HyperAI
HyperAI
主区域
首页
GPU
控制台
文档
价格
Pulse
报道
资源
论文
教程
数据集
百科
基准测试
SOTA
大语言模型(LLM)
GPU 排行榜
社区
活动
开源
实用工具
搜索
关于
服务条款
隐私政策
中文
HyperAI
HyperAI
Toggle Sidebar
⌘
K
Command Palette
Search for a command to run...
登录
HyperAI
论文
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势
HyperAI
HyperAI
主区域
首页
GPU
控制台
文档
价格
Pulse
报道
资源
论文
教程
数据集
百科
基准测试
SOTA
大语言模型(LLM)
GPU 排行榜
社区
活动
开源
实用工具
搜索
关于
服务条款
隐私政策
中文
HyperAI
HyperAI
Toggle Sidebar
⌘
K
Command Palette
Search for a command to run...
登录
HyperAI
论文
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势
HiPO:面向LLMs动态推理的混合策略优化
推理
强化学习
Ken Deng, Zizheng Zhan, Wen Xiang, et al.
SERES:基于语义感知的稀疏视角神经重建
3D 生成
计算机视觉
Bo Xu, Yuhu Guo, Yuchao Wang, et al.
SDAR:一种用于可扩展序列生成的协同扩散-自回归范式
扩散模型
模型训练
Shuang Cheng, Yihan Bian, Dawei Liu, et al.
MultiPL-MoE:通过混合专家模型扩展大型语言模型的多编程语言能力
LLM
代码生成
Qing Wang, Xue Han, Jiahui Wang, et al.
CapRL:通过强化学习激发密集图像描述能力
图像描述
视觉问答
Long Xing, Xiaoyi Dong, Yuhang Zang, et al.
通过离散扩散发散指令实现超快速语言生成
扩散模型
文本生成
Haoyang Zheng, Xinyang Liu, Cindy Xiangrui Kong, et al.
DisCO:通过判别约束优化强化大型推理模型
强化学习
推理
Gang Li, Ming Lin, Tomer Galanti, et al.
QSVD:面向低精度视觉-语言模型中统一查询-键-值权重压缩的高效低秩近似
Transformer
视觉问答
Yutong Wang, Haiyu Wang, Sai Qian Zhang
嵌套学习:深度学习架构的幻觉
深度学习
自然语言处理
Ali Behrouz, Meisam Razaviyayn, Peiling Zhong, et al.
SAM 3D:将图像中的任意内容3D化
3D 生成
3D 模型
SAM 3D Team, Xingyu Chen, Fu-Jen Chu, et al.
视频即答案:基于联合GRPO的下一视频事件预测与生成
视频生成
文生视频
Junhao Cheng, Liang Hou, Xin Tao, et al.
首帧是视频内容定制的首选之地
视频生成
图生视频
Jingxi Chen, Zongxia Li, Zhichao Liu, et al.
基于多模态基础模型的时空智能扩展
多模态
多模态表征
Zhongang Cai, Ruisi Wang, Chenyang Gu, et al.
