Command Palette
Search for a command to run...
CL-bench: A Benchmark for Context Learning
CL-bench: A Benchmark for Context Learning
Abstract
Current language models (LMs) excel at reasoning over prompts using pre-trained knowledge. However, real-world tasks are far more complex and context-dependent: models must learn from task-specific context and leverage new knowledge beyond what is learned during pre-training to reason and resolve tasks. We term this capability context learning, a crucial ability that humans naturally possess but has been largely overlooked. To this end, we introduce CL-bench, a real-world benchmark consisting of 500 complex contexts, 1,899 tasks, and 31,607 verification rubrics, all crafted by experienced domain experts. Each task is designed such that the new content required to resolve it is contained within the corresponding context. Resolving tasks in CL-bench requires models to learn from the context, ranging from new domain-specific knowledge, rule systems, and complex procedures to laws derived from empirical data, all of which are absent from pre-training. This goes far beyond long-context tasks that primarily test retrieval or reading comprehension, and in-context learning tasks, where models learn simple task patterns via instructions and demonstrations. Our evaluations of ten frontier LMs find that models solve only 17.2% of tasks on average. Even the best-performing model, GPT-5.1, solves only 23.7%, revealing that LMs have yet to achieve effective context learning, which poses a critical bottleneck for tackling real-world, complex context-dependent tasks. CL-bench represents a step towards building LMs with this fundamental capability, making them more intelligent and advancing their deployment in real-world scenarios.
One-sentence Summary
Researchers from Hunyuan Team at Tencent and Fudan University propose CL-bench, a real-world benchmark exposing LMs’ poor context learning—acquiring new knowledge from context to solve complex tasks—revealing even GPT-5.1 solves only 23.7%, highlighting a critical gap for deploying LMs in practical, context-dependent scenarios.
Key Contributions
- The paper identifies a critical gap in current language models: their inability to perform “context learning”—learning and applying new, task-specific knowledge from context rather than relying solely on pre-trained knowledge, a capability essential for real-world, context-dependent tasks.
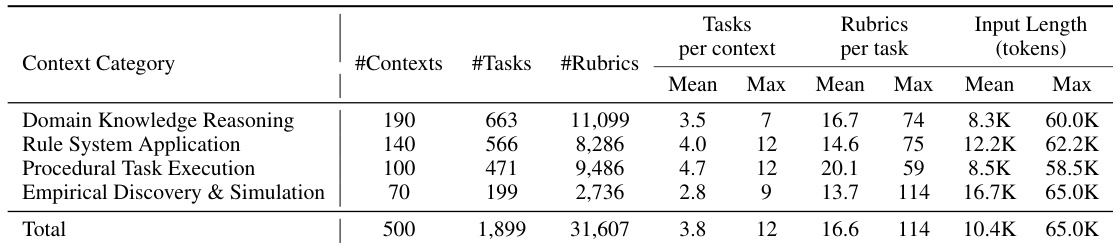
- To evaluate this capability, the authors introduce CL-bench, a rigorously constructed benchmark with 500 complex contexts, 1,899 tasks, and 31,607 verification rubrics, all designed by domain experts to require models to learn from context without external retrieval, covering domains like rule systems, procedures, and empirical discovery.
- Evaluations across ten frontier LMs reveal severe limitations, with models solving only 17.2% of tasks on average and the top model (GPT-5.1) achieving just 23.7%, highlighting that context learning remains a fundamental bottleneck for real-world deployment.
Introduction
The authors leverage the growing gap between current language models’ reliance on pre-trained knowledge and the real-world need for dynamic context learning—where models must absorb and apply new, task-specific information from complex contexts. Prior benchmarks focus on retrieval, reading comprehension, or simple in-context pattern learning, failing to evaluate true knowledge acquisition from rich, domain-specific material. To address this, they introduce CL-bench: a contamination-free, expert-crafted benchmark with 500 contexts, 1,899 tasks, and 31,607 rubrics that force models to learn new rules, procedures, or empirical laws directly from context. Evaluations show even top models like GPT-5.1 solve only 23.7% of tasks, exposing a critical bottleneck in context learning and calling for focused research to enable models to adapt like humans in real-world scenarios.
