
Oriane Siméoni, Huy V. Vo, Maximilian Seitzer, et al.
SSRL:自搜索强化学习
强化学习
LLM
Yuchen Fan, Kaiyan Zhang, Heng Zhou, et al.
Thyme:超越图像的思考
多模态
推理
Yi-Fan Zhang, Xingyu Lu, Shukang Yin, et al.
用文化知识对多语言多模态LLM进行接地
视觉问答
LLM
Jean de Dieu Nyandwi, Yueqi Song, Simran Khanuja, et al.
HiFiTTS-2:一个大规模高带宽语音数据集
语音生成
合成
Ryan Langman, Xuesong Yang, Paarth Neekhara, et al.
CryptoScope:利用大语言模型实现密码逻辑漏洞的自动化检测
LLM
检索增强生成
Zhihao Li, Zimo Ji, Tao Zheng, et al.
医学图谱RAG:通过图谱检索增强生成实现安全的医学大语言模型
检索增强生成
LLM
Junde Wu, Jiayuan Zhu, Yunli Qi, et al.
Puppeteer:为你的3D模型绑定并动画化
3D 模型
3D 生成
Chaoyue Song, Xiu Li, Fan Yang, et al.
STream3R:基于因果Transformer的可扩展序列3D重建
机器视觉 3D
3D 生成
Yushi Lan, Yihang Luo, Fangzhou Hong, et al.
PRELUDE:一个旨在要求对长上下文进行全局理解与推理的基准
推理
检索增强生成
Mo Yu, Tsz Ting Chung, Chulun Zhou, et al.
ToonComposer:通过生成式后关键帧技术简化动画制作
图生视频
图生图
Lingen Li, Guangzhi Wang, Zhaoyang Zhang, et al.
NextStep-1:面向大规模连续Token的自回归图像生成
文生图
图像生成
NextStep Team, Chunrui Han, Guopeng Li, et al.
We-Math 2.0:一种用于激励视觉数学推理的多功能MathBook系统
推理
数据集
Runqi Qiao, Qiuna Tan, Peiqing Yang, et al.
COREVQA:一种众包观察与推理蕴含的视觉问答基准
视觉问答
基准
Ishant Chintapatla, Kazuma Choji, Naaisha Agarwal, et al.
RelayFormer:一种用于可扩展图像与视频操纵定位的统一局部-全局注意力框架
Transformer
统一多模态
Wen Huang, Jiarui Yang, Tao Dai, et al.
GMF-Drive:具有空间感知BEV表示的门控Mamba融合用于端到端自动驾驶
Transformer
自动驾驶
Jian Wang, Chaokang Jiang, Haitao Xu
看、听、记、思:具备长期记忆的多模态Agent
Agent
推理
Lin Long, Yichen He, Wentao Ye, et al.
扩散型LLM可通过离散扩散强制实现快于自回归的推理
LLM
扩散模型
Xu Wang, Chenkai Xu, Yijie Jin, et al.
AWorld:具有稳定机动性的动态多Agent系统,用于鲁棒的GAIA问题求解
Agent
LLM
Zhitian Xie, Qintong Wu, Chengyue Yu, et al.
Story2Board:一种无需训练的富有表现力的分镜生成方法
文生图
图像生成
David Dinkevich, Matan Levy, Omri Avrahami, et al.
替身:一种轻量级且即插即用的视频生成身份控制方法
视频生成
图生视频
Bowen Xue, Qixin Yan, Wenjing Wang, et al.
Mol-R1:面向分子发现中显式长链思维推理
LLM
监督式微调
Jiatong Li, Weida Wang, Qinggang Zhang, et al.
Llama-Nemotron:高效推理模型
LLM
推理
Akhiad Bercovich, Itay Levy, Izik Golan, et al.
Document Haystack:一个长上下文多模态图像/文档理解视觉LLM基准
文档理解
视觉文档检索
Goeric Huybrechts, Srikanth Ronanki, Sai Muralidhar Jayanthi, et al.
