HyperAI
HyperAI
主区域
首页
GPU
控制台
文档
价格
Pulse
报道
资源
论文
教程
数据集
百科
基准测试
SOTA
大语言模型(LLM)
GPU 排行榜
社区
活动
开源
实用工具
搜索
关于
服务条款
隐私政策
中文
HyperAI
HyperAI
Toggle Sidebar
⌘
K
Command Palette
Search for a command to run...
登录
HyperAI
论文
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势
HyperAI
HyperAI
主区域
首页
GPU
控制台
文档
价格
Pulse
报道
资源
论文
教程
数据集
百科
基准测试
SOTA
大语言模型(LLM)
GPU 排行榜
社区
活动
开源
实用工具
搜索
关于
服务条款
隐私政策
中文
HyperAI
HyperAI
Toggle Sidebar
⌘
K
Command Palette
Search for a command to run...
登录
HyperAI
论文
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势
视频-LMM后训练:基于大型多模态模型的视频推理深度探究
监督式微调
LLM
Yunlong Tang, Jing Bi, Pinxin Liu, et al.
Paper2Video:从科学论文自动生成视频
文生视频
统一多模态
Zeyu Zhu, Kevin Qinghong Lin, Mike Zheng Shou
微缩扩展FP4量化中的承诺与性能之间的差距
LLM
Transformer
Vage Egiazarian, Roberto L. Castro, Denis Kuznedelev, et al.
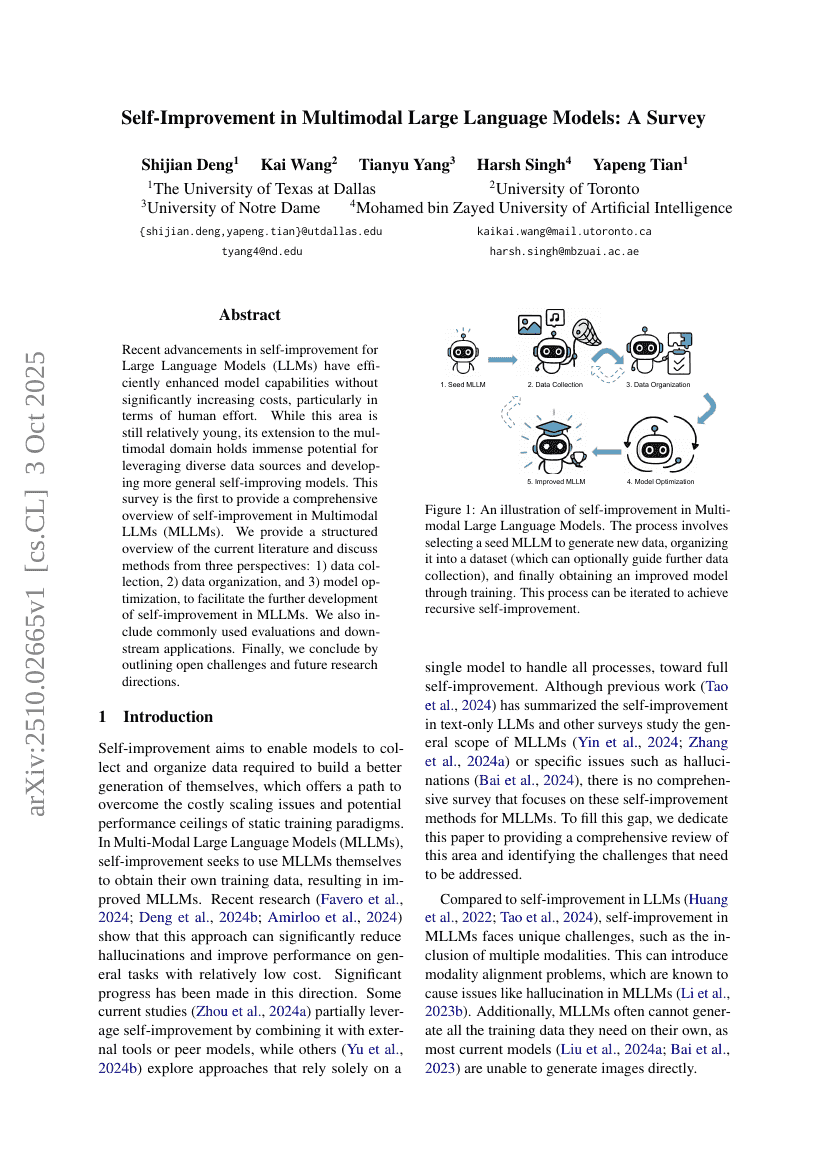
多模态大语言模型中的自提升:一项综述
多模态
LLM
Shijian Deng, Kai Wang, Tianyu Yang, et al.
