Command Palette
Search for a command to run...
Emerging Properties in Unified Multimodal Pretraining
Emerging Properties in Unified Multimodal Pretraining
Abstract
Unifying multimodal understanding and generation has shown impressive capabilities in cutting-edge proprietary systems. In this work, we introduce BAGEL, an open-source foundational model that natively supports multimodal understanding and generation. BAGEL is a unified, decoder-only model pretrained on trillions of tokens curated from large-scale interleaved text, image, video, and web data. When scaled with such diverse multimodal interleaved data, BAGEL exhibits emerging capabilities in complex multimodal reasoning. As a result, it significantly outperforms open-source unified models in both multimodal generation and understanding across standard benchmarks, while exhibiting advanced multimodal reasoning abilities such as free-form image manipulation, future frame prediction, 3D manipulation, and world navigation. In the hope of facilitating further opportunities for multimodal research, we share the key findings, pretraining details, data creation protocal, and release our code and checkpoints to the community. The project page is at https://bagel-ai.org/
One-sentence Summary
The authors, from ByteDance Seed, Shenzhen Institutes of Advanced Technology, Monash University, Hong Kong University of Science and Technology, and UC Santa Cruz, propose BAGEL, a decoder-only open-source foundational model pretrained on trillions of interleaved multimodal tokens, enabling emergent multimodal reasoning and superior performance in unified understanding and generation, including free-form image manipulation and 3D world navigation, with code and checkpoints released to advance community research.
Key Contributions
-
BAGEL is a unified, decoder-only foundational model pretrained on trillions of tokens from large-scale interleaved text, image, video, and web data, enabling native multimodal understanding and generation in a single architecture. This design allows for emergent complex reasoning capabilities not fully realized in prior open-source models trained primarily on image-text pairs.
-
The model demonstrates advanced multimodal reasoning through tasks such as free-form image manipulation, future frame prediction, 3D object manipulation, and world navigation, enabled by its training on diverse, interleaved multimodal data that supports long-context, compositional reasoning across modalities.
-
BAGEL significantly outperforms existing open-source unified models on standard multimodal benchmarks and releases its code, checkpoints, pretraining details, and data creation protocols to foster further research, promoting transparency and reproducibility in multimodal AI.
Introduction
The authors leverage large-scale, multimodal interleaved data—integrating text, images, video, and web content—to train BAGEL, a unified decoder-only model that advances both multimodal understanding and generation. This approach addresses a key limitation in prior work, which relied heavily on image-text paired data and failed to support complex, long-context reasoning across multiple modalities. By scaling with diverse, interleaved data, BAGEL exhibits emergent capabilities such as free-form image manipulation, future frame prediction, 3D object interaction, and world navigation, significantly closing the performance gap with proprietary systems. The main contribution is a scalable, open-source framework that enables advanced multimodal reasoning through unified pretraining, accompanied by detailed data protocols, code, and checkpoints to accelerate community research.
Dataset
- The BAGEL model is trained on a diverse, multimodal dataset combining language, image, video, and web data to support tasks like multimodal reasoning, in-context prediction, and future frame generation through a unified interface.
- The dataset includes three main components: text-only data, vision-text paired data, and newly constructed interleaved data from video and web sources.
- Text-only data is high-quality, curated to maintain strong language modeling and reasoning capabilities across general text tasks.
- Vision-text paired data is split into two subsets:
- VLM Image-Text Pairs: sourced from web alt-text and captions, filtered via CLIP similarity, resolution/aspect ratio constraints, text length checks, and deduplication; includes structured supervision from OCR, charts, and grounding annotations.
- T2I Image-Text Pairs: includes high-quality real image-text pairs and minimal synthetic data from existing T2I models, with diverse caption styles and high image clarity, structural integrity, and semantic diversity.
