Command Palette
Search for a command to run...
Can Language Models Discover Scaling Laws?
Can Language Models Discover Scaling Laws?
Abstract
Discovering scaling laws for predicting model performance at scale is a fundamental and open-ended challenge, mostly reliant on slow, case specific human experimentation. To investigate the potential for LLMs to automate this process, we collect over 5,000 experiments from existing literature and curate eight diverse scaling law discovery tasks. While existing agents struggle to produce accurate law formulas, this paper introduces SLDAgent, an evolution-based agent that co-optimize the scaling law model and the parameters, enabling it to autonomously explore complex relationships between variables. For the first time, we demonstrates that SLDAgent can automatically discover laws that exhibit consistently more accurate extrapolation than their established, human-derived counterparts across all tasks. Through comprehensive analysis, we elucidate why these discovered laws are superior and verify their practical utility in both pretraining and finetuning applications. This work establishes a new paradigm for agentic scientific discovery, showing that AI systems can understand their own scaling behavior, and can contribute novel and practical knowledge back to the research community.
One-sentence Summary
Researchers from Peking University, Stanford, Wizard Quant, and Tsinghua introduce SLDAgent, an evolution-based agent that autonomously discovers more accurate scaling laws than human-derived ones, enabling better extrapolation for LLM pretraining and fine-tuning, thus pioneering AI-driven scientific discovery.
Key Contributions
- SLDAgent, an evolution-based LLM agent, autonomously discovers scaling laws by co-optimizing symbolic formulations and their parameters, overcoming the limitations of prior agents that fail to match human-derived accuracy in extrapolation.
- Evaluated on SLDBench—a curated testbed of 5,000+ experiments across eight diverse tasks—SLDAgent consistently outperforms human experts and baseline agents, achieving higher R² scores on unseen test sets without relying on learned reward models.
- The discovered laws demonstrate practical utility in pretraining and fine-tuning, enabling near-optimal hyperparameter selection and checkpoint identification, while introducing more principled mathematical structures such as unified scaling exponents and asymptotically sound behavior.
Introduction
The authors leverage large language models to automate the discovery of scaling laws—mathematical relationships that predict how model performance evolves with scale—which are critical for efficient model design, hyperparameter tuning, and resource allocation in foundation model development. Prior work relies on slow, manual experimentation by human experts, which struggles with the vast, open-ended space of possible symbolic formulations and often yields suboptimal or brittle laws. Their main contribution is SLDAgent, an evolution-based agent that co-optimizes both the functional form and parameters of scaling laws, achieving state-of-the-art extrapolation accuracy across eight diverse tasks in their new benchmark, SLDBench, and producing laws that are not only more accurate but also more conceptually principled than human-derived counterparts.
Dataset

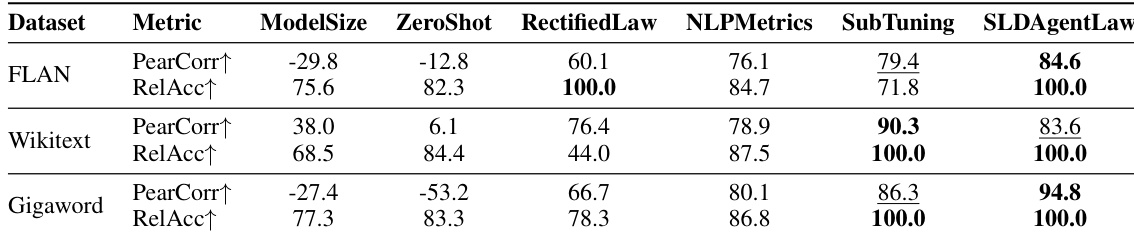
The authors use SLDBench, a curated benchmark for scaling law discovery, composed of eight real-world tasks sourced from recent literature and surveys. Each task involves predicting a symbolic scaling law from observed experimental data, with input features (e.g., model size, dataset size, learning rate), target values (e.g., loss, Brier score), and control indices (e.g., model architecture or dataset domain) to allow per-setting parameter fitting.
Key subsets and their details:
- Parallel Scaling Law: 36 seen / 12 unseen data points. Features: model size and parallelism degree. Unseen: 8-way parallelism (2x extrapolation over seen 1–4 way).
- Vocabulary Scaling Law: 1,080 seen / 120 unseen. Features: non-vocab parameters, vocab size, character count. Unseen: vocab size fixed at 96,300 (1.5x larger than seen max).
- Supervised Finetuning (SFT): 504 seen / 42 unseen. Features: SFT data size per model-dataset pair. Unseen: fixed 819,200 tokens (2x extrapolation over seen max 410,000).
- Domain Mixture: 80 seen / 24 unseen. Features: five domain proportions across four model sizes. Split follows original repository.
- Mixture of Experts (MoE): 193 seen / 28 unseen. Features: dense parameters, expert count. Unseen: 1.31B dense params (3.6x larger than seen max 368M).
