Command Palette
Search for a command to run...
AlphaEdit: Null-Space Constrained Knowledge Editing for Language Models
AlphaEdit: Null-Space Constrained Knowledge Editing for Language Models
Junfeng Fang Houcheng Jiang Kun Wang Yunshan Ma Shi Jie Xiang Wang Xiangnan He Tat-seng Chua
Abstract
Large language models (LLMs) often exhibit hallucinations due to incorrect or outdated knowledge. Hence, model editing methods have emerged to enable targeted knowledge updates. To achieve this, a prevailing paradigm is the locating-then-editing approach, which first locates influential parameters and then edits them by introducing a perturbation. While effective, current studies have demonstrated that this perturbation inevitably disrupt the originally preserved knowledge within LLMs, especially in sequential editing scenarios. To address this, we introduce AlphaEdit, a novel solution that projects perturbation onto the null space of the preserved knowledge before applying it to the parameters. We theoretically prove that this projection ensures the output of post-edited LLMs remains unchanged when queried about the preserved knowledge, thereby mitigating the issue of disruption. Extensive experiments on various LLMs, including LLaMA3, GPT2-XL, and GPT-J, show that AlphaEdit boosts the performance of most locating-then-editing methods by an average of 36.7% with a single line of additional code for projection solely. Our code is available at: this https URL.
One-sentence Summary
Researchers from USTC and NUS propose AlphaEdit, a null-space projection technique that preserves existing knowledge during LLM editing by isolating perturbations, boosting performance by 36.7% across models like LLaMA3 and GPT-J with minimal code overhead.
Key Contributions
- AlphaEdit addresses the problem of knowledge disruption in LLM editing by projecting parameter perturbations onto the null space of preserved knowledge, ensuring outputs remain unchanged for unchanged queries, thus preventing model forgetting during sequential edits.
- The method introduces a theoretically grounded constraint that removes the need to balance update and preservation errors, enabling focused optimization on new knowledge while maintaining hidden representation stability across LLM layers.
- Evaluated on LLaMA3, GPT2-XL, and GPT-J, AlphaEdit improves most locate-then-edit methods by 36.7% on average with just one line of code, demonstrating plug-and-play compatibility and significant performance gains without architectural changes.
Introduction
The authors leverage a null-space projection technique to address a key flaw in existing model editing methods for large language models: the tendency to disrupt preserved knowledge when updating targeted facts. Current locate-then-edit approaches often overfit to new knowledge during sequential edits, causing hidden representation shifts and eventual model collapse. AlphaEdit circumvents this by removing preservation constraints from the optimization objective and instead projecting parameter updates onto the null space of preserved knowledge—guaranteeing unchanged outputs for unedited queries. This single-line code enhancement boosts performance across multiple LLMs by an average of 36.7%, making it a plug-and-play upgrade for existing editing frameworks.
Dataset
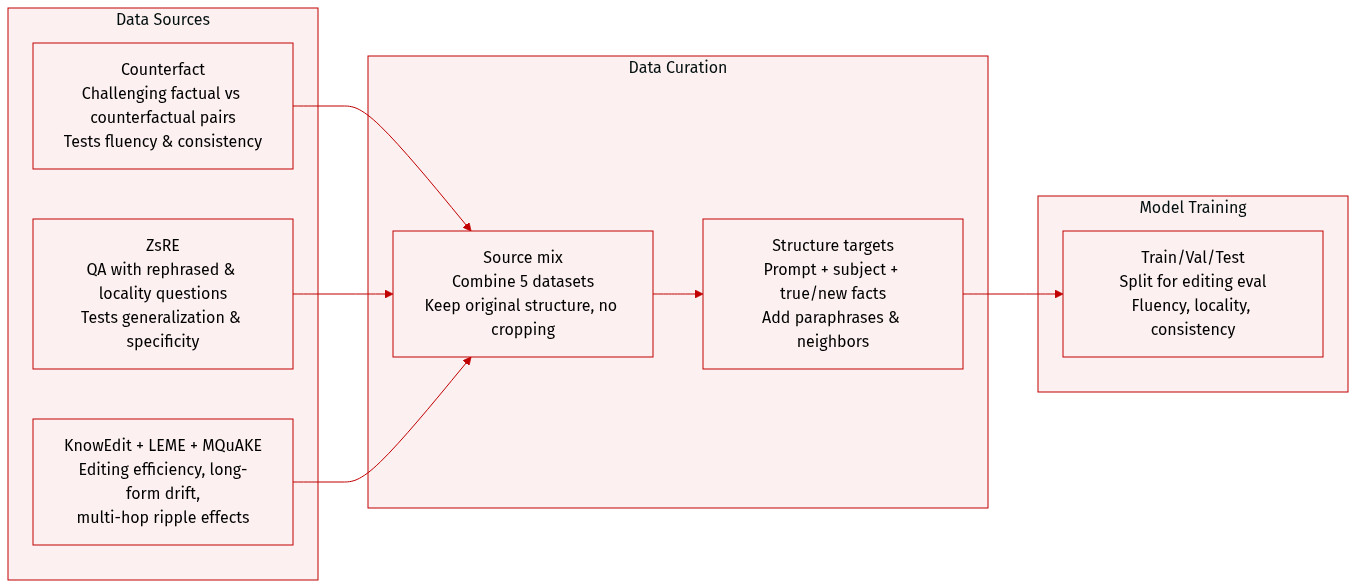
The authors use a curated mix of five key datasets to evaluate knowledge editing performance across diverse dimensions:
-
Counterfact (Meng et al., 2022): A challenging dataset that contrasts factual and counterfactual statements. It generates out-of-scope examples by replacing subject entities while preserving predicates. Includes multiple paraphrased generation prompts to test fluency and consistency. Used to evaluate generalization and specificity.
