Command Palette
Search for a command to run...
Qwen3-Omni-30B-A3B-Captioner: Audio Description Large Model
Date
Size
1.37 GB
License
Apache 2.0
GitHub
Paper URL
1. Tutorial Introduction

Qwen3-Omni-30B-A3B-Captioner is a large audio description model released by the Alibaba Tongyi Qianwen team in September 2025. Without any prompts, the model automatically generates accurate and comprehensive descriptions for complex speech, ambient sounds, music, and film and television sound effects. It can identify speaker emotions, musical elements (such as style and instruments), and sensitive information. It is suitable for audio content analysis, security auditing, intent recognition, audio editing, and other fields. Related papers are "Qwen3-Omini Technical Report".
This tutorial uses a single RTX A6000 card as the resource.
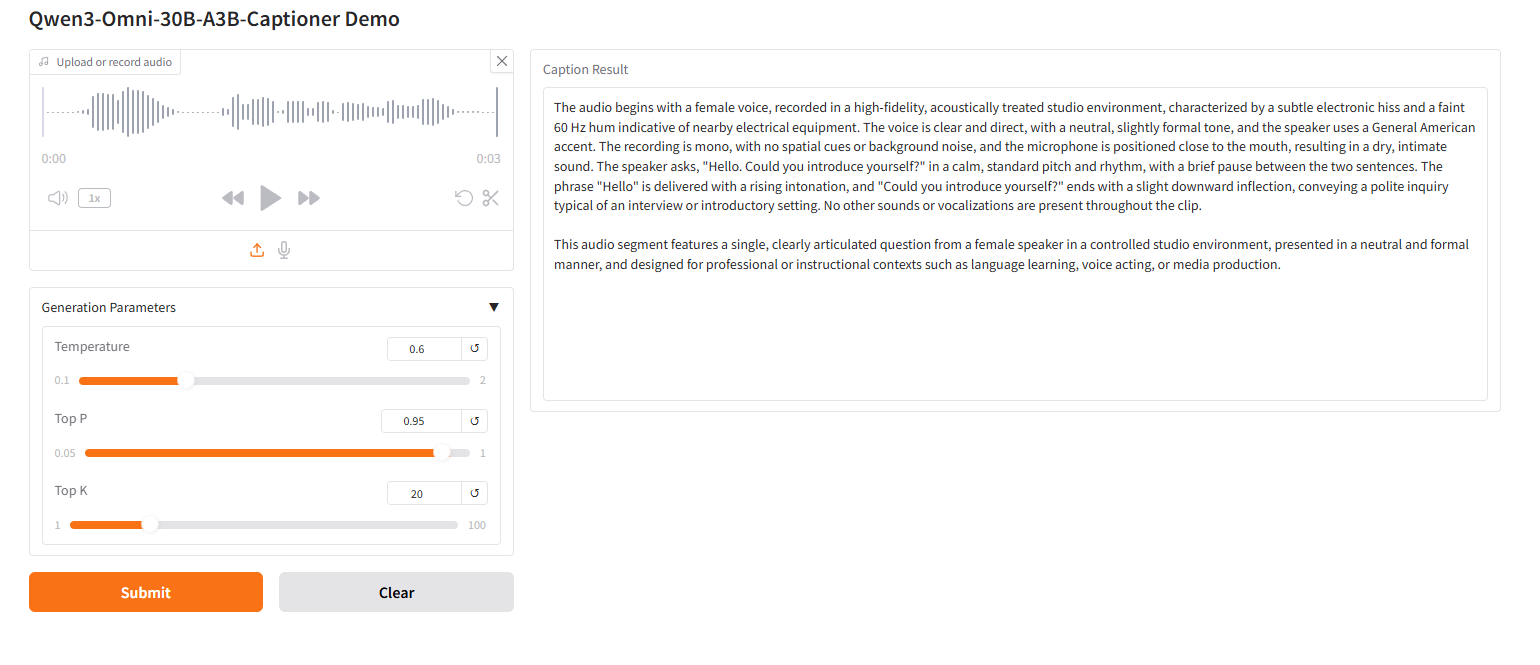
2. Project Examples
3. Operation steps
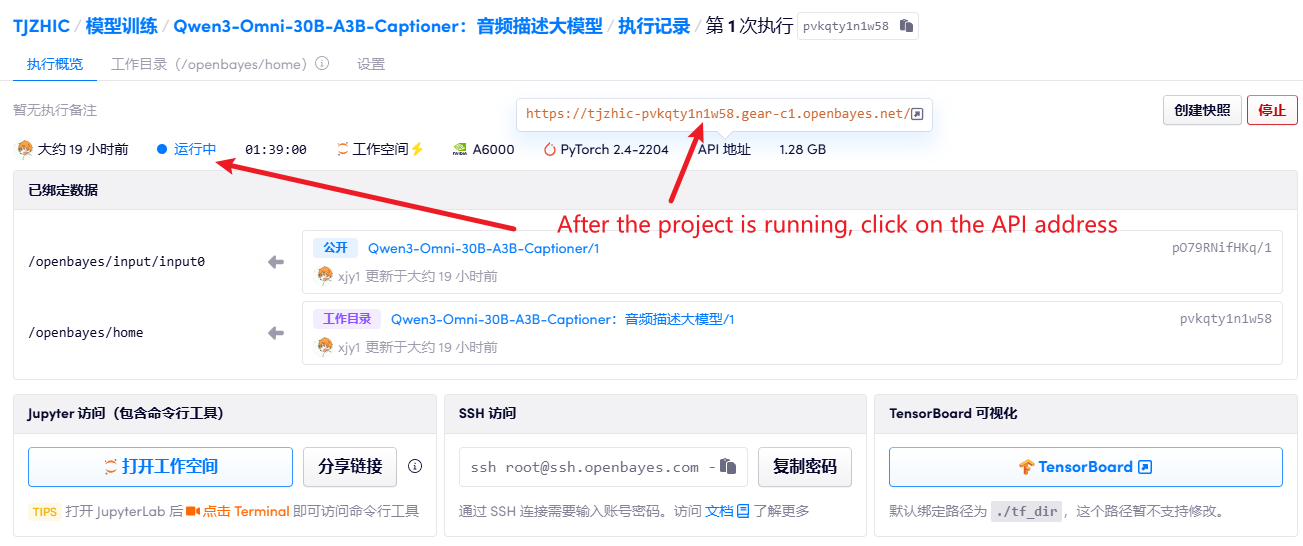
1. After starting the container, click the API address to enter the Web interface
2. Usage steps
If "Bad Gateway" is displayed, it means the model is initializing. Since the model is large, please wait about 2-3 minutes and refresh the page. Note: Audio length is limited to 30 seconds. Generating results takes approximately 3-5 minutes.