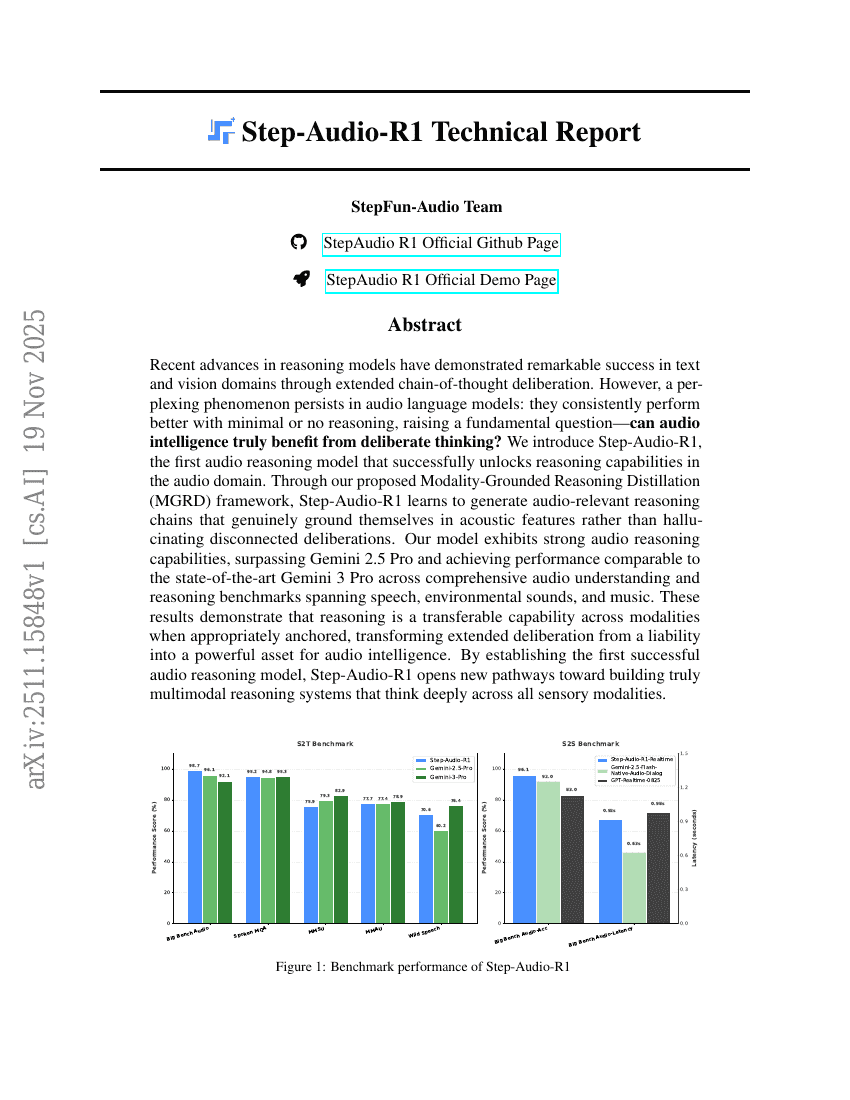
Step-Audio-R1 技术报告
推理
多模态
Fei Tian, Xiangyu Tony Zhang, Yuxin Zhang, et al.
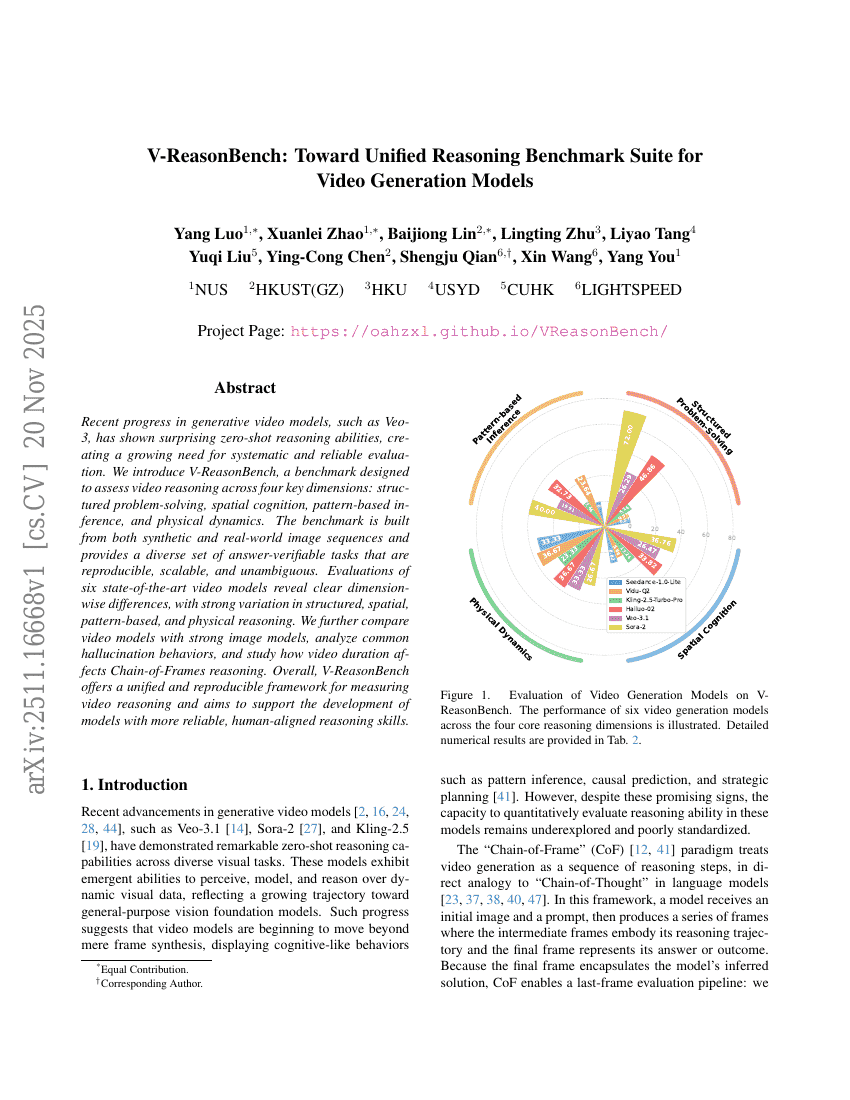
V-ReasonBench:面向视频生成模型的统一推理基准测试套件
基准
视觉问答
Yang Luo, Xuanlei Zhao, Baijiong Lin, et al.
Olmo 3
LLM
代码生成