-
ZsRE (Levy et al., 2017): A QA dataset using back-translated questions as equivalent neighbors. Each sample includes a subject, target answer, rephrased question (for generalization), and locality question (for specificity). Natural questions serve as out-of-scope data to test locality.
-
KnowEdit (Zhang et al., 2024d): A comprehensive benchmark evaluating editing methods across external, intrinsic, and merged knowledge updates. The authors specifically use its wiki_recent and wikibio subsets to test editing efficiency and preservation of overall model performance.
-
LEME (Rosati et al., 2024): Focuses on long-form generation to expose issues like factual drift and lexical cohesion. Highlights that short-form metrics do not reflect long-form editing success, adding a critical dimension to evaluation.
-
MQuAKE (Zhong et al., 2023): Tests multi-hop reasoning to evaluate ripple effects after factual edits. Measures consistency of entailed beliefs, exposing limitations in handling complex relational dependencies.
The datasets are processed to include structured editing targets: each sample contains a prompt, subject, true and new target facts, and multiple prompt variants (paraphrases, neighbors, attributes, and generation prompts). These variants support evaluation of fluency, generalization, locality, and consistency. The authors do not apply cropping or metadata construction beyond the original dataset structures. Training splits and mixture ratios are not specified in the provided text, but the datasets are used collectively to benchmark editing methods across multiple axes of performance.
Method
The authors leverage a null space projection mechanism to constrain model edits in large language models, ensuring that updates to factual knowledge do not interfere with either preserved or previously edited knowledge. The core insight is that perturbations applied to the model’s feed-forward network weights W can be projected into the null space of K0 — the matrix encoding preserved knowledge — so that (W+ΔP)K0=WK0=V0, thereby leaving existing associations intact.
The method begins by recognizing that standard model editing objectives, such as those used in MEMIT, require balancing the fidelity of updated knowledge (K1,V1) against the preservation of existing knowledge (K0,V0). This dual objective often leads to suboptimal convergence or unintended side effects, as illustrated in the figure comparing current methods with AlphaEdit. In current approaches, the perturbation Δ is computed to minimize both the error on updated knowledge and the error on preserved knowledge, which can cause representation drift and output collapse — as shown in the “Output of the Post-edited LLM” panel, where the model generates incoherent text after editing.
As shown in the figure below, AlphaEdit circumvents this by first computing the standard perturbation Δ~, then projecting it into the null space of K0 via a projection matrix P, yielding ΔP. This projection ensures that the perturbation has no effect on K0, allowing the optimization objective to focus solely on the updated knowledge K1 and previously edited knowledge Kp, without needing an explicit preservation term. The resulting objective becomes:
Δ=Δ~argmin(∣∣(W+Δ~P)K1−V1∣∣2+∣∣Δ~P∣∣2+∣∣Δ~PKp∣∣2).This reformulation eliminates the need to compute or store K0 during optimization, reducing computational overhead while improving edit fidelity.
