Command Palette
Search for a command to run...
CPU Deployment NeuTTS-Air Voice Cloning Model
1. Tutorial Introduction

NeuTTS-Air is an end-to-end speech synthesis model (TTS) released by Neuphonic in October 2025. Based on the 0.5B Qwen LLM backbone and NeuCodec audio codec, it demonstrates few-shot learning capabilities in on-device deployment and instant voice cloning. System evaluation shows that NeuTTS Air has reached the SOTA level among open source models, especially in ultra-realistic synthesis and real-time inference benchmarks. It can also generalize to new scenarios such as embedded agents and style transfer, support 3-second audio cloning, and generate natural conversation content. Post-training introduces GGML/ONNX support and watermarking mechanism, leading the open source field in on-device TTS and power optimization evaluation, and some scenarios are comparable to closed-source models.
This tutorial uses CPU resources, the model only supports English, and it takes more than half a minute to synthesize a voice. If you want to experience faster processing speed, you can use a single card RTX 5090 Clone TutorialNeuTTS-Air: A lightweight and efficient voice cloning model".
2. Project Examples
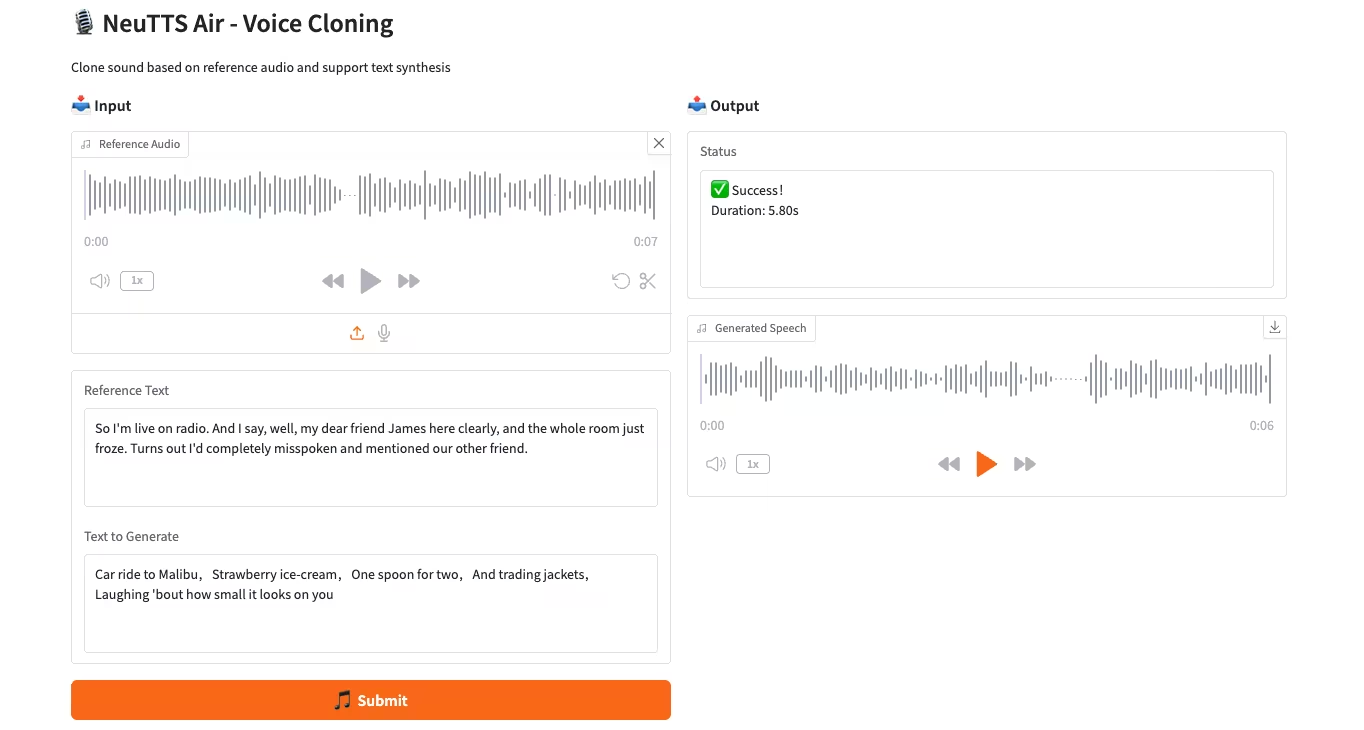
3. Operation steps