通过测试时分布级组合改进基于扩散或基于流的机器人策略
扩散模型
机器人技术
Jiahang Cao, Yize Huang, Hanzhong Guo, et al.
大型推理模型从有缺陷的思维中学习到更好的对齐
LLM
偏好
ShengYun Peng, Eric Smith, Ivan Evtimov, et al.
通过渐进一致性蒸馏实现高效的多模态大型语言模型
多模态
Transformer
Zichen Wen, Shaobo Wang, Yufa Zhou, et al.
Apriel-1.5-15b-Thinker
多模态
视觉问答
Shruthan Radhakrishna, Aman Tiwari, Aanjaneya Shukla, et al.
StockBench:LLM Agent 能否在现实市场中盈利地交易股票?
基准
LLM
Yanxu Chen, Zijun Yao, Yantao Liu, et al.
交互式训练:反馈驱动的神经网络优化
模型训练
人机交互
Wentao Zhang, Yang Young Lu, Yuntian Deng
StealthAttack:通过密度引导的幻觉实现鲁棒的3D Gaussian Splatting投毒
3D 生成
机器视觉 3D
Bo-Hsu Ke, You-Zhe Xie, Yu-Lun Liu, et al.
ExGRPO:从经验中学习推理
强化学习
LLM
Runzhe Zhan, Yafu Li, Zhi Wang, et al.
Self-Forcing++:迈向分钟级高质量视频生成
扩散模型
视频生成
Justin Cui, Jie Wu, Ming Li, et al.
LongCodeZip:为Code LLM压缩长上下文
代码生成
LLM
Yuling Shi, Yichun Qian, Hongyu Zhang, et al.
