Command Palette
Search for a command to run...
Sa2VA: Towards Dense Perceptual Understanding of Images and Videos
Date
Size
465.62 MB
License
Apache 2.0
GitHub
Paper URL
1. Tutorial Introduction

Sa2VA, jointly developed by research teams from UC Merced, ByteDance Seed, Wuhan University, and Peking University, was released on January 7, 2025. Sa2VA is the first unified model for dense perceptual understanding of images and videos. Unlike existing multimodal large-scale language models, which are typically limited to specific modalities and tasks, Sa2VA supports a wide range of image and video tasks, including algebraic segmentation and dialogue, requiring minimal single-instruction fine-tuning. Related paper results are as follows: Sa2VA: Marrying SAM2 with LLaVA for Dense Grounded Understanding of Images and Videos .
This tutorial uses resources for a single card A6000.
2. Project Examples



3. Operation steps
1. After starting the container, click the API address to enter the Web interface
If "Bad Gateway" is displayed, it means the model is initializing. Since the model is large, please wait about 1-2 minutes and refresh the page.
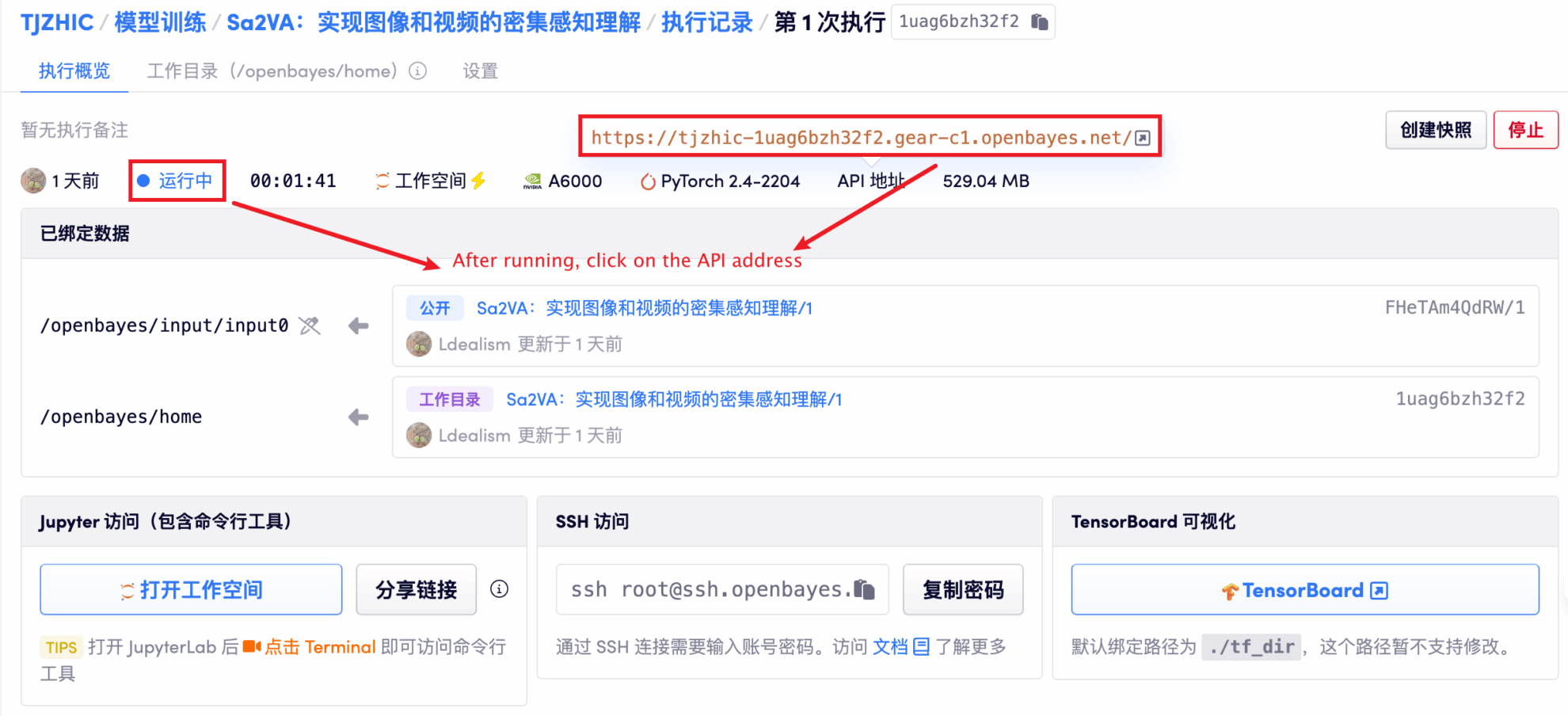
2. Once you enter the web page, you can interact with the model
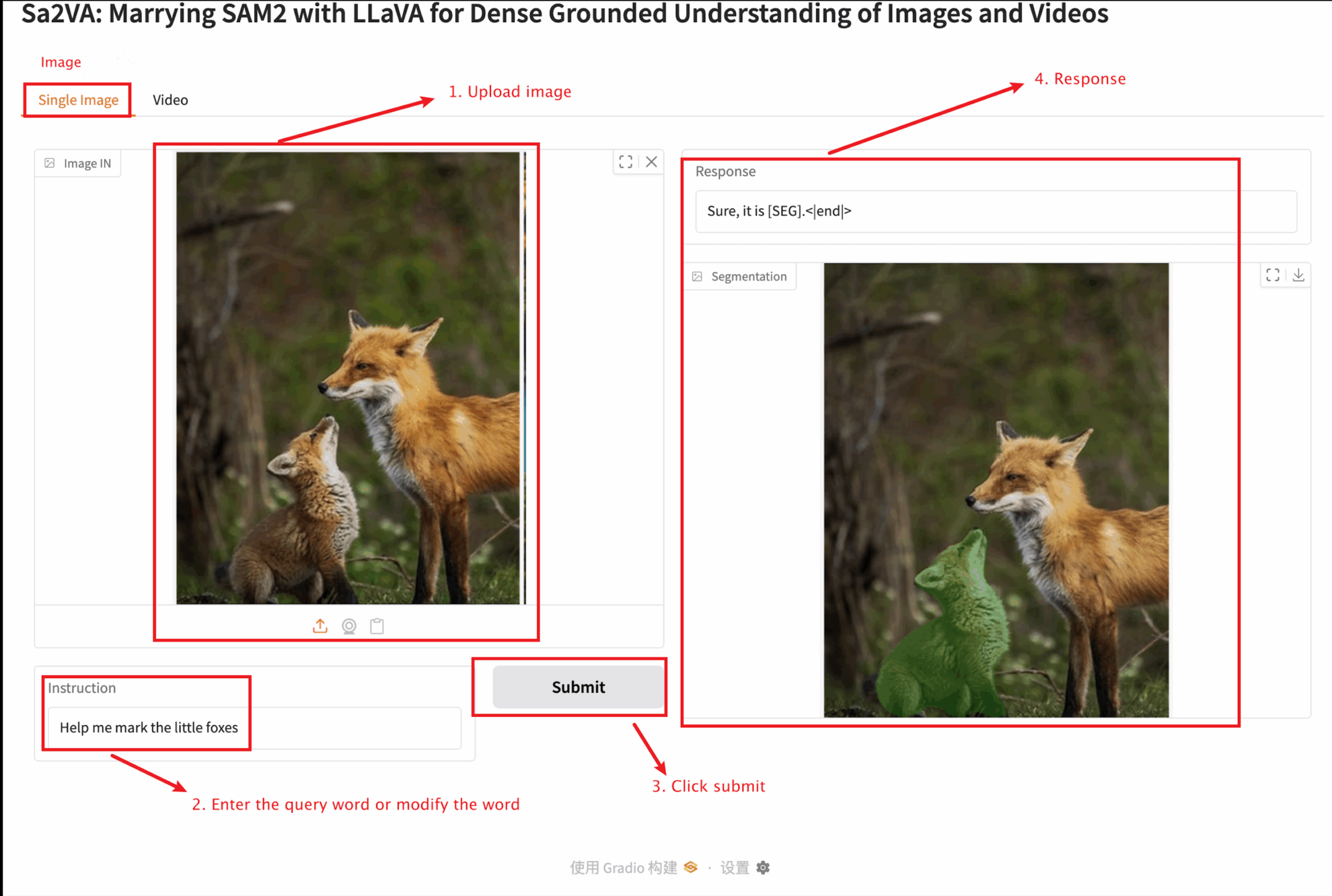
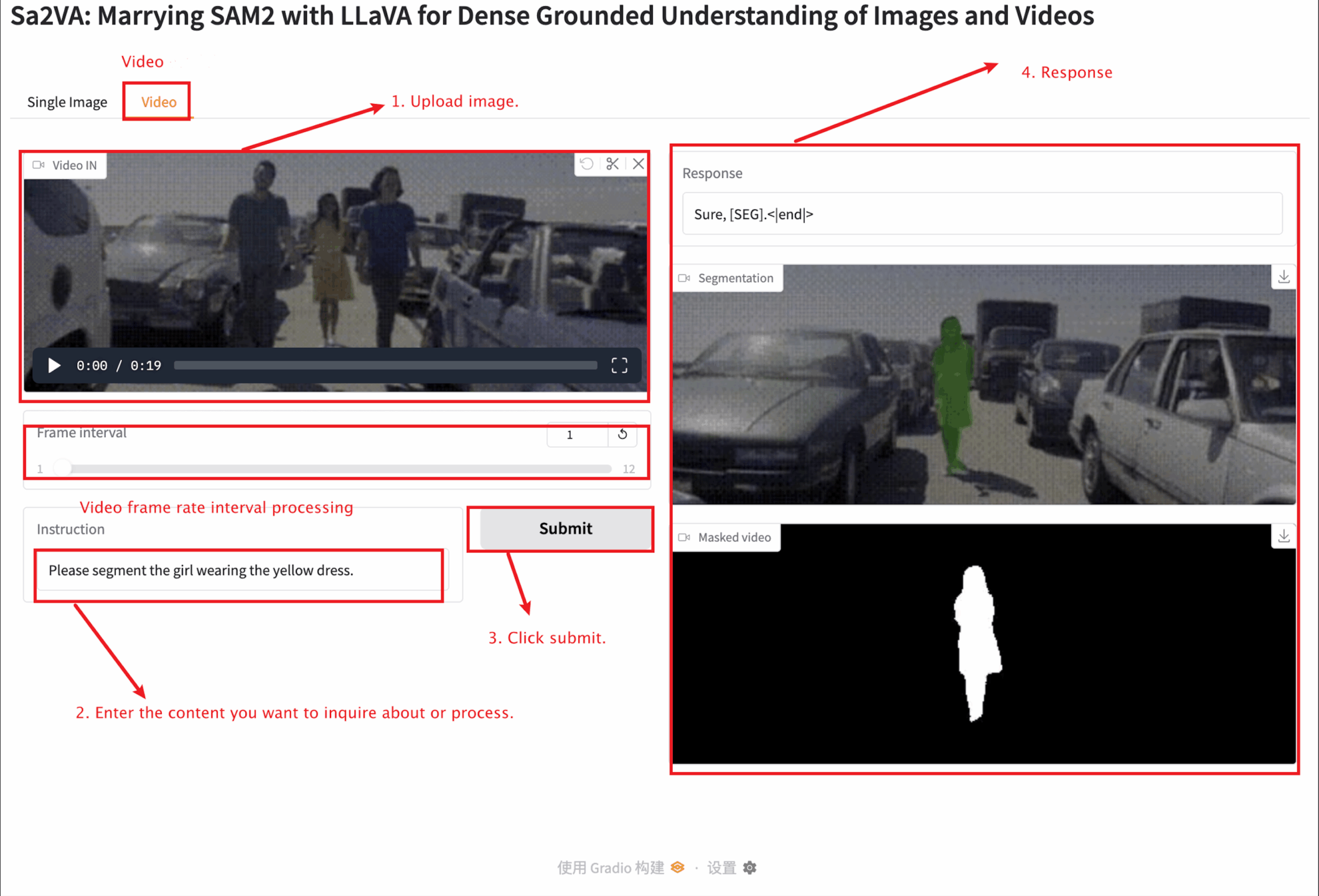
This tutorial provides two module tests: Single image and video modules.
The uploaded image size should not exceed 10 MB, the uploaded video length should not exceed 1 minute, and the video size should not exceed 50 MB, otherwise it may cause the model to run slowly or report errors.
Important parameter description:
Single image
Video
4. Discussion
🖌️ If you see a high-quality project, please leave a message in the background to recommend it! In addition, we have also established a tutorial exchange group. Welcome friends to scan the QR code and remark [SD Tutorial] to join the group to discuss various technical issues and share application effects↓

V. Citation Information
Thanks to Github user zhangjunchang For the deployment of this tutorial, the project reference information is as follows:
@article{pixel_sail,
title={Sa2VA: Marrying SAM2 with LLaVA for Dense Grounded Understanding of Images and Videos},
author={Zhang, Tao and Li, Xiangtai and Huang, Zilong and Li, Yanwei and Lei, Weixian and Deng, Xueqing and Chen, Shihao and Ji, Shunping and and Feng, Jiashi},
journal={arXiv},
year={2025}
}
@article{sa2va,
title={Sa2VA: Marrying SAM2 with LLaVA for Dense Grounded Understanding of Images and Videos},
author={Yuan, Haobo and Li, Xiangtai and Zhang, Tao and Huang, Zilong and Xu, Shilin and Ji, Shunping and Tong, Yunhai and Qi, Lu and Feng, Jiashi and Yang, Ming-Hsuan},
journal={arXiv},
year={2025}
}Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.