Dataset
-
The authors use CL-bench, a benchmark designed to evaluate language models’ ability to learn from context and apply that knowledge to solve complex, real-world tasks. The dataset is built around entirely new or niche knowledge not typically found in pre-training corpora.
-
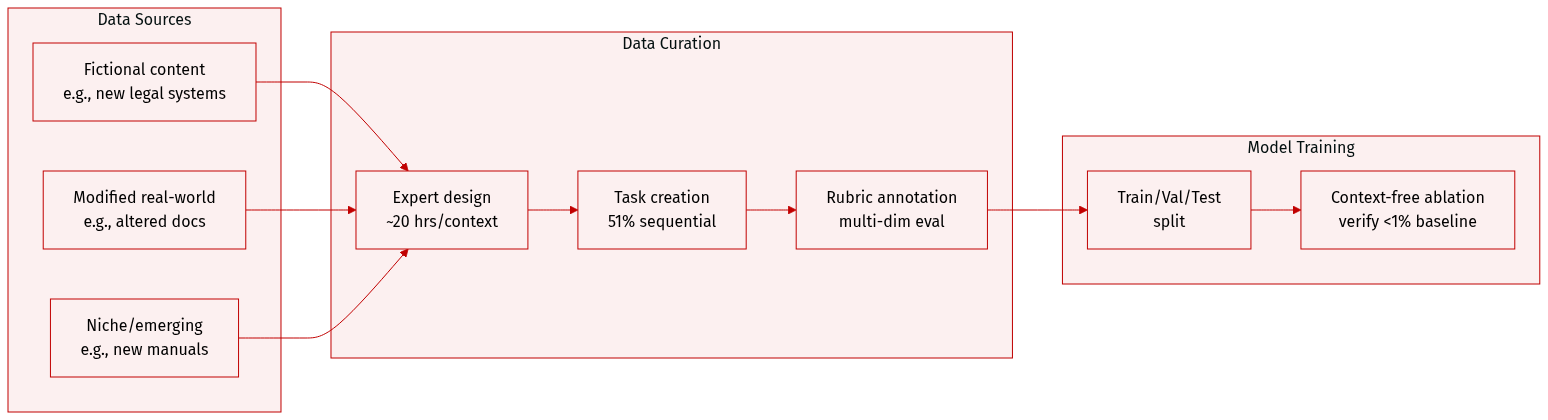
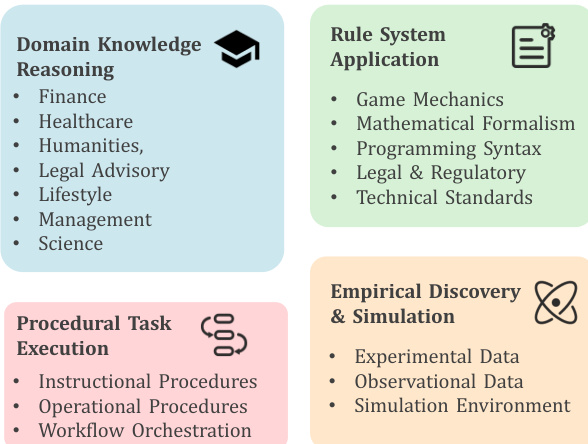
CL-bench contains 18 subcategories across 4 main context categories: Domain Knowledge Reasoning (e.g., legal, financial, scientific), Rule System Application (e.g., game mechanics, programming syntax), Procedural Task Execution (e.g., manuals, workflows), and Empirical Discovery & Simulation (e.g., experimental data, simulations). Each context includes multiple tasks, 51.1% of which are sequential, requiring models to build on prior task solutions.