Echo-4o:利用GPT-4o合成图像提升图像生成性能
文生图
数据集
Junyan Ye, Dongzhi Jiang, Zihao Wang, et al.
无标记组织在成像质谱中的虚拟染色
计算机视觉
图像理解
Yijie Zhang, Luzhe Huang, Nir Pillar, et al.
VisCodex:通过融合视觉与编码模型实现统一的多模态代码生成
代码生成
多模态表征
Lingjie Jiang, Shaohan Huang, Xun Wu, et al.
HierSearch:一种集成本地搜索与网络搜索的分层企业深度搜索框架
检索增强生成
Agent
Jiejun Tan, Zhicheng Dou, Yan Yu, et al.
时间是一种特征:在扩散语言模型中利用时间动态特性
扩散模型
推理
Wen Wang, Bozhen Fang, Chenchen Jing, et al.
CharacterShot:可控且一致的4D角色动画
图生视频
3D 生成
Junyao Gao, Jiaxing Li, Wenran Liu, et al.
超越十轮:基于大规模异步强化学习的长周期智能体搜索
强化学习
智能问答
Jiaxuan Gao, Wei Fu, Minyang Xie, et al.
Matrix-3D:全向可探索的3D世界生成
3D 生成
图生视频
Zhongqi Yang, Wenhang Ge, Yuqi Li, et al.
1
33
34
35
36
37
38
39
49
DINOv3
Transformer
多任务学习
Oriane Siméoni, Huy V. Vo, Maximilian Seitzer, et al.
SSRL:自搜索强化学习
强化学习
LLM
Yuchen Fan, Kaiyan Zhang, Heng Zhou, et al.
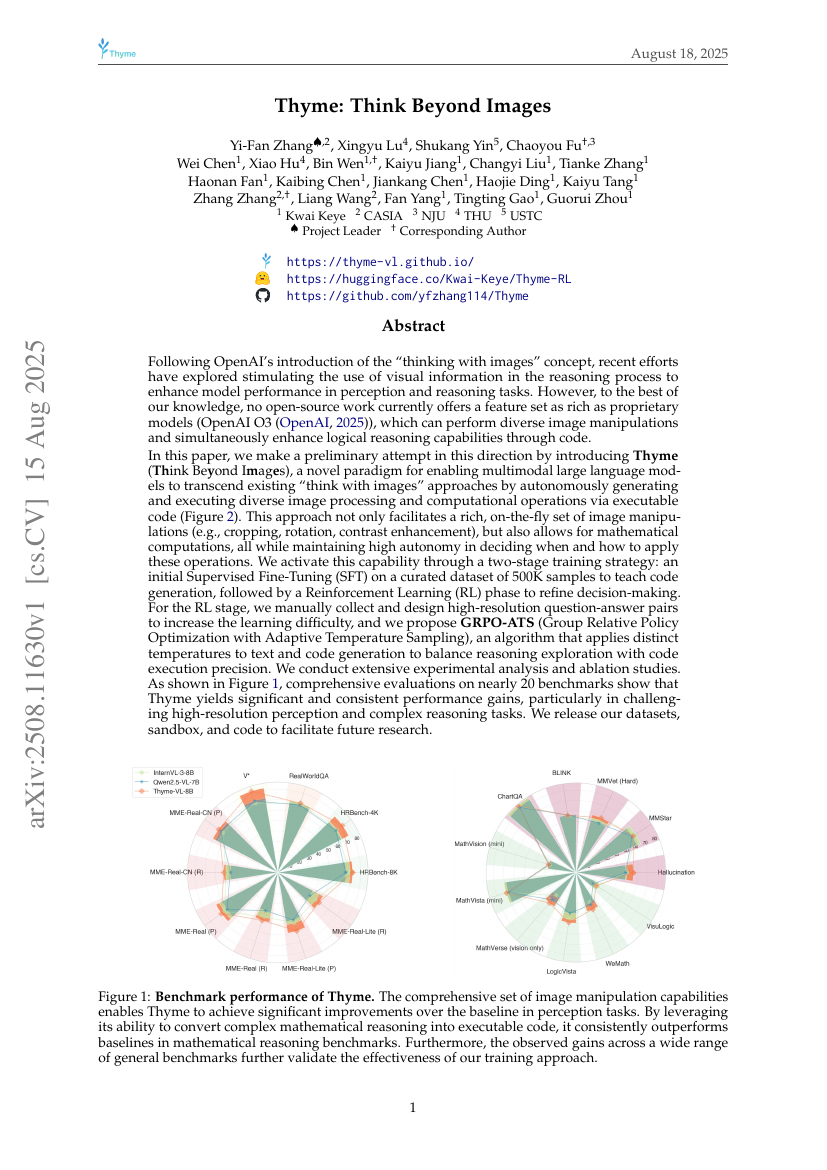
Thyme:超越图像的思考
多模态
推理
Yi-Fan Zhang, Xingyu Lu, Shukang Yin, et al.