Allyson Ettinger, Amanda Bertsch, Bailey Kuehl, et al.
GPT-5的早期科学加速实验
AI for Science
推理
Sébastien Bubeck, Christian Coester, Ronen Eldan, et al.
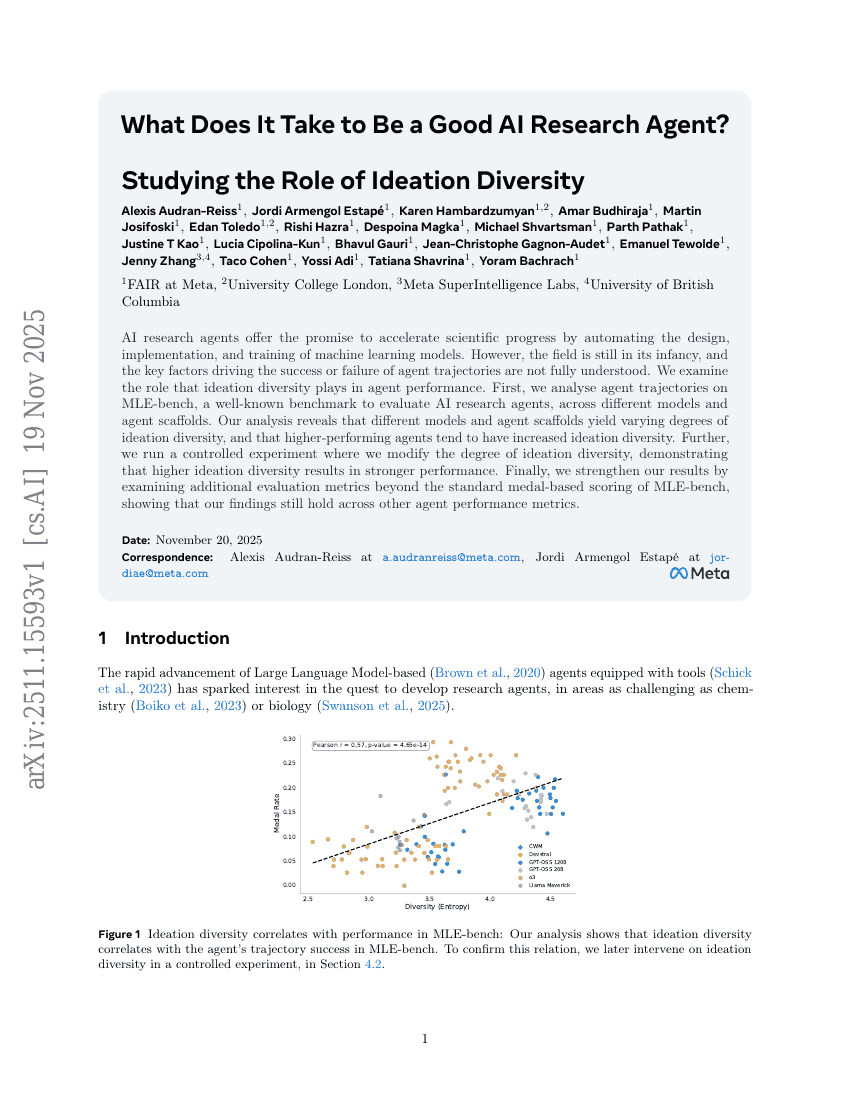
成为优秀的AI研究Agent需要什么?——探究创意多样性的作用
Agent
基准
Alexis Audran-Reiss, Jordi Armengol Estapé, Karen Hambardzumyan, et al.