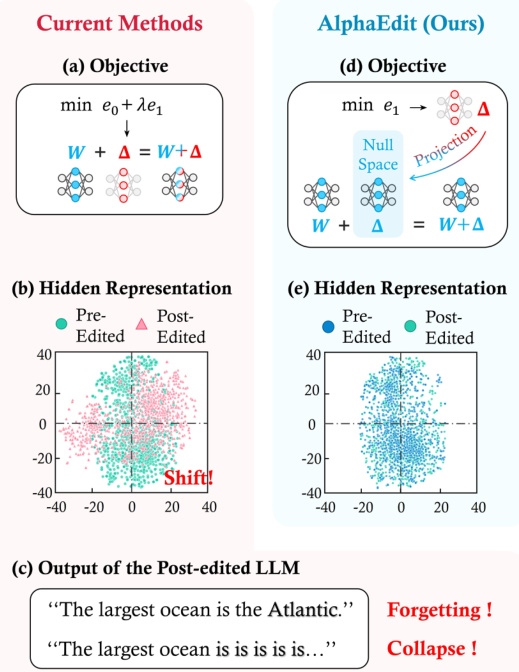
The projection matrix P is derived from the singular value decomposition of the non-central covariance matrix K0K0T, which shares the same null space as K0 but is computationally tractable due to its smaller dimensionality. Specifically, after computing U and Λ via SVD, the authors retain only the eigenvectors corresponding to zero eigenvalues to construct U^, and define P=U^U^T. This matrix is computed once per model and reused across all editing tasks, making AlphaEdit highly efficient.
The final perturbation ΔAlphaEdit is obtained in closed form:
ΔAlphaEdit=RK1TP(KpKpTP+K1K1TP+I)−1,where R=V1−WK1 is the residual error. This solution is structurally similar to the MEMIT update, differing only by the inclusion of P, which enables seamless integration into existing editing pipelines. As emphasized in the accompanying diagram, this modification requires only a single line of code — a projection step — to transform any standard editing method into its null-space constrained variant.

Experiment
- AlphaEdit outperforms baseline methods in sequential editing tasks, significantly improving efficacy and generalization while mitigating model forgetting and collapse.
- Post-edited models retain strong general capabilities across diverse NLP tasks, even after extensive edits, unlike baselines that degrade rapidly.
- AlphaEdit prevents overfitting to updated knowledge by preserving the distribution of hidden representations, maintaining model stability and coherence.
- Integrating AlphaEdit’s projection strategy into baseline methods yields substantial performance gains, boosting both editing accuracy and general capability.
- The method demonstrates robustness across multiple LLMs and datasets, including challenging benchmarks involving multi-hop reasoning and long-form generation.
- Performance remains stable under reduced dataset sizes for key metrics, though specificity declines when data is severely limited.
- AlphaEdit scales efficiently with model size without adding runtime overhead, making it practical for large-scale editing applications.
The authors use AlphaEdit to perform sequential model editing and compare its runtime efficiency against MEMIT across multiple LLMs and datasets. Results show that AlphaEdit introduces no measurable runtime overhead, maintaining nearly identical per-batch editing times as MEMIT while delivering superior performance in knowledge update and preservation. This confirms AlphaEdit’s scalability and practicality for large-scale editing tasks without compromising speed.

AlphaEdit consistently outperforms baseline methods on both multi-hop reasoning and long-form generation tasks, demonstrating stronger factual consistency and internal coherence across GPT-J and GPT2-XL models. The method maintains high performance in complex reasoning scenarios while preserving the structural integrity of generated text, indicating robust generalization beyond simple fact updates.
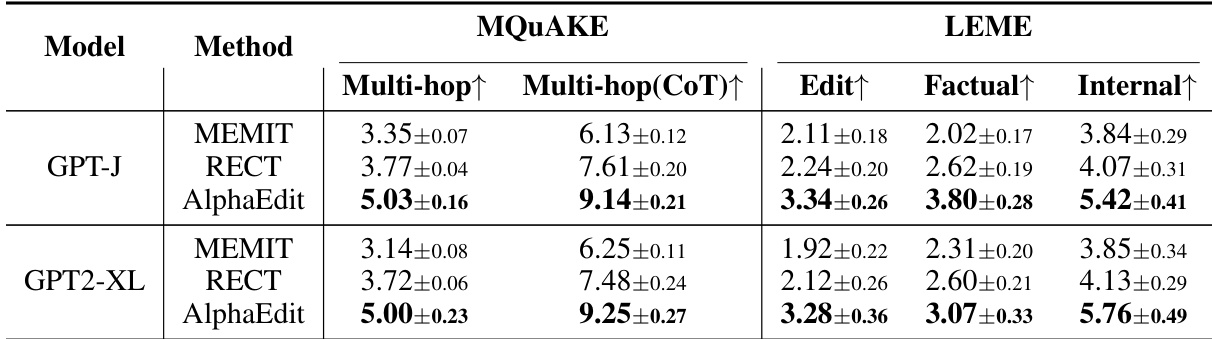
AlphaEdit significantly outperforms baseline methods like MEMIT and RECT on both wiki_recent and wikibio datasets, achieving the highest edit success rates while maintaining strong fluency and locality. The results confirm that AlphaEdit effectively preserves model behavior around edited facts without degrading output quality, even on challenging knowledge update tasks.