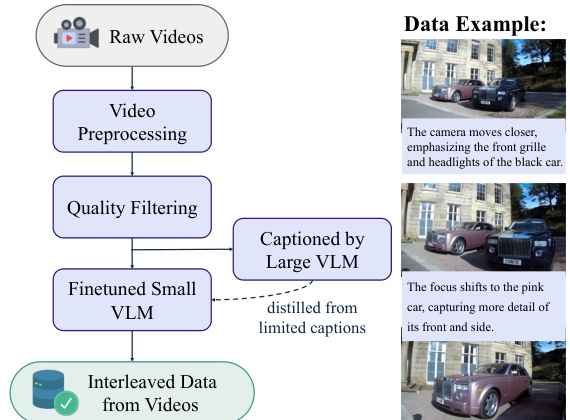
- Video data is derived from public online videos and two open-source datasets—Koala36M (instructional content) and MVImgNet2.0 (multi-view object capture)—to support temporal and spatial understanding.
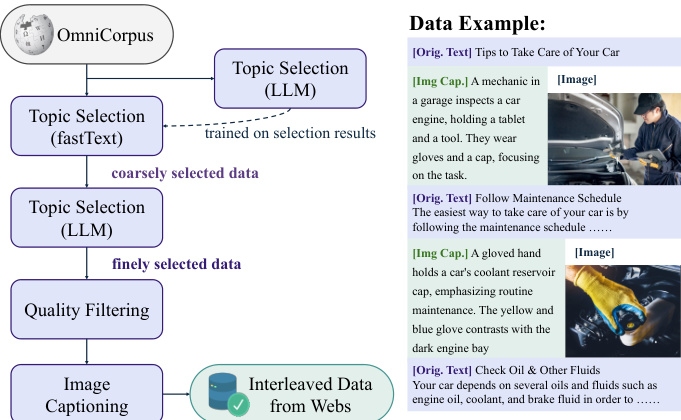
- Web data is built on OmniCorpus, a large-scale collection from Common Crawl, enriched with open-source image editing datasets to provide structured, interleaved text-image content.
- Data filtering for video: clips are segmented using shot detection, cropped to remove borders and overlays, and filtered by length, resolution, clarity, motion stability, and CLIP-based deduplication.
- Data filtering for web: a two-stage pipeline is used—first, fastText classifiers trained on LLM-generated labels select relevant documents; second, a Qwen2.5-14B model performs fine-grained filtering, followed by rule-based checks for image clarity, relevance, and document structure.
- Interleaved video data is constructed by generating short, temporally grounded captions (max 30 tokens) between consecutive frames using a distilled Qwen2.5-VL-7B model; on average, four frames per clip yield 45 million interleaved sequences.
- Interleaved web data uses a caption-first strategy: each image is preceded by a concise, LLM-generated caption (via Qwen2.5-VL-7B) to guide image generation and improve alignment; inter-image text segments over 300 tokens are summarized with an LLM to enhance contextual density, resulting in 20 million structured sequences.
- During training, the model uses a mixture of data types with carefully tuned ratios, combining text, vision-text pairs, and interleaved video and web data to balance modalities and support diverse reasoning and generation tasks.
Method
The authors leverage a Mixture-of-Transformer-Experts (MoT) architecture to unify multimodal understanding and generation within a single model, enabling seamless interaction between the two modalities. As shown in the framework diagram, the model employs two distinct transformer experts: an understanding-oriented expert and a generation-oriented expert. These experts operate on the same token sequence through shared self-attention operations at every layer, eliminating the need for bottleneck connectors and allowing for long-context interaction between understanding and generation processes. This bottleneck-free design facilitates the scaling of training data and steps, enabling the model's full capacity signals to emerge without architectural constraints.