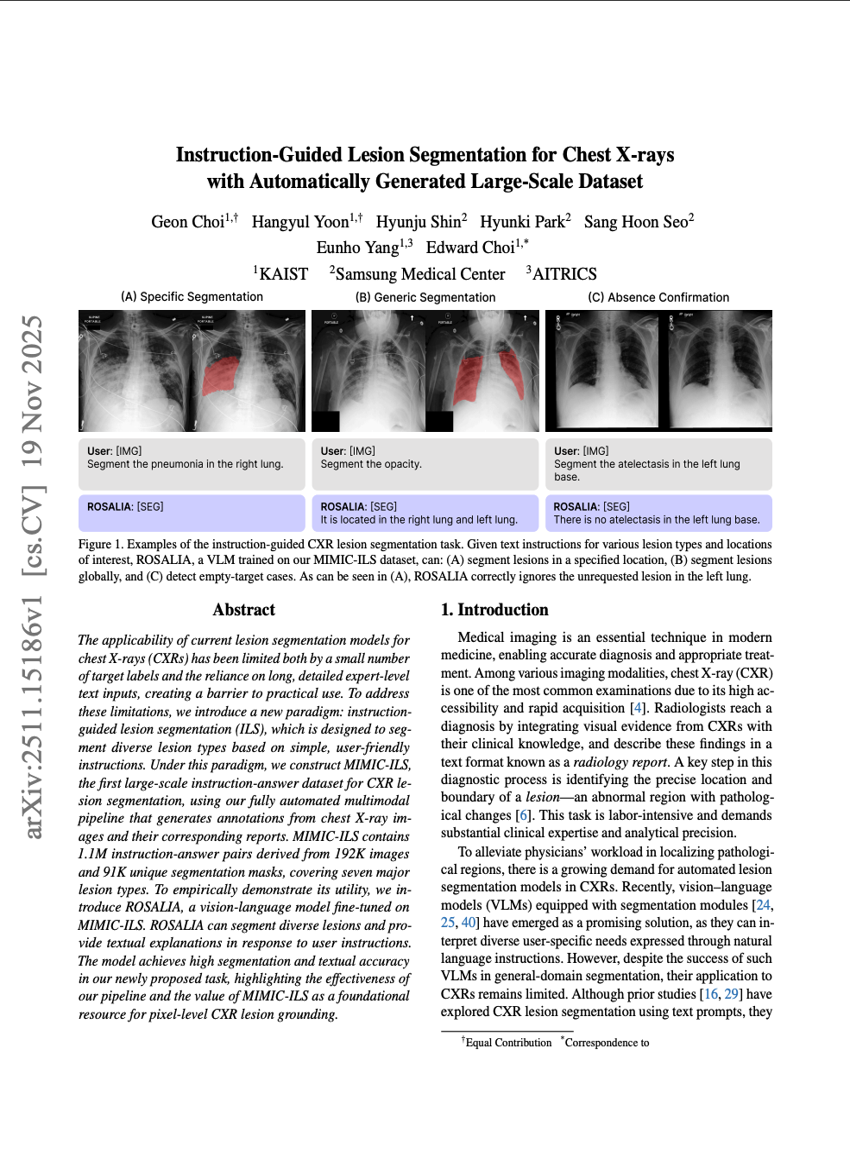
指令引导的胸部X光图像病灶分割方法及其自动构建的大规模数据集
语义分割
多模态
Geon Choi, Hangyul Yoon, Hyunju Shin, et al.