PIPer:通过在线强化学习实现设备端环境配置
强化学习
监督式微调
Alexander Kovrigin, Aleksandra Eliseeva, Konstantin Grotov, et al.
多领域测试时扩展的奖励模型再思考
LLM
监督式微调
Dong Bok Lee, Seanie Lee, Sangwoo Park, et al.
背包强化学习:通过优化预算分配解锁LLM的探索能力
强化学习
LLM
Ziniu Li, Congliang Chen, Tianyun Yang, et al.
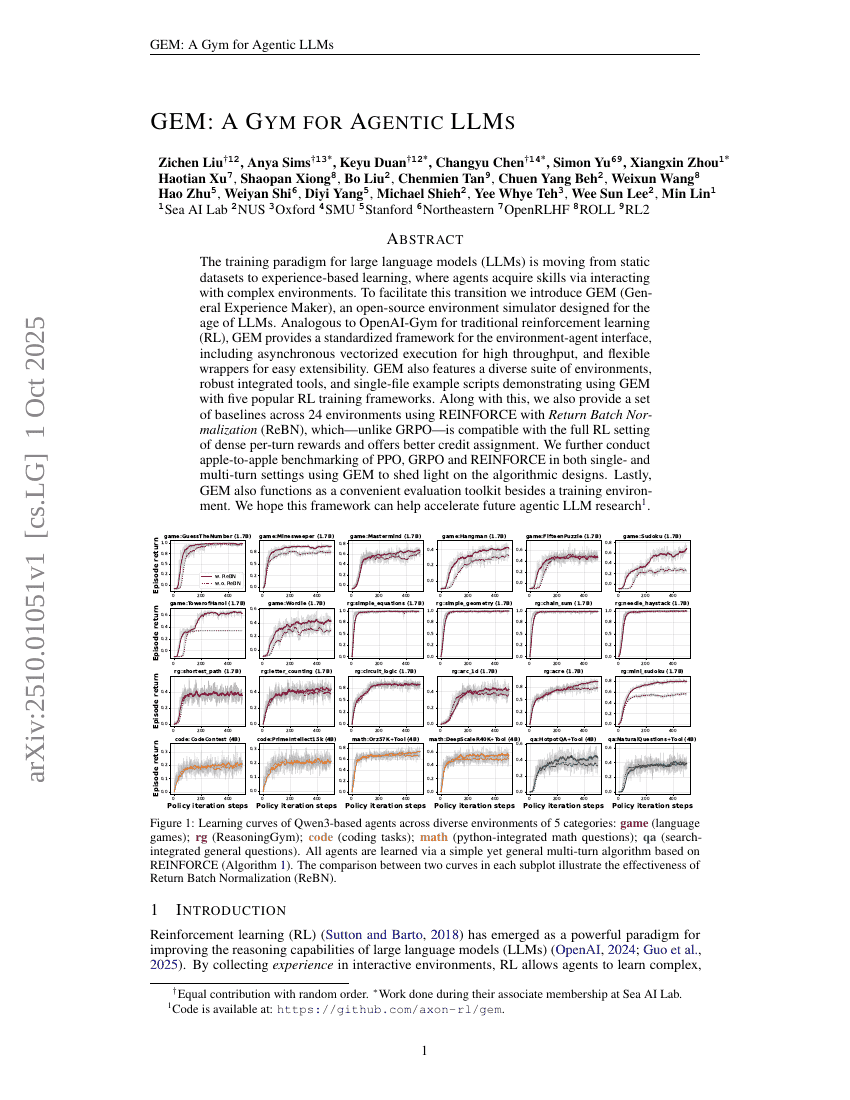
GEM:面向智能体LLM的健身房
LLM
强化学习
Zichen Liu, Anya Sims, Keyu Duan, et al.
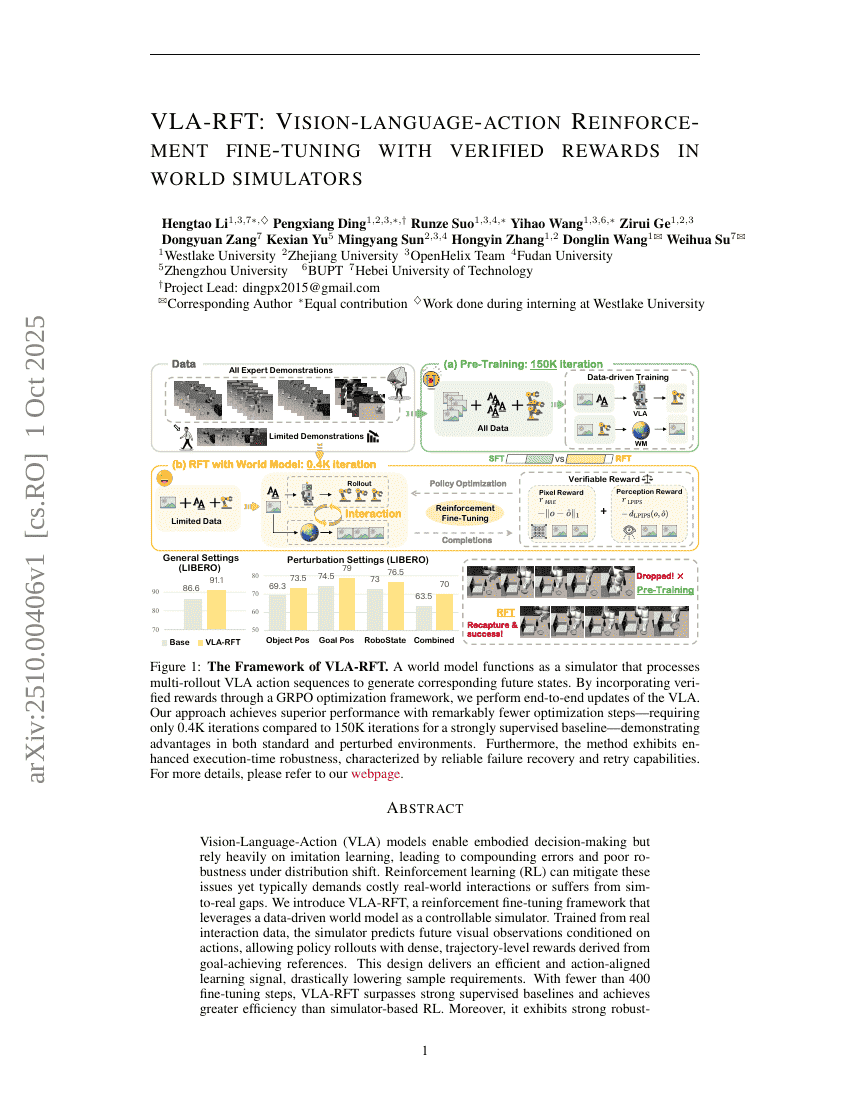
VLA-RFT:基于世界模拟器中验证奖励的视觉-语言-动作强化微调
强化学习
具身智能
Hengtao Li, Pengxiang Ding, Runze Suo, et al.
DeepSearch:通过蒙特卡洛树搜索克服强化学习中可验证奖励的瓶颈
强化学习
推理
Fang Wu, Weihao Xuan, Heli Qi, et al.
OceanGym:水下具身Agent的基准环境
具身智能
多模态
Yida Xue, Mingjun Mao, Xiangyuan Ru, et al.
TruthRL:通过强化学习激励LLM说真话
强化学习
监督式微调
Zhepei Wei, Xiao Yang, Kai Sun, et al.
赢得剪枝赌局:一种面向高效监督微调的联合样本与token剪枝统一方法
监督式微调
LLM