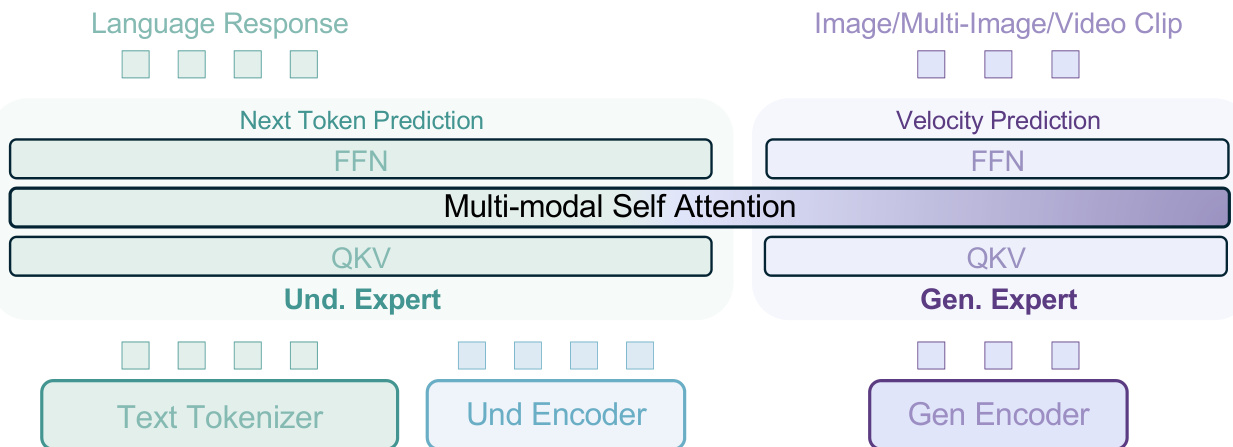
The backbone model is initialized from a decoder-only transformer architecture, specifically Qwen2.5, which incorporates RMSNorm for normalization, SwiGLU for activation, RoPE for positional encoding, and GQA for KV cache reduction. To stabilize training, QK-Norm is added to each attention block. Visual information is processed through two distinct pathways: for understanding, a ViT encoder converts raw pixels into tokens, initialized from SigLIP2-so400m/14 and enhanced with NaViT for native aspect ratio processing; for generation, a pre-trained VAE model from FLUX converts images to latent space, with the VAE model frozen during training. Both ViT and VAE tokens are integrated into the LLM backbone with 2D positional encoding, and diffusion timestep encoding is applied directly to the initial hidden states of VAE tokens.
The model's training data is constructed through a scalable protocol that incorporates web and video sources. Video data provides pixel-level, conceptual, temporal, and physical continuity, offering signals essential for acquiring grounded world knowledge. The interleaved data format includes tasks such as multimodal conversation, text-to-image/video, and image manipulation, enabling seamless integration of diverse generative data. To enhance reasoning capabilities, the data is enriched with reasoning-oriented content, facilitating multi-modal reasoning and knowledge transfer between understanding and generation processes. This curated data captures rich world knowledge and nuanced cross-modal interactions, equipping the model with foundational capabilities in in-context prediction, world modeling, and complex multimodal reasoning.
During training, an interleaved multimodal generation sample may contain multiple images, each with three sets of visual tokens: noised VAE tokens for Rectified-Flow training, clean VAE tokens for conditioning, and ViT tokens for input format unification. For interleaved image or text generation, subsequent tokens may attend to clean VAE and ViT tokens of preceding images but not to their noised counterparts. For interleaved multi-image generation, the diffusion forcing strategy is adopted, adding independent noise levels to different images and conditioning each on noisy representations of preceding images. To enhance generation consistency, consecutive images are randomly grouped and full attention is applied within each group. The generalized causal attention mechanism is implemented using PyTorch FlexAttention, achieving a ~2× speed-up over naive scaled-dot-product attention. During inference, the generalized causal structure allows caching of key-value pairs for the generated multimodal context, accelerating decoding. Only the KV pairs of clean VAE tokens and ViT tokens are stored, and once an image is fully generated, the corresponding noised VAE tokens are replaced by their clean counterparts. Classifier-free guidance is enabled by randomly dropping text, ViT, and clean VAE tokens with specific probabilities.