用文化知识对多语言多模态LLM进行接地
视觉问答
LLM
Jean de Dieu Nyandwi, Yueqi Song, Simran Khanuja, et al.
HiFiTTS-2:一个大规模高带宽语音数据集
语音生成
合成
Ryan Langman, Xuesong Yang, Paarth Neekhara, et al.
CryptoScope:利用大语言模型实现密码逻辑漏洞的自动化检测
LLM
检索增强生成
Zhihao Li, Zimo Ji, Tao Zheng, et al.
医学图谱RAG:通过图谱检索增强生成实现安全的医学大语言模型
检索增强生成
LLM
Junde Wu, Jiayuan Zhu, Yunli Qi, et al.
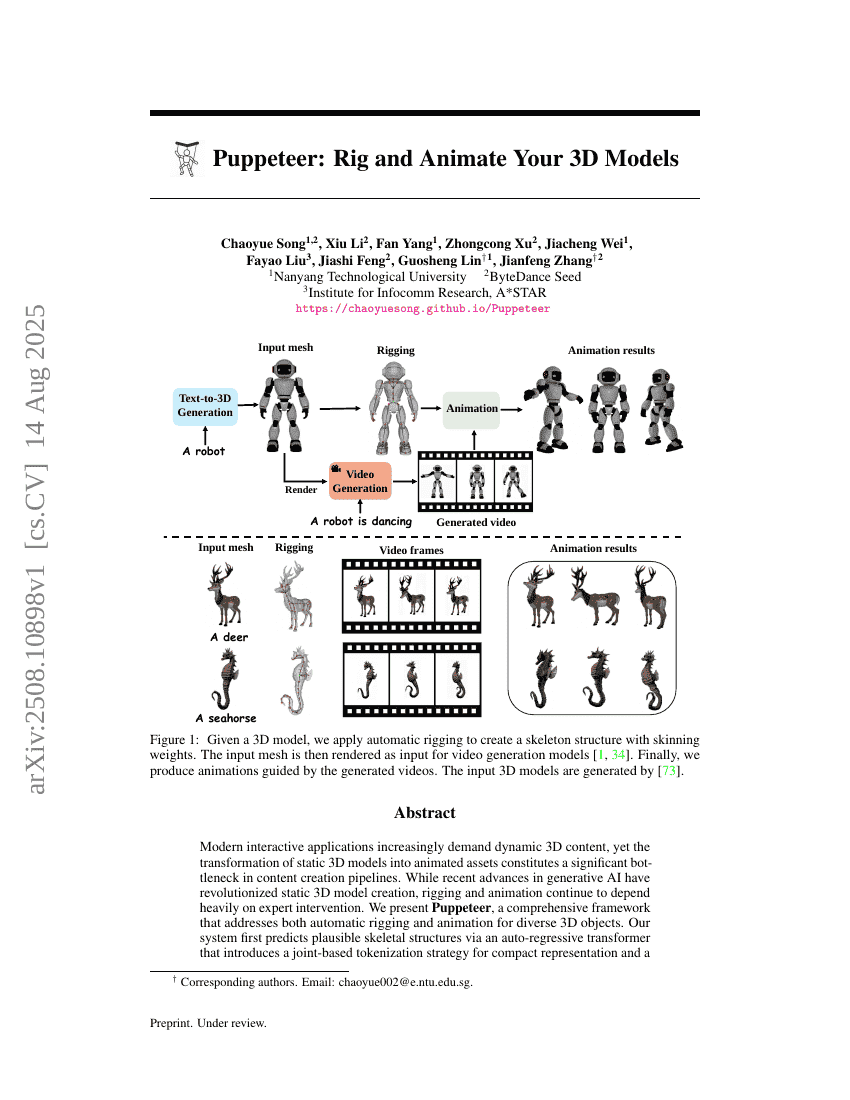