-
Contexts are constructed in three stages by domain experts: (1) design novel or modified content (fictional, altered real-world, or emerging/niche material), (2) create context-dependent tasks requiring genuine learning, and (3) annotate with detailed rubrics. Each context takes ~20 expert hours to build. The dataset is contamination-free: models achieve <1% task-solving rate without context, confirming reliance on provided knowledge.
-
Tasks are evaluated using multi-dimensional rubrics. Input length varies, and contexts include structured data (e.g., tables, JSON, code), plain text, and mixed formats. No cropping is mentioned; instead, full context is provided. Metadata includes task UID, model name, context category/subcategory, and task description. Processing includes expert validation and ablation testing to ensure context dependence.
Method
The authors leverage a dual-path framework that distinguishes between context-driven learning and prompt-guided reasoning, each tailored to different operational regimes along a complexity axis. As shown in the figure below, the architecture bifurcates into two primary pathways: one anchored in context engineering for learning from complex, novel inputs, and another grounded in prompt engineering for reasoning over pre-trained knowledge under constrained conditions.
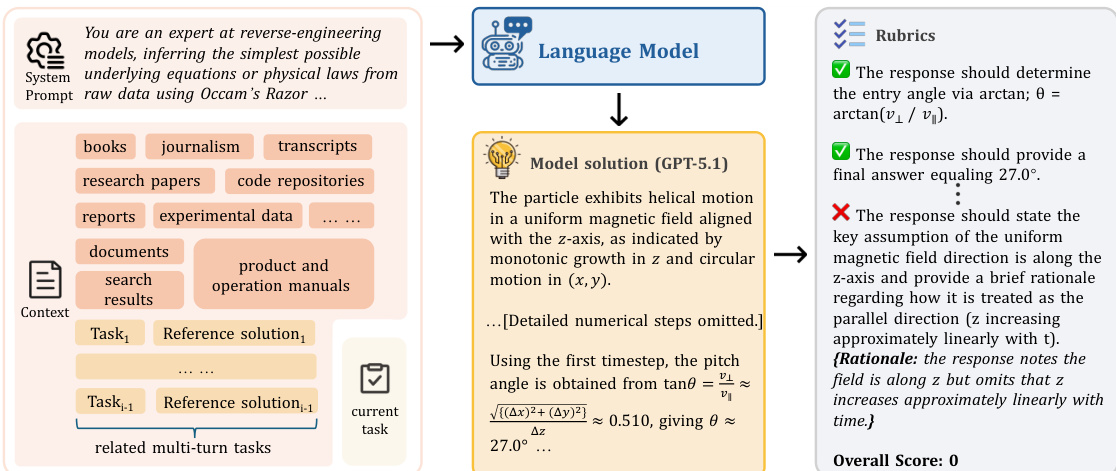
In the context engineering pathway, the system ingests heterogeneous sources—such as research papers, operational manuals, and experimental data—to infer underlying physical or mathematical laws. The model, exemplified by GPT-5.1 in the workflow, processes these inputs under a system prompt that frames the task as reverse-engineering from raw data. The output is evaluated against rubrics that enforce physical consistency, such as deriving the entry angle via θ=arctan(v⊥/v∥), and penalize omissions of key assumptions, as seen in the rationale for omitting the linear growth of z with time.
The prompt engineering pathway operates under strict rule systems, where the model executes predefined procedural logic without inferring new functions. This is evident in domains such as logistics or regulatory compliance, where the system must adhere to documented APIs and safety protocols. For instance, when faced with an urgent drone delivery request involving Class-4 Hazmat, the model refuses to invoke non-existent functions like force_launch_override() and instead proposes a compliant alternative using auth_handshake() and Safety_verify_weather_conditions(), as evaluated against rubrics that enforce legal and safety constraints.
The framework’s modularity allows it to span diverse domains—from finance and healthcare to programming syntax and game mechanics—by switching between context-rich inference and rule-bound execution. Each pathway is governed by distinct evaluation criteria: context learning is scored on physical or mathematical fidelity, while prompt-based reasoning is validated against procedural correctness and safety compliance. This design enables the system to scale toward real-world complexity without conflating learning from novel data with execution under fixed constraints.