Shaobo Wang, Jiaming Wang, Jiajun Zhang, et al.
龙之幼崽:Transformer与大脑模型之间的缺失环节
Transformer
自然语言处理
Adrian Kosowski, Przemysław Uznański, Jan Chorowski, et al.
Vision-Zero:通过策略性游戏化自对弈实现可扩展的VLM自我提升
视觉问答
多模态
Qinsi Wang, Bo Liu, Tianyi Zhou, et al.
MCPMark:用于压力测试现实且全面的MCP使用的基准
基准
Agent
Zijian Wu, Xiangyan Liu, Xinyuan Zhang, et al.
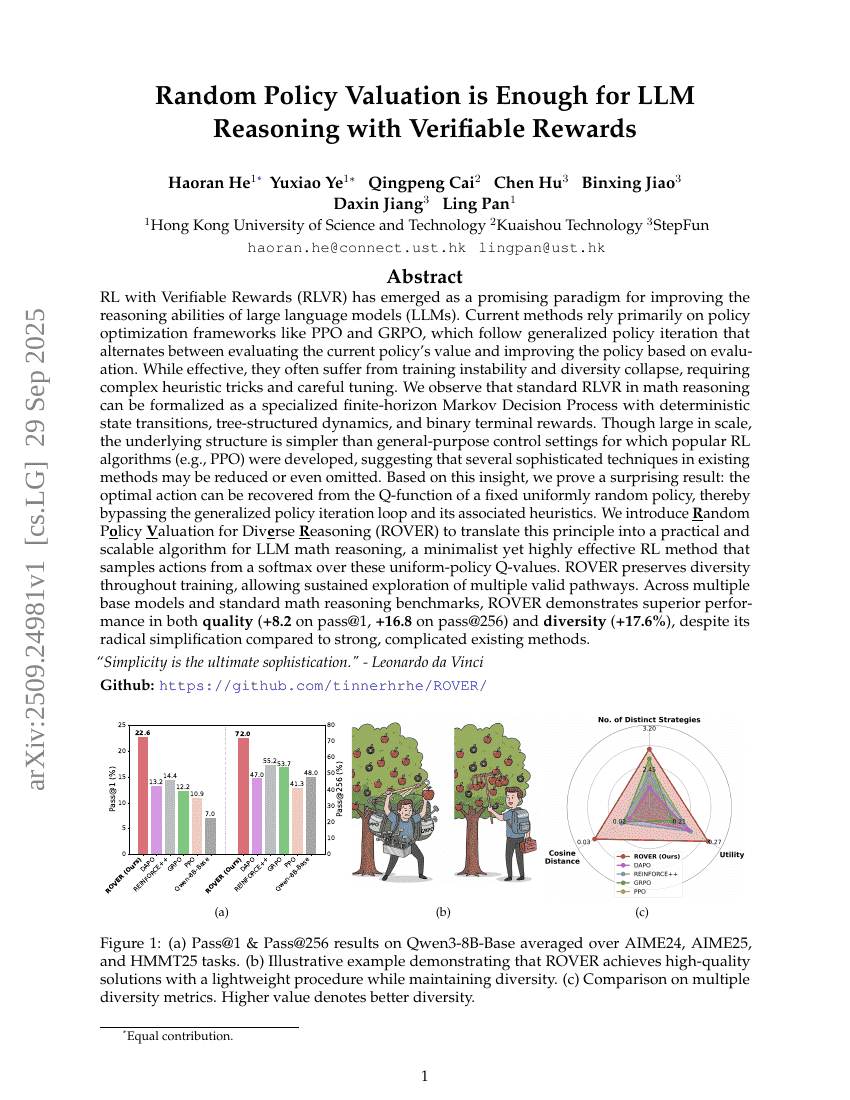
可验证奖励下的LLM推理仅需随机策略评估
强化学习
推理
Haoran He, Yuxiao Ye, Qingpeng Cai, et al.
使用ToolUniverse实现AI科学家的民主化
Agent
推理
Shanghua Gao, Richard Zhu, Pengwei Sui, et al.
推理何时才重要?一项关于推理对模型性能贡献的受控研究
推理
监督式微调
Nicolas Boizard, Hippolyte Gisserot-Boukhlef, Kevin El-Haddad, et al.
多人博弈纳什偏好优化
偏好
强化学习
Fang Wu, Xu Huang, Weihao Xuan, et al.
StableToken:一种抗噪声的语义语音Tokenize,用于增强语音LLM的鲁棒性
音频和语音处理
Transformer
Yuhan Song, Linhao Zhang, Chuhan Wu, et al.
SLA:通过可微调稀疏线性注意力实现扩散Transformer中的稀疏性突破