VisPlay:从图像中自演化视觉-语言模型
强化学习
多模态
Yicheng He, Chengsong Huang, Zongxia Li, et al.
通过视频进行推理:首个基于迷宫求解任务对视频模型推理能力的评估
多模态表征
推理
Cheng Yang, Haiyuan Wan, Yiran Peng, et al.
VIDEOP2R:从感知到推理的视频理解
视频理解
多模态表征
Yifan Jiang, Yueying Wang, Rui Zhao, et al.
Kandinsky 5.0:面向图像与视频生成的基础模型家族
文生图
图生视频
Vladimir Arkhipkin, Vladimir Korviakov, Nikolai Gerasimenko, et al.
JAM-2:具有高成功率的类药物抗体的全计算设计
AI for Science
深度学习
Nabla Bio
PathMind:一种基于大型语言模型的知识图谱推理的检索-优先级排序-推理框架
检索增强生成
LLM
Yu Liu, Xixun Lin, Yanmin Shang, et al.
审稿人:超越文本反思,迈向长视频理解中的多模态内省推理
视频理解
推理
Jiaze Li, Hao Yin, Wenhui Tan, et al.
MVI-Bench:面向低视觉语言模型中误导性视觉输入鲁棒性评估的综合性基准
视觉问答
多模态
Huiyi Chen, Jiawei Peng, Dehai Min, et al.
世界模拟器能进行推理吗?Gen-ViRe:一个生成式视觉推理基准
基准
视频生成
Xinxin Liu, Zhaopan Xu, Kai Wang, et al.
一种风格胜过一行代码:通过离散风格空间实现代码到风格图像的生成
文生图
扩散模型
Huijie Liu, Shuhao Cui, Haoxiang Cao, et al.
AraLingBench:用于评估大型语言模型阿拉伯语语言能力的人工标注基准
基准
LLM
Mohammad Zbib, Hasan Abed Al Kader Hammoud, Sina Mukalled, et al.
Think-at-Hard:通过选择性潜在迭代提升推理型语言模型
LLM
推理
Tianyu Fu, Yichen You, Zekai Chen, et al.
HumanSense:从多模态感知到通过推理实现共情的上下文感知响应的MLLMs
LLM
多模态
Zheng Qin, Ruobing Zheng, Yabing Wang, et al.
1
13
14
15
16
17
18
19
49
HiPO:面向LLMs动态推理的混合策略优化
推理
强化学习
Ken Deng, Zizheng Zhan, Wen Xiang, et al.
SERES:基于语义感知的稀疏视角神经重建
3D 生成
计算机视觉
Bo Xu, Yuhu Guo, Yuchao Wang, et al.
SDAR:一种用于可扩展序列生成的协同扩散-自回归范式
扩散模型
模型训练
Shuang Cheng, Yihan Bian, Dawei Liu, et al.
MultiPL-MoE:通过混合专家模型扩展大型语言模型的多编程语言能力
LLM
代码生成
Qing Wang, Xue Han, Jiahui Wang, et al.
CapRL:通过强化学习激发密集图像描述能力
图像描述
视觉问答
Long Xing, Xiaoyi Dong, Yuhang Zang, et al.
通过离散扩散发散指令实现超快速语言生成
扩散模型
文本生成
Haoyang Zheng, Xinyang Liu, Cindy Xiangrui Kong, et al.
DisCO:通过判别约束优化强化大型推理模型
强化学习
推理
Gang Li, Ming Lin, Tomer Galanti, et al.
QSVD:面向低精度视觉-语言模型中统一查询-键-值权重压缩的高效低秩近似
Transformer
视觉问答
Yutong Wang, Haiyu Wang, Sai Qian Zhang
嵌套学习:深度学习架构的幻觉
深度学习
自然语言处理
Ali Behrouz, Meisam Razaviyayn, Peiling Zhong, et al.