The training process implicitly enforces this duality by exposing the model to both open-ended context learning tasks and tightly constrained procedural tasks, each with explicit rubrics that shape the output toward domain-specific correctness. No external data or assumptions are introduced; all reasoning is grounded in the provided documentation, ensuring reproducibility and adherence to operational boundaries.
Experiment
- CL-bench introduces task-level rubrics with binary yes/no criteria to reliably evaluate complex, multi-solution tasks, validated by expert design and inter-verifier agreement exceeding 90%.
- GPT-5.1 serves as a reliable verifier, showing high consistency with human annotators and minimal self-evaluation bias when compared to Claude Opus 4.5 and Qwen-3-Max.
- Context learning remains a major challenge: even top models achieve only 17–24% task-solving rates, with no model surpassing 30%, highlighting a gap in real-world deployment readiness.
- Task difficulty varies by category: domain knowledge and procedural tasks are more tractable; empirical discovery and simulation are hardest, with ~11% success and high instability due to inductive reasoning demands.
- Within categories, subcategories reveal fine-grained gaps: e.g., legal & regulatory tasks outperform mathematical formalism by over 15%, and observational data is harder than experimental data.
- Long context and instruction following are necessary but insufficient; models like GPT-5.2 underperform GPT-5.1 despite newer architecture, often losing coherence or violating constraints in extended contexts.
- Increasing reasoning effort yields modest gains for most models (e.g., 2.5% for GPT-5.1), but benefits diminish or reverse for some, and become more critical as context length increases.
- Context length consistently degrades performance across all models; solving rates drop from 25–35% at short lengths to 5–10% beyond 32K tokens, with GPT-5.1 showing relative robustness.
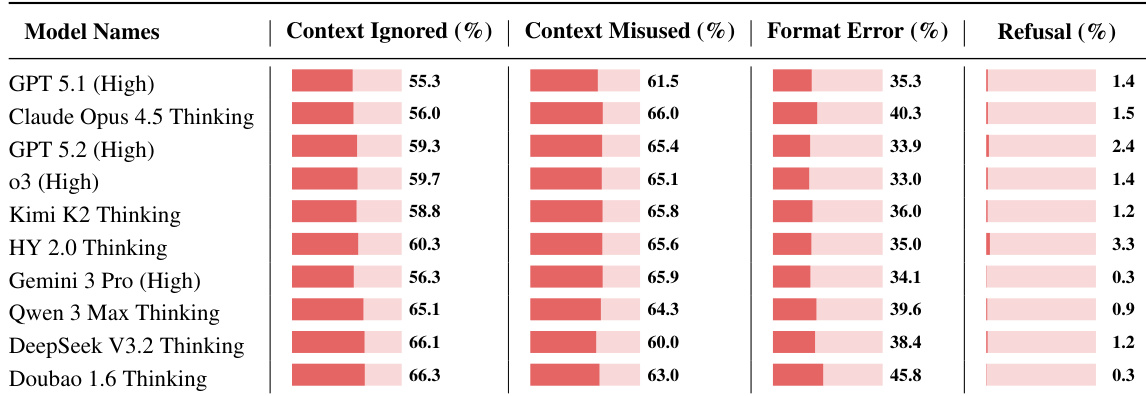
- Models frequently fail by ignoring or misapplying context (context misused >60% of failures), and format errors persist even in top models (e.g., 35–40% for GPT-5.1 and Claude Opus).
- Qualitative cases confirm models struggle with deep context integration: they may detect violations but fail to retrieve or apply relevant content, especially under complex or structured constraints.
- Removing context reduces GPT-5.1’s solving rate to 0.9%, proving CL-bench tasks require in-context learning and cannot be solved via pre-trained knowledge alone.
- Knowledge type and structure significantly affect performance: rule-based tasks (e.g., legal & regulatory) are easier than judgment-based ones (e.g., legal advisory), even within the same domain.