扩散模型
Transformer
Jintao Zhang, Haoxu Wang, Kai Jiang, et al.
1
23
24
25
26
27
28
29
49
视频-LMM后训练:基于大型多模态模型的视频推理深度探究
监督式微调
LLM
Yunlong Tang, Jing Bi, Pinxin Liu, et al.
Paper2Video:从科学论文自动生成视频
文生视频
统一多模态
Zeyu Zhu, Kevin Qinghong Lin, Mike Zheng Shou
微缩扩展FP4量化中的承诺与性能之间的差距
LLM
Transformer
Vage Egiazarian, Roberto L. Castro, Denis Kuznedelev, et al.
多模态大语言模型中的自提升:一项综述
多模态
LLM
Shijian Deng, Kai Wang, Tianyu Yang, et al.
通过测试时分布级组合改进基于扩散或基于流的机器人策略
扩散模型
机器人技术
Jiahang Cao, Yize Huang, Hanzhong Guo, et al.
大型推理模型从有缺陷的思维中学习到更好的对齐
LLM
偏好
ShengYun Peng, Eric Smith, Ivan Evtimov, et al.
通过渐进一致性蒸馏实现高效的多模态大型语言模型
多模态
Transformer
Zichen Wen, Shaobo Wang, Yufa Zhou, et al.
Apriel-1.5-15b-Thinker
多模态
视觉问答
Shruthan Radhakrishna, Aman Tiwari, Aanjaneya Shukla, et al.
StockBench:LLM Agent 能否在现实市场中盈利地交易股票?