The model is trained on reasoning-augmented data, which includes 500k examples across four categories: text-to-image generation, free-form image manipulation, and conceptual edits. For text-to-image generation, ambiguous queries are paired with simple guidance, and Qwen2.5-72B is prompted to generate additional query-guidance pairs and detailed prompts, which are then passed to FLUX.1-dev to produce target images. For free-form image manipulation, a VLM is prompted with source and target image pairs, user queries, and reasoning trace examples from DeepSeek-R1 to generate grounded explanations. Conceptual edits involve a three-stage VLM pipeline to construct high-quality QA examples, where the model learns to interpret complex visual goals from diverse textual instructions. This approach helps the model learn to ground image generation in language-based reasoning and improve planning for complex visual tasks.
Experiment
- Compared Dense Transformer, MoE, and MoT variants on a 1.5B LLM; MoT consistently outperformed both, especially in multimodal generation with lower MSE loss and faster convergence, validating the benefit of decoupling generation and understanding parameters.
- Ablation studies on data sampling ratio showed that increasing generation data from 50% to 80% reduced MSE loss by 0.4%, indicating generation tasks should be prioritized during training.
- Learning rate ablation revealed a trade-off: higher rates accelerated generation convergence, while lower rates improved understanding; a balanced approach with objective weighting was adopted.
- On MME, MMBench, MM-Vet, MMMU, MathVista, and MMVP benchmarks, BAGEL-7B achieved state-of-the-art performance, outperforming Janus-Pro by 14.3 and 17.1 points on MMMU and MM-Vet, respectively.
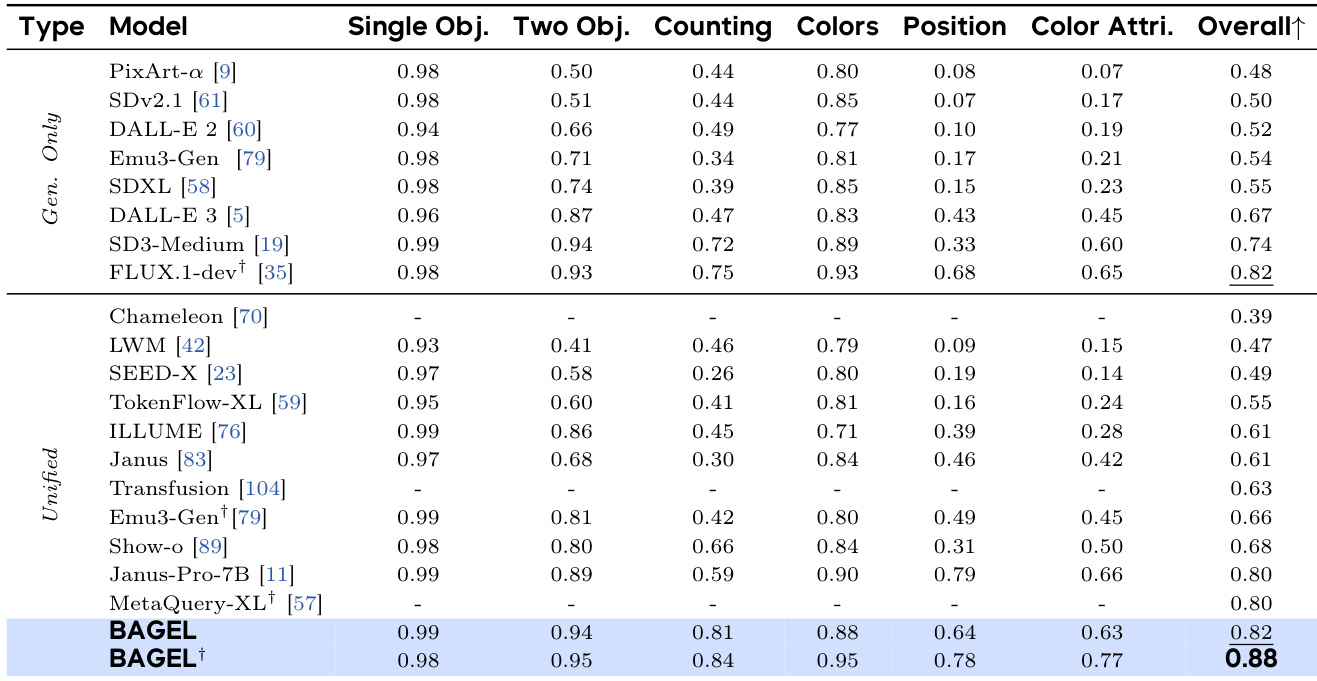
- On GenEval, BAGEL achieved 88% score, surpassing specialized models (FLUX-1-dev: 82%, SD3-Medium: 74%) and unified models (Janus-Pro: 80%, MetaQuery-XL: 80%).