- Data-Constrained: 161 seen / 21 unseen. Features: model size, tokens, unique tokens. Unseen: largest and second-largest N or D values.
- Learning Rate & Batch Size: 2,702 total points. Features: lr, bsz, data size, non-embedding params. No explicit train/test split described; used for full fitting.
- U-Shaped Scaling Law: 389 seen / 127 unseen. Features: log FLOPs. Unseen: final ascending phase from original paper to test double-descent behavior.
The authors use the training splits to evolve symbolic expressions and optimization routines via an LLM-powered agent system. Each task requires the agent to output a Python function that predicts targets given inputs and a control group, with a fixed functional form but group-specific parameters. The test set is always held out for extrapolation evaluation—typically selecting larger model sizes, bigger datasets, or more extreme hyperparameters.
All tasks are evaluated in a sandbox environment with scikit-learn, pandas, and datasets preinstalled. Agents produce two files: a law.py with the scaling function and an explain.md detailing the formula, reasoning, and fitted parameters. The final metric is R² on the unseen test set, with perfect performance near 1.0.
Metadata and processing are standardized per task: features and targets are explicitly defined, and parameter limits are enforced (e.g., max 4–7 parameters). No input-dependent features (e.g., min, max) are allowed in the scaling law function. The system tests generalization across control groups and extrapolation beyond training ranges, making SLDBench uniquely suited for evaluating agentic scientific discovery.
Method
The authors leverage an evolutionary framework to discover scaling laws through the co-evolution of two core subroutines: an expression function and an optimization routine. As illustrated in the framework diagram, the system begins with an initialization phase where a baseline program pair is established, typically consisting of a power-law expression and a standard BFGS optimizer. This initial program is executed and stored in an evolutionary database along with its fitness score, which is computed as the R2 coefficient on the training data.
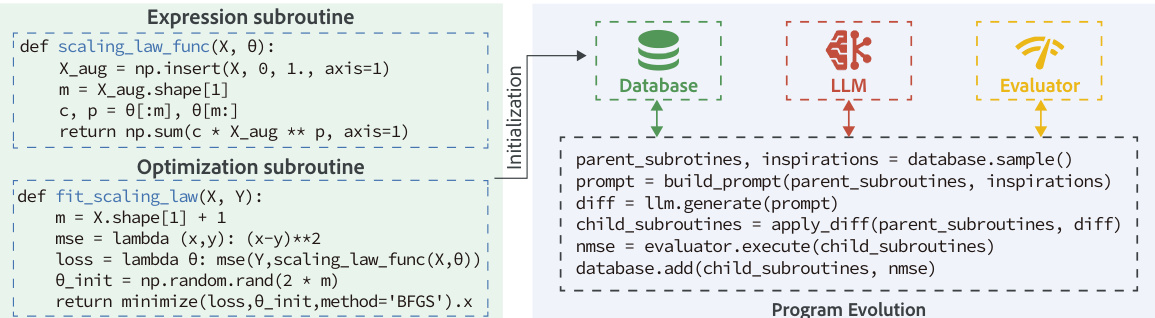
The expression subroutine, defined as fθ:x↦y^, implements a function that maps input features x to a prediction y^ using parameters θ. The optimization subroutine, on the other hand, is responsible for finding the best-fit parameters θ^=argminθL(y,fθ(x)) for a given loss function L, thereby producing a parameterized scaling law ready for extrapolation. During each evolution step, a parent program is selected from the database using a probabilistic mixture that emphasizes high-scoring programs (exploitation, 70%), diversity (20%), and top performers (elitism, 10%). This parent, along with several high-performing "inspiration" programs, is contextualized into a structured prompt. The large language model (LLM) then generates a modification of the parent's code, such as altering the law form, changing the optimizer, or tuning global variables. The resulting child program is executed, with its optimization routine fitting the expression on the given dataset, and the R2 score on the training data is computed. The new child and its score are then added to the database for subsequent generations. The evolutionary loop terminates after a fixed budget of iterations, and the program with the highest score in the final database is returned as the proposed law. The test set remains untouched throughout the entire evolution process.