- Models often satisfy surface constraints (e.g., refusal, formatting) but fail on deeper requirements, treating constraints as terminal rather than reformulable, leading to incomplete or non-functional outputs.
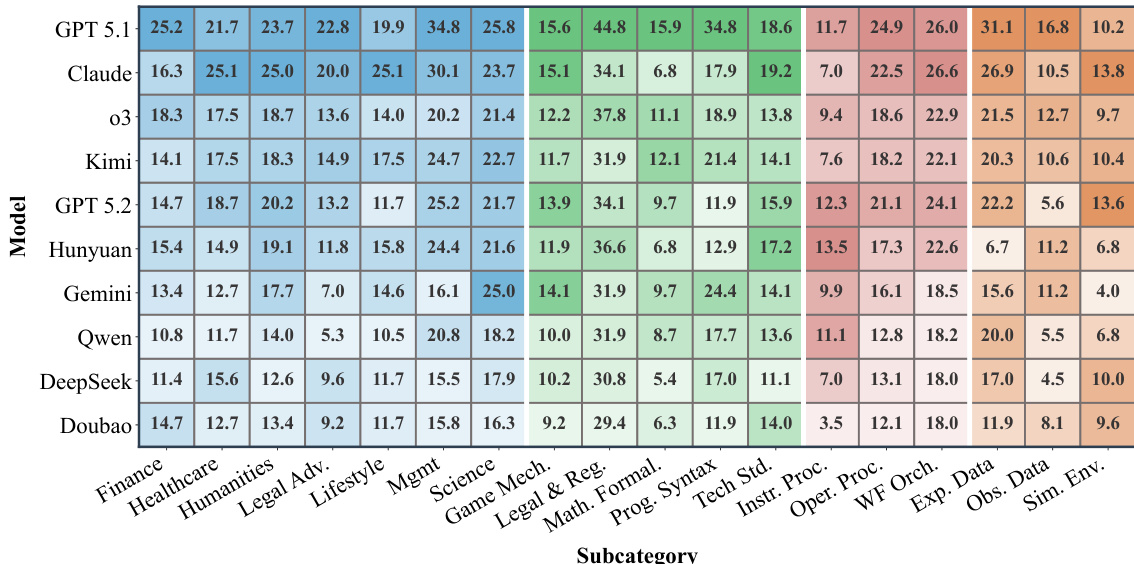
Results show that even the strongest language models solve fewer than 24% of context learning tasks on average, with performance varying significantly across task types. Models consistently struggle most with empirical discovery and simulation tasks, which require inductive reasoning, while performing relatively better on domain knowledge and procedural tasks that rely on deductive application of explicit rules. The findings indicate that current models, despite advanced reasoning and long-context capabilities, still face fundamental limitations in reliably learning, retaining, and applying novel contextual knowledge under strict evaluation criteria.

The authors use a detailed rubric-based evaluation framework to assess language models on complex context learning tasks, with each task verified through multiple binary criteria designed by domain experts. Results show that even top models solve fewer than 24% of tasks on average, highlighting that context learning remains a significant challenge despite advances in long-context and reasoning capabilities. Performance varies notably across categories, with empirical discovery and simulation proving hardest, while domain knowledge and procedural tasks are relatively more tractable.
Results show that even the strongest language models solve fewer than 24% of tasks on average, highlighting that context learning remains a significant challenge despite advances in long-context and reasoning capabilities. Performance varies widely across subcategories, with models excelling in rule-based legal and procedural tasks but struggling with empirical discovery and simulation, where inductive reasoning from data proves particularly difficult. Most models frequently fail by misapplying or ignoring contextual information, and even top performers exhibit high rates of format and instruction-following errors, indicating that reliably learning and applying novel knowledge from context is still beyond current model capabilities.
Results show that even top-performing language models frequently fail to fully utilize or correctly apply contextual information, with context misuse and format errors dominating failure modes across all evaluated systems. The data confirms that long-context reasoning and strict instruction following remain significant bottlenecks, as models often overlook critical details or violate structural requirements despite possessing the necessary knowledge.