- On WISE, BAGEL exceeded all open-source models except GPT-4o, demonstrating strong world knowledge integration in text-to-image generation.
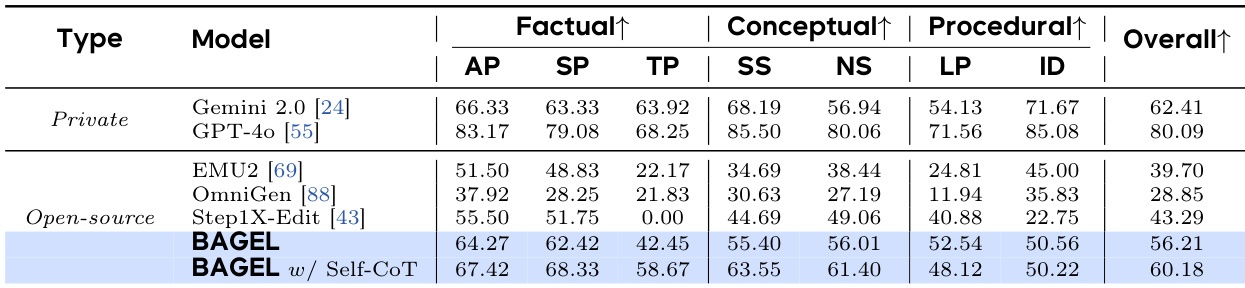
- On GEdit-Bench, BAGEL matched the leading specialist model Step1X-Edit and outperformed Gemini 2.0; on IntelligentBench, it achieved 44.9, 30 points higher than Step1X-Edit, validating superior complex reasoning.
- With chain-of-thought reasoning, BAGEL improved its WISE score to 0.70 (from 0.52) and IntelligentBench score to 55.3 (from 44.9), showing significant gains in multimodal reasoning.
- BAGEL demonstrated emergent capabilities: understanding and generation emerged early, while intelligent editing required 3.61T tokens to reach 85% performance, indicating late-stage emergence tied to complex reasoning.
- BAGEL-1.5B outperformed larger models (JanusPro-7B, Step1X-Edit-12B) in qualitative image generation and editing, highlighting strong efficiency and scalability.
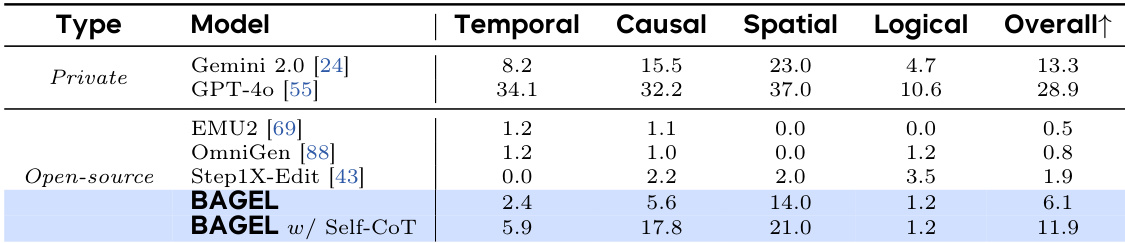
The authors compare BAGEL with other models on the KRIS-Bench evaluation suite, which assesses capabilities in attribute perception, spatial perception, temporal prediction, social science, natural science, logical reasoning, and instruction decomposition. Results show that BAGEL with self-CoT achieves the highest overall score of 11.9, significantly outperforming other open-source models and approaching the performance of private models like GPT-4o.