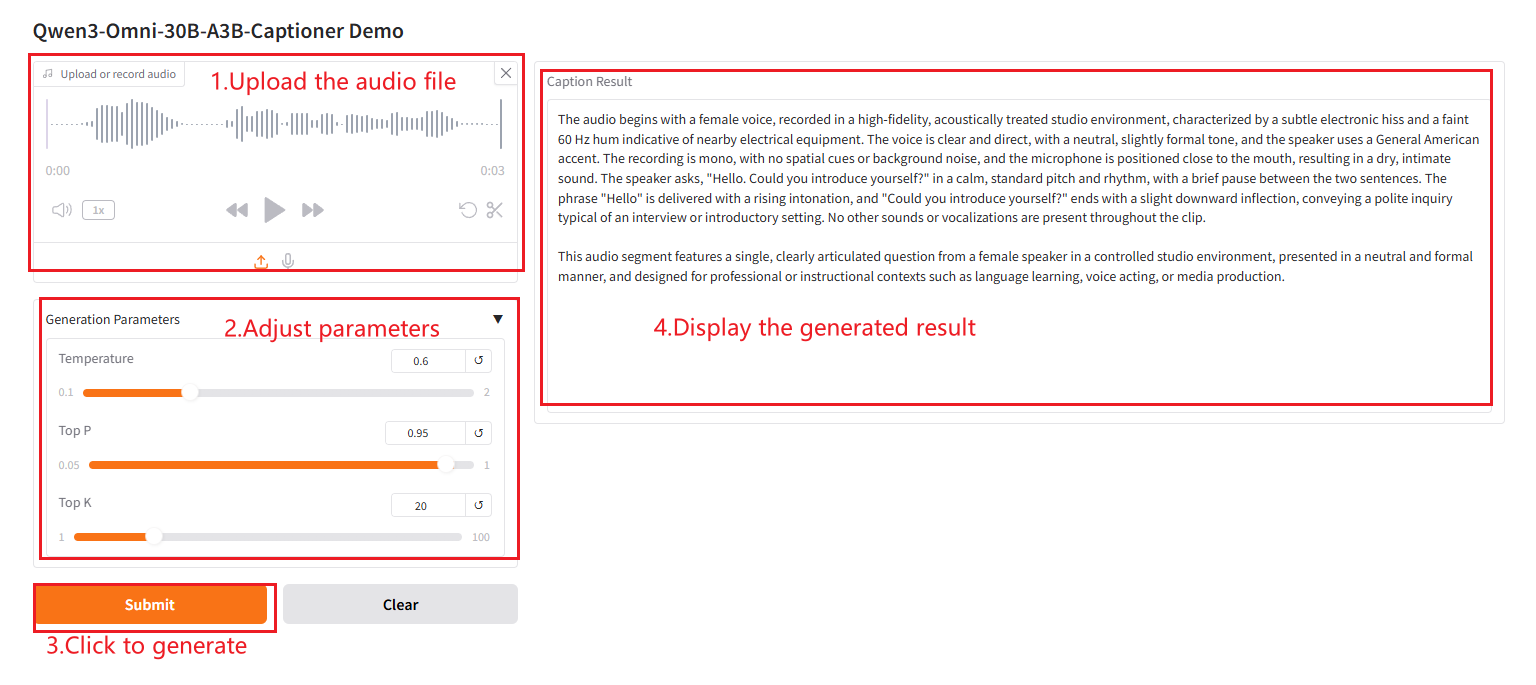
Parameter Description
- Temperature: The smaller the value, the more "conservative" and certain the subtitles are; the larger the value, the more random and innovative they are.
- Top-p: Only select from the "high-scoring words" whose probability accumulates to p. The smaller p is, the fewer candidates there are, and the more conservative the text is.
- Top-k: Only keep the k words with the highest probability. The smaller k is, the fewer candidates there are and the more conservative the text is.
4. Discussion
🖌️ If you see a high-quality project, please leave a message in the background to recommend it! In addition, we have also established a tutorial exchange group. Welcome friends to scan the QR code and remark [SD Tutorial] to join the group to discuss various technical issues and share application effects↓

Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.