Puppeteer:为你的3D模型绑定并动画化
3D 模型
3D 生成
Chaoyue Song, Xiu Li, Fan Yang, et al.
STream3R:基于因果Transformer的可扩展序列3D重建
机器视觉 3D
3D 生成
Yushi Lan, Yihang Luo, Fangzhou Hong, et al.
PRELUDE:一个旨在要求对长上下文进行全局理解与推理的基准
推理
检索增强生成
Mo Yu, Tsz Ting Chung, Chulun Zhou, et al.
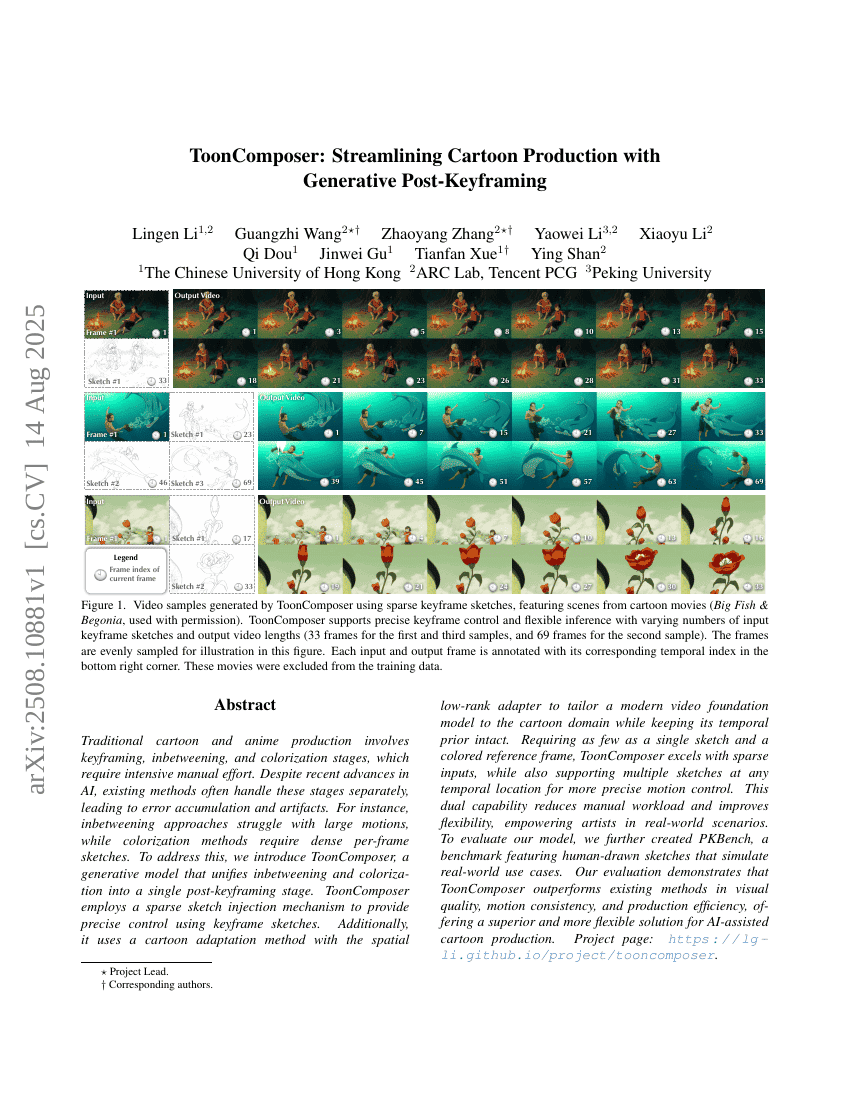
ToonComposer:通过生成式后关键帧技术简化动画制作
图生视频
图生图
Lingen Li, Guangzhi Wang, Zhaoyang Zhang, et al.