The authors compare the performance of various models on multimodal understanding benchmarks, with BAGEL and its variants achieving higher scores than specialized generation models and other unified models. BAGEL w/ Self-CoT achieves the highest overall score of 0.70, significantly outperforming the standard BAGEL model and other state-of-the-art models, indicating that reasoning enhances multimodal understanding capabilities.
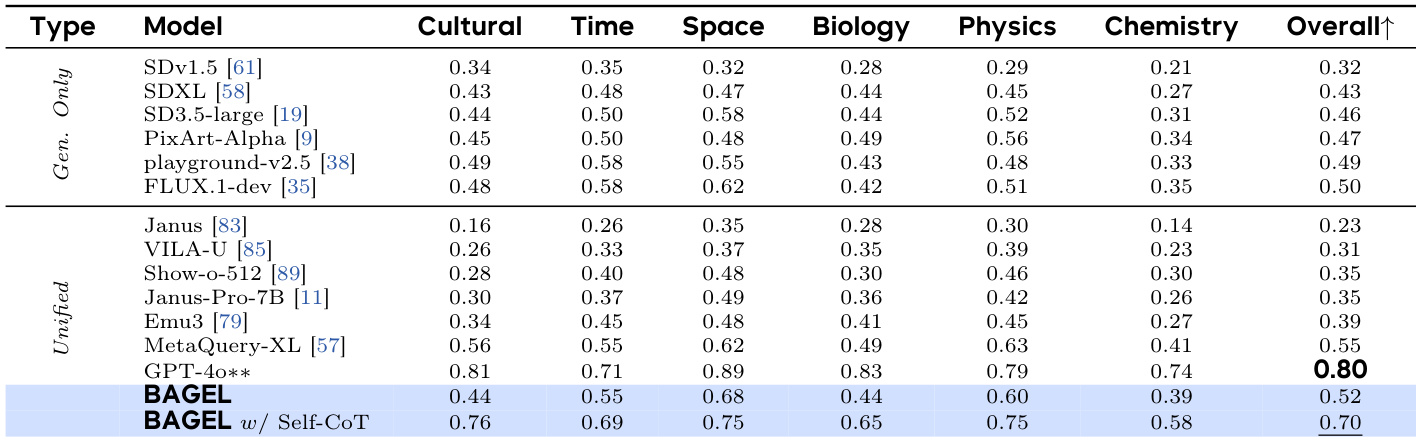
The authors compare BAGEL to existing models on the GEdit-Bench, a benchmark for classical image editing tasks. Results show that BAGEL achieves an overall score of 0.88, matching the best-performing model FLUX-1-dev and outperforming other unified models, indicating strong competitive performance in image editing.
The authors compare BAGEL with private models and open-source models on the KRIS-Bench, evaluating performance across factual, conceptual, and procedural reasoning tasks. Results show that BAGEL achieves the highest overall score among open-source models, with a significant improvement when using self-CoT reasoning, particularly in procedural and conceptual reasoning.
The authors compare the performance of BAGEL and other models on the IntelligentBench evaluation suite, which assesses complex multimodal reasoning in image editing. Results show that BAGEL achieves a score of 44.9, while the enhanced version with self-generated chain-of-thought reasoning (BAGEL w/ Self-CoT) attains a significantly higher score of 55.3, outperforming all open-source models and approaching the performance of private models.