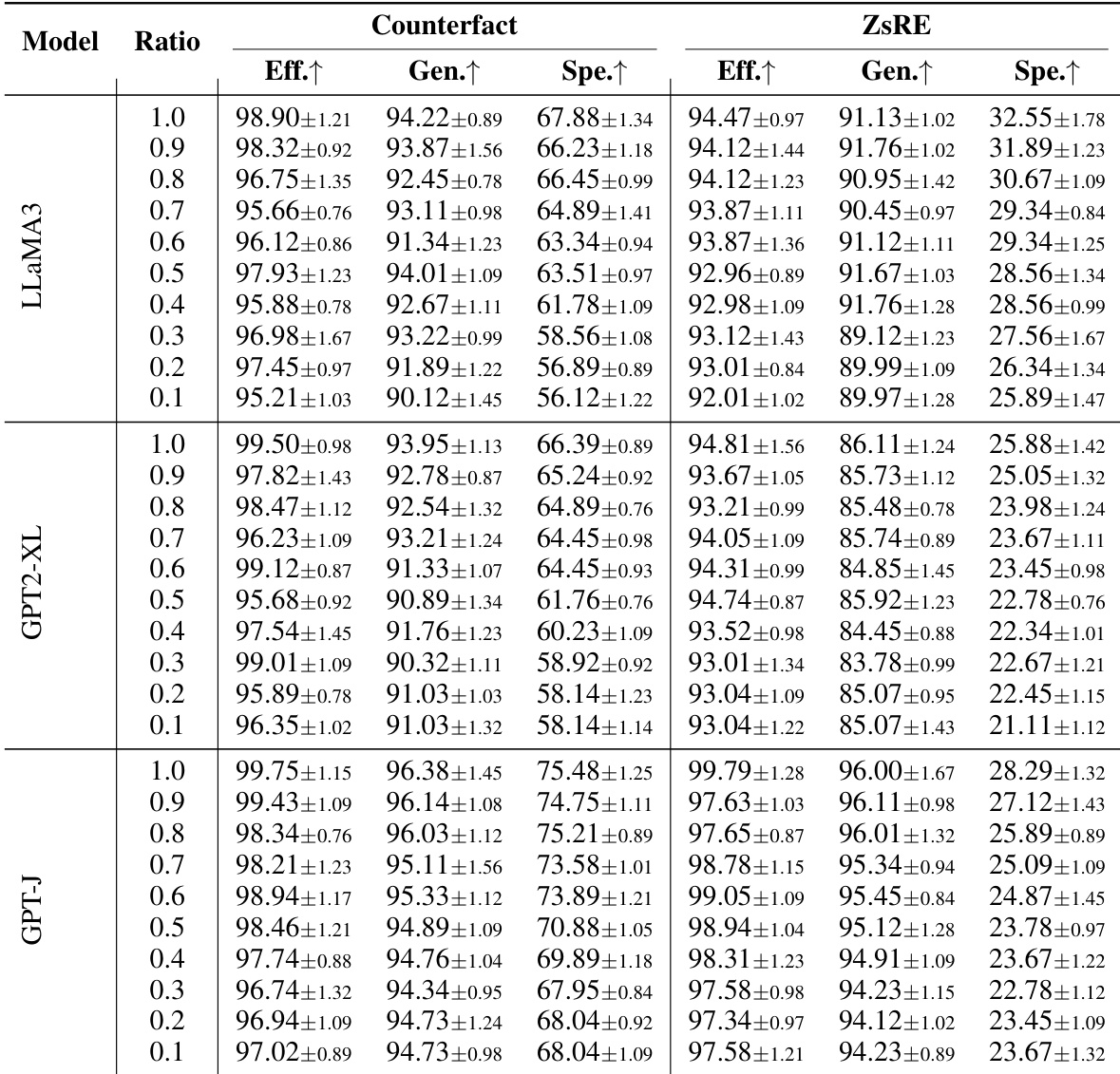
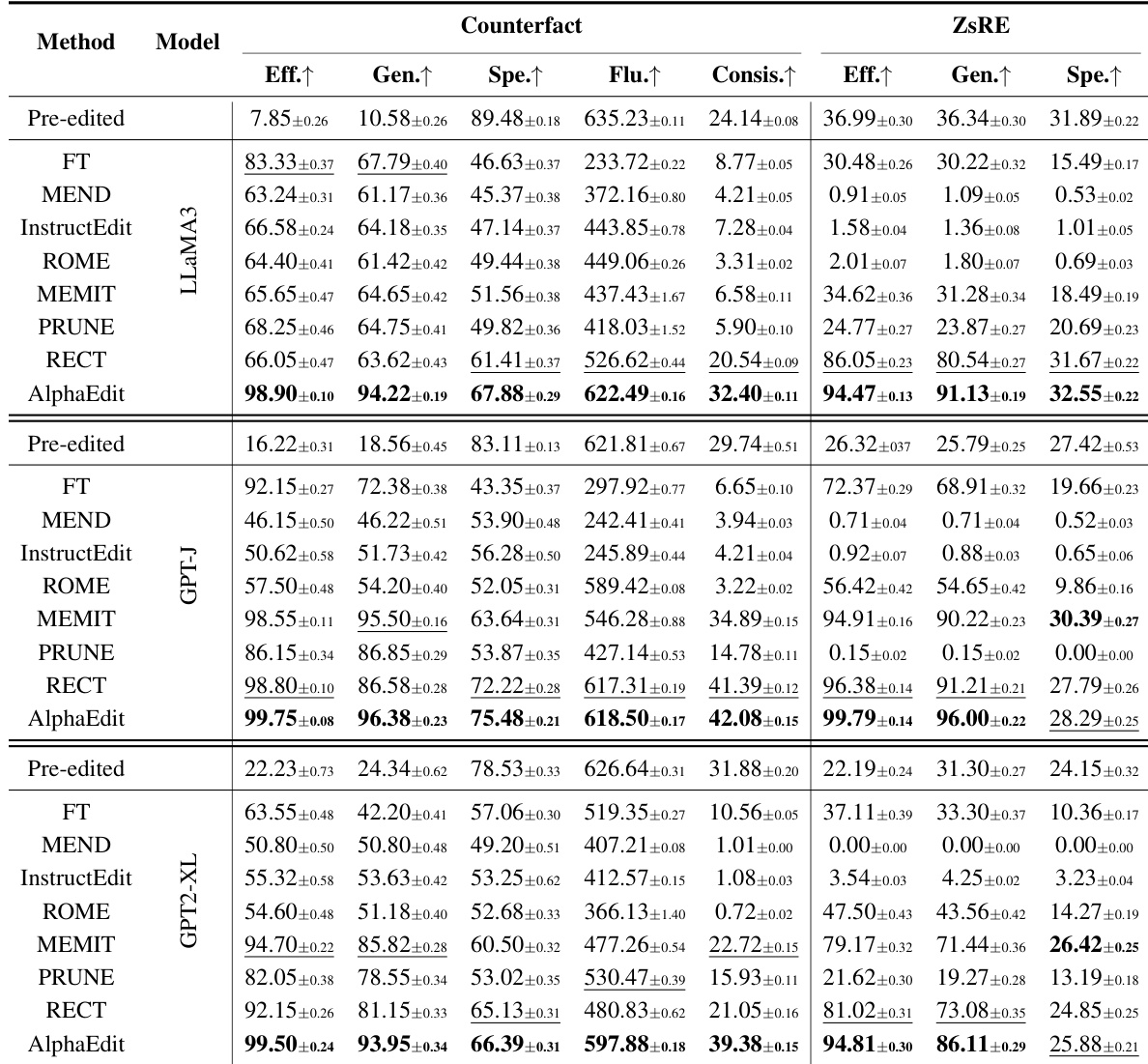
AlphaEdit consistently outperforms baseline methods across multiple large language models and datasets, achieving the highest scores in efficacy and generalization while maintaining strong fluency and specificity. The method effectively preserves the model’s original capabilities during sequential editing, avoiding the degradation typically seen in other approaches. Its null-space projection technique also enhances baseline methods when integrated, demonstrating broad applicability and robustness across model architectures.
The authors use AlphaEdit to perform sequential knowledge editing across multiple LLMs and evaluate its impact on efficacy, generalization, and specificity under varying data ratios. Results show that AlphaEdit maintains high editing performance even with reduced training data, particularly preserving efficacy and generalization, while specificity declines more noticeably at lower data ratios. This indicates AlphaEdit’s robustness in knowledge update tasks and its ability to generalize effectively with limited data.