NextStep-1:面向大规模连续Token的自回归图像生成
文生图
图像生成
NextStep Team, Chunrui Han, Guopeng Li, et al.
We-Math 2.0:一种用于激励视觉数学推理的多功能MathBook系统
推理
数据集
Runqi Qiao, Qiuna Tan, Peiqing Yang, et al.
COREVQA:一种众包观察与推理蕴含的视觉问答基准
视觉问答
基准
Ishant Chintapatla, Kazuma Choji, Naaisha Agarwal, et al.
RelayFormer:一种用于可扩展图像与视频操纵定位的统一局部-全局注意力框架
Transformer
统一多模态
Wen Huang, Jiarui Yang, Tao Dai, et al.
GMF-Drive:具有空间感知BEV表示的门控Mamba融合用于端到端自动驾驶
Transformer
自动驾驶
Jian Wang, Chaokang Jiang, Haitao Xu
看、听、记、思:具备长期记忆的多模态Agent
Agent
推理
Lin Long, Yichen He, Wentao Ye, et al.
扩散型LLM可通过离散扩散强制实现快于自回归的推理
LLM
扩散模型
Xu Wang, Chenkai Xu, Yijie Jin, et al.
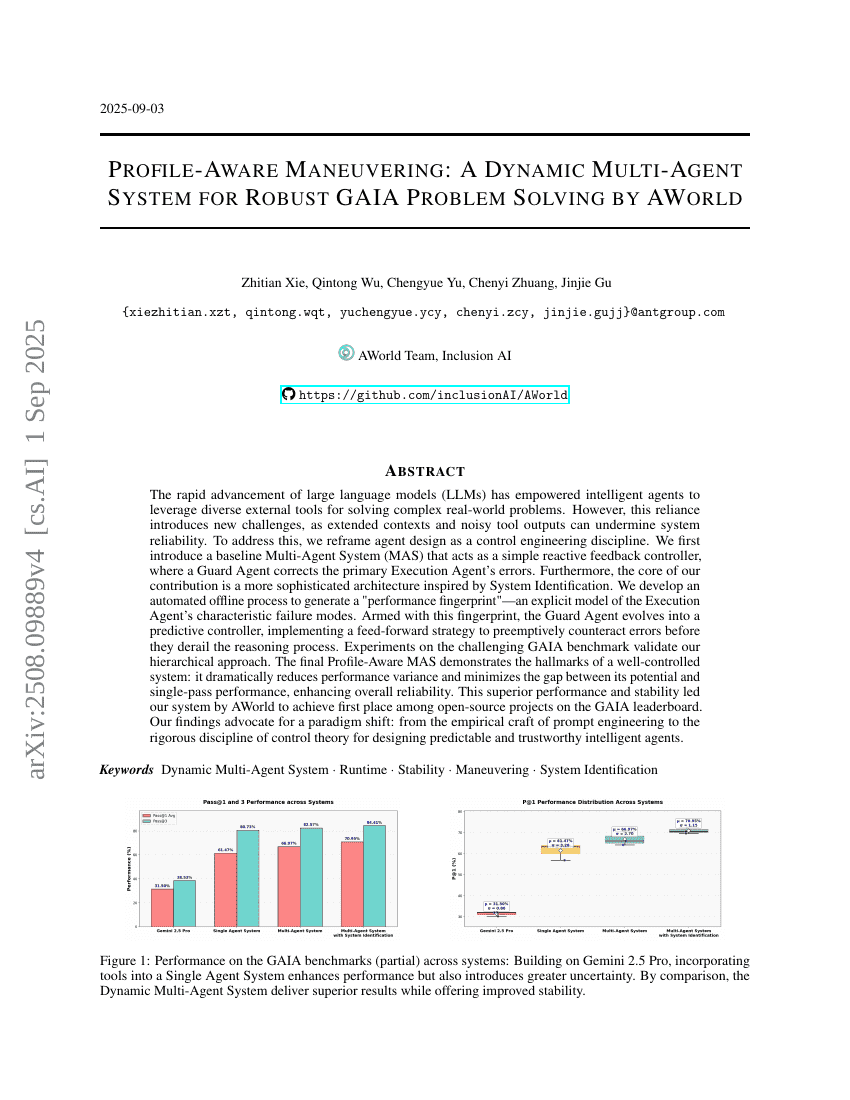
AWorld:具有稳定机动性的动态多Agent系统,用于鲁棒的GAIA问题求解
Agent
LLM
Zhitian Xie, Qintong Wu, Chengyue Yu, et al.
Story2Board:一种无需训练的富有表现力的分镜生成方法
文生图
图像生成
David Dinkevich, Matan Levy, Omri Avrahami, et al.
替身:一种轻量级且即插即用的视频生成身份控制方法
视频生成
图生视频
Bowen Xue, Qixin Yan, Wenjing Wang, et al.
Mol-R1:面向分子发现中显式长链思维推理