SAM 3D:将图像中的任意内容3D化
3D 生成
3D 模型
SAM 3D Team, Xingyu Chen, Fu-Jen Chu, et al.
视频即答案:基于联合GRPO的下一视频事件预测与生成
视频生成
文生视频
Junhao Cheng, Liang Hou, Xin Tao, et al.
首帧是视频内容定制的首选之地
视频生成
图生视频
Jingxi Chen, Zongxia Li, Zhichao Liu, et al.
基于多模态基础模型的时空智能扩展
多模态
多模态表征
Zhongang Cai, Ruisi Wang, Chenyang Gu, et al.
Step-Audio-R1 技术报告
推理
多模态
Fei Tian, Xiangyu Tony Zhang, Yuxin Zhang, et al.
V-ReasonBench:面向视频生成模型的统一推理基准测试套件
基准
视觉问答
Yang Luo, Xuanlei Zhao, Baijiong Lin, et al.
Olmo 3
LLM
代码生成
Allyson Ettinger, Amanda Bertsch, Bailey Kuehl, et al.
GPT-5的早期科学加速实验
AI for Science
推理
Sébastien Bubeck, Christian Coester, Ronen Eldan, et al.
成为优秀的AI研究Agent需要什么?——探究创意多样性的作用
Agent
基准
Alexis Audran-Reiss, Jordi Armengol Estapé, Karen Hambardzumyan, et al.
指令引导的胸部X光图像病灶分割方法及其自动构建的大规模数据集
语义分割
多模态
Geon Choi, Hangyul Yoon, Hyunju Shin, et al.
VisPlay:从图像中自演化视觉-语言模型
强化学习
多模态
Yicheng He, Chengsong Huang, Zongxia Li, et al.
通过视频进行推理:首个基于迷宫求解任务对视频模型推理能力的评估
多模态表征
推理
Cheng Yang, Haiyuan Wan, Yiran Peng, et al.
VIDEOP2R:从感知到推理的视频理解
视频理解
多模态表征
Yifan Jiang, Yueying Wang, Rui Zhao, et al.
Kandinsky 5.0:面向图像与视频生成的基础模型家族
文生图
图生视频
Vladimir Arkhipkin, Vladimir Korviakov, Nikolai Gerasimenko, et al.
JAM-2:具有高成功率的类药物抗体的全计算设计
AI for Science
深度学习
Nabla Bio
PathMind:一种基于大型语言模型的知识图谱推理的检索-优先级排序-推理框架
检索增强生成
LLM
Yu Liu, Xixun Lin, Yanmin Shang, et al.
审稿人:超越文本反思,迈向长视频理解中的多模态内省推理
视频理解
推理
Jiaze Li, Hao Yin, Wenhui Tan, et al.
MVI-Bench:面向低视觉语言模型中误导性视觉输入鲁棒性评估的综合性基准
视觉问答
多模态
Huiyi Chen, Jiawei Peng, Dehai Min, et al.
世界模拟器能进行推理吗?Gen-ViRe:一个生成式视觉推理基准
基准
视频生成
Xinxin Liu, Zhaopan Xu, Kai Wang, et al.
一种风格胜过一行代码:通过离散风格空间实现代码到风格图像的生成
文生图
扩散模型
Huijie Liu, Shuhao Cui, Haoxiang Cao, et al.
AraLingBench:用于评估大型语言模型阿拉伯语语言能力的人工标注基准
基准
LLM
Mohammad Zbib, Hasan Abed Al Kader Hammoud, Sina Mukalled, et al.
Think-at-Hard:通过选择性潜在迭代提升推理型语言模型
LLM
推理
Tianyu Fu, Yichen You, Zekai Chen, et al.
HumanSense:从多模态感知到通过推理实现共情的上下文感知响应的MLLMs
LLM
多模态
Zheng Qin, Ruobing Zheng, Yabing Wang, et al.
1
13
14
15
16
17
18
19
49