基准
LLM
Yanxu Chen, Zijun Yao, Yantao Liu, et al.
交互式训练:反馈驱动的神经网络优化
模型训练
人机交互
Wentao Zhang, Yang Young Lu, Yuntian Deng
StealthAttack:通过密度引导的幻觉实现鲁棒的3D Gaussian Splatting投毒
3D 生成
机器视觉 3D
Bo-Hsu Ke, You-Zhe Xie, Yu-Lun Liu, et al.
ExGRPO:从经验中学习推理
强化学习
LLM
Runzhe Zhan, Yafu Li, Zhi Wang, et al.
Self-Forcing++:迈向分钟级高质量视频生成
扩散模型
视频生成
Justin Cui, Jie Wu, Ming Li, et al.
LongCodeZip:为Code LLM压缩长上下文
代码生成
LLM
Yuling Shi, Yichun Qian, Hongyu Zhang, et al.
PIPer:通过在线强化学习实现设备端环境配置
强化学习
监督式微调
Alexander Kovrigin, Aleksandra Eliseeva, Konstantin Grotov, et al.
多领域测试时扩展的奖励模型再思考
LLM
监督式微调
Dong Bok Lee, Seanie Lee, Sangwoo Park, et al.
背包强化学习:通过优化预算分配解锁LLM的探索能力
强化学习
LLM
Ziniu Li, Congliang Chen, Tianyun Yang, et al.
GEM:面向智能体LLM的健身房
LLM
强化学习
Zichen Liu, Anya Sims, Keyu Duan, et al.
VLA-RFT:基于世界模拟器中验证奖励的视觉-语言-动作强化微调
强化学习
具身智能
Hengtao Li, Pengxiang Ding, Runze Suo, et al.
DeepSearch:通过蒙特卡洛树搜索克服强化学习中可验证奖励的瓶颈
强化学习
推理
Fang Wu, Weihao Xuan, Heli Qi, et al.
OceanGym:水下具身Agent的基准环境
具身智能
多模态
Yida Xue, Mingjun Mao, Xiangyuan Ru, et al.
TruthRL:通过强化学习激励LLM说真话
强化学习
监督式微调
Zhepei Wei, Xiao Yang, Kai Sun, et al.
赢得剪枝赌局:一种面向高效监督微调的联合样本与token剪枝统一方法
监督式微调
LLM
Shaobo Wang, Jiaming Wang, Jiajun Zhang, et al.
龙之幼崽:Transformer与大脑模型之间的缺失环节
Transformer
自然语言处理
Adrian Kosowski, Przemysław Uznański, Jan Chorowski, et al.
Vision-Zero:通过策略性游戏化自对弈实现可扩展的VLM自我提升
视觉问答
多模态
Qinsi Wang, Bo Liu, Tianyi Zhou, et al.
MCPMark:用于压力测试现实且全面的MCP使用的基准
基准
Agent
Zijian Wu, Xiangyan Liu, Xinyuan Zhang, et al.
可验证奖励下的LLM推理仅需随机策略评估
强化学习
推理
Haoran He, Yuxiao Ye, Qingpeng Cai, et al.
使用ToolUniverse实现AI科学家的民主化
Agent
推理
Shanghua Gao, Richard Zhu, Pengwei Sui, et al.
推理何时才重要?一项关于推理对模型性能贡献的受控研究
推理
监督式微调
Nicolas Boizard, Hippolyte Gisserot-Boukhlef, Kevin El-Haddad, et al.
多人博弈纳什偏好优化
偏好
强化学习
Fang Wu, Xu Huang, Weihao Xuan, et al.
StableToken:一种抗噪声的语义语音Tokenize,用于增强语音LLM的鲁棒性
音频和语音处理
Transformer
Yuhan Song, Linhao Zhang, Chuhan Wu, et al.
SLA:通过可微调稀疏线性注意力实现扩散Transformer中的稀疏性突破
扩散模型
Transformer
Jintao Zhang, Haoxu Wang, Kai Jiang, et al.
1
23
24
25
26
27
28
29
49