1. After starting the container, click the API address to enter the Web interface
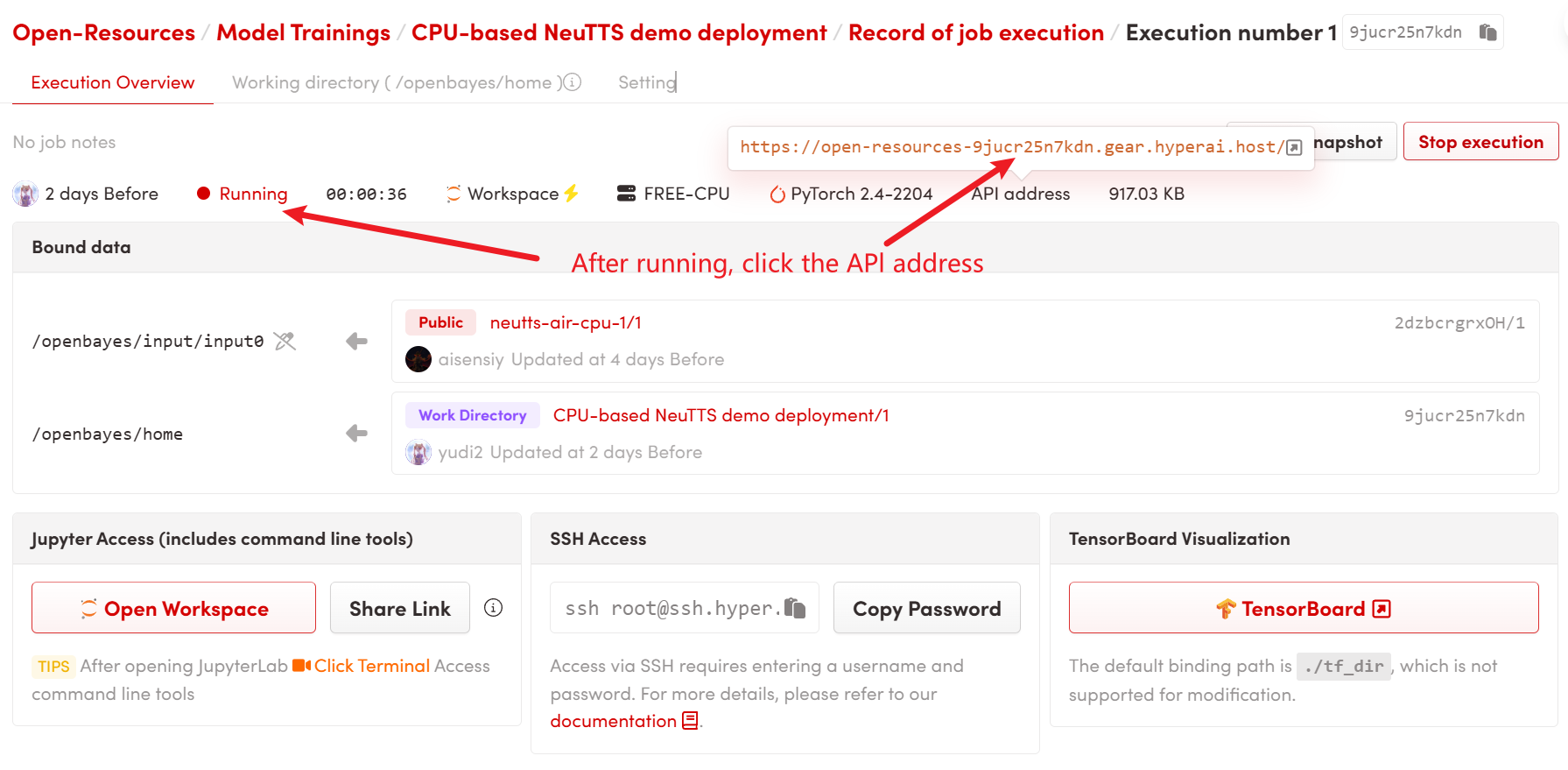
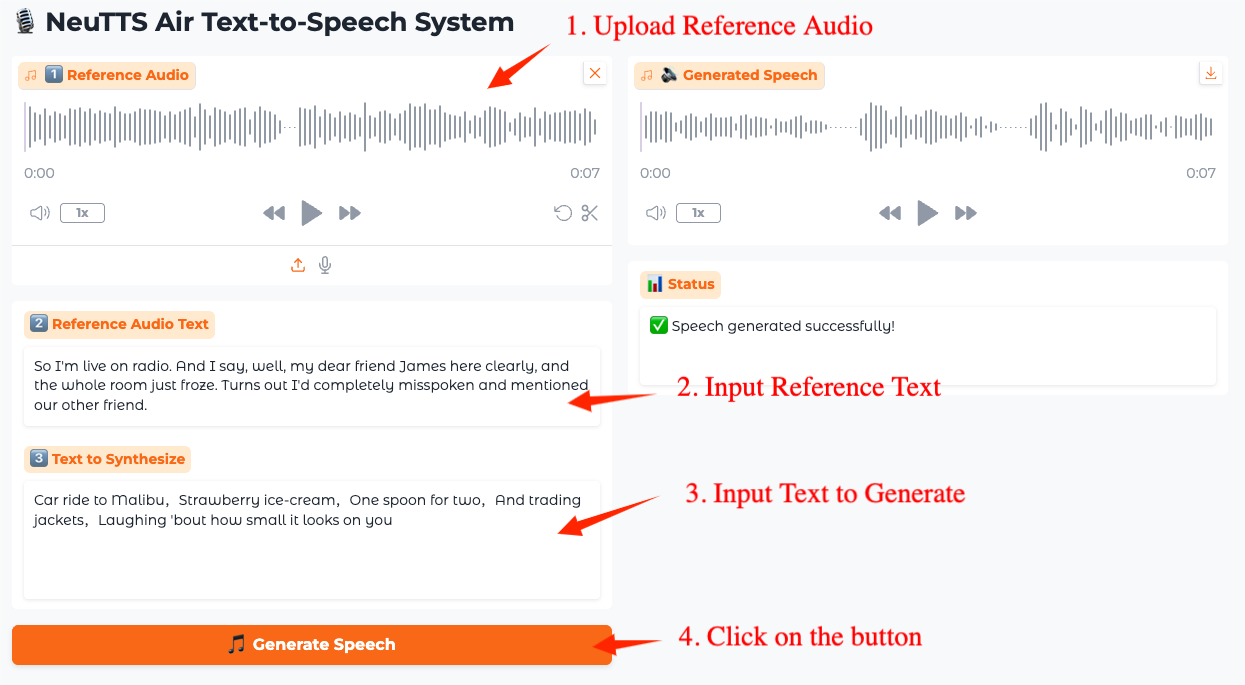
2. Once you enter the webpage, you can use the model
If "Bad Gateway" is displayed, it means that the code is executing in the background. Please wait about 2-3 minutes and refresh the page.
When using the Safari browser, the audio may not be played directly and needs to be downloaded before playing.
How to use
The minimum input audio length is 3 seconds, and the recommended length is 3 to 15 seconds. The maximum length of the output audio is approximately 30 seconds
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.