LLM
监督式微调
Jiatong Li, Weida Wang, Qinggang Zhang, et al.
Llama-Nemotron:高效推理模型
LLM
推理
Akhiad Bercovich, Itay Levy, Izik Golan, et al.
Document Haystack:一个长上下文多模态图像/文档理解视觉LLM基准
文档理解
视觉文档检索
Goeric Huybrechts, Srikanth Ronanki, Sai Muralidhar Jayanthi, et al.
Echo-4o:利用GPT-4o合成图像提升图像生成性能
文生图
数据集
Junyan Ye, Dongzhi Jiang, Zihao Wang, et al.
无标记组织在成像质谱中的虚拟染色
计算机视觉
图像理解
Yijie Zhang, Luzhe Huang, Nir Pillar, et al.
VisCodex:通过融合视觉与编码模型实现统一的多模态代码生成
代码生成
多模态表征
Lingjie Jiang, Shaohan Huang, Xun Wu, et al.
HierSearch:一种集成本地搜索与网络搜索的分层企业深度搜索框架
检索增强生成
Agent
Jiejun Tan, Zhicheng Dou, Yan Yu, et al.
时间是一种特征:在扩散语言模型中利用时间动态特性
扩散模型
推理
Wen Wang, Bozhen Fang, Chenchen Jing, et al.
CharacterShot:可控且一致的4D角色动画
图生视频
3D 生成
Junyao Gao, Jiaxing Li, Wenran Liu, et al.
超越十轮:基于大规模异步强化学习的长周期智能体搜索
强化学习
智能问答
Jiaxuan Gao, Wei Fu, Minyang Xie, et al.
Matrix-3D:全向可探索的3D世界生成
3D 生成
图生视频
Zhongqi Yang, Wenhang Ge, Yuqi Li, et al.
1
33
34
35
36
37
38
39
49