Experiment
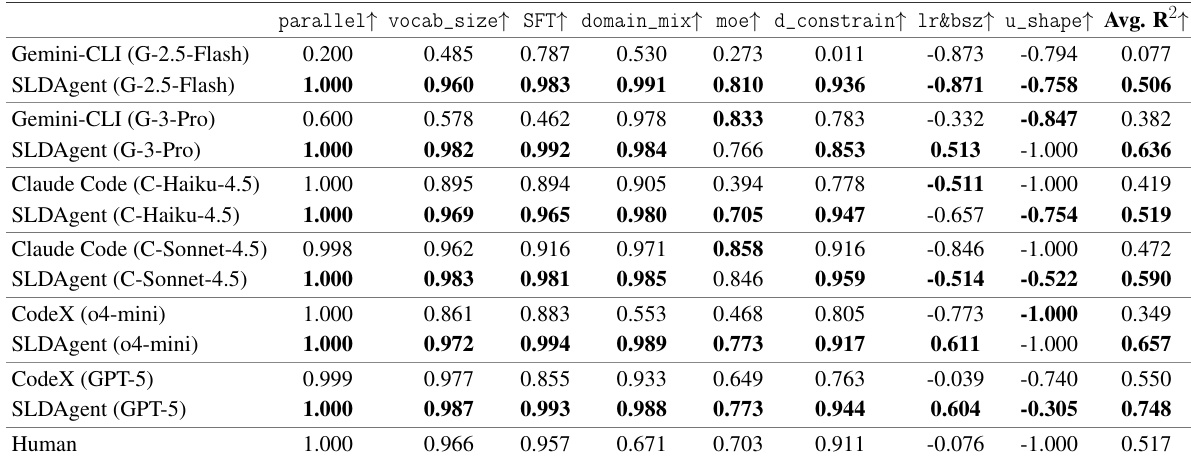
- SLDAgent outperforms 8 baseline agents (including Aider, Terminus, OpenHands, Codex, OpenCode, Goose, Mini-SWE-Agent, and human experts) on SLDBench, achieving R²=0.748 with GPT-5, surpassing the human baseline (R²=0.517) and matching or exceeding human performance on all tasks except lr&bsz.
- Paired with multiple LLMs (Gemini-2.5-Flash, Gemini-3-Pro, Claude-Haiku-4.5, Claude-Sonnet-4.5, GPT-5, o4-mini), SLDAgent consistently improves over native CLI agents, gaining +0.100 to +0.429 in R², with strongest gains on smaller models.
- On task difficulty: SLDAgent excels on easy (parallel, R²=1.000) and medium (moe) tasks, and improves on hard tasks (lr&bsz, u_shape), though some remain below human performance, revealing model-capacity limits.
- SLDAgent discovers more effective scaling laws: e.g., for sft, its law uses dimensionally consistent (D/θ₃) scaling for clearer interpretation; for moe, it finds a separable, asymptotically stable form (R²=0.891 vs. human’s 0.732).
- In LLM selection (Sec 4.5), SLDAgent’s discovered law achieves 100.0% RelAcc and 87.7% PearCorr across 3 datasets, outperforming 5 baselines including RectifiedLaw, NLPMetrics, SubTuning, ModelSize, and ZeroShot.
- Ablation confirms co-optimizing symbolic expression and fitting procedure is critical: full SLDAgent (R²=0.848) outperforms law-only variant (R²=0.775), especially on lr&bsz (0.194 vs. -0.224).
- Evolutionary search (50 iterations, 5 islands) robustly improves performance over time without overfitting, stabilizing on easy/medium tasks and trending upward on hard tasks.
Results show that SLDAgent achieves superior performance compared to baseline agents and native CLI systems across multiple model families, with average R2 scores consistently higher than those of the provider-specific agents. The agent matches or exceeds human performance on all tasks when paired with GPT-5, demonstrating that its design enables robust scaling law discovery even in the presence of model-capacity limitations.
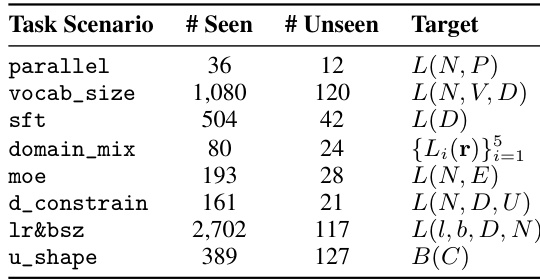
Results show that SLDAgentLaw achieves the highest performance across all datasets and metrics, outperforming all baselines including ZeroShot, RectifiedLaw, NLPMetrics, and SubTuning. On the FLAN dataset, SLDAgentLaw attains a perfect Relative Accuracy of 100.0% and a Pearson Correlation of 84.6%, while on Wikitext and Gigaword it consistently achieves top scores, demonstrating its superior ability to select optimal LLMs for fine-tuning.
The authors use SLDAgent to discover scaling laws and compare its performance against an ablation that only evolves the law's expression. Results show that the full SLDAgent achieves a higher average R² score (0.848) compared to the law-only variant (0.775), with significant improvements on challenging tasks like lr&bsz, indicating that co-optimizing the symbolic expression and fitting procedure is critical for success.

Results show that SLDAgent achieves the highest average R2 score of 0.748 when paired with GPT-5, outperforming all baseline agents and matching human performance on the easy parallel task while exceeding it on all others. Across different model families, SLDAgent consistently improves upon native CLI systems, with gains ranging from +0.100 to +0.429 in R2, and it matches or exceeds human performance on every task when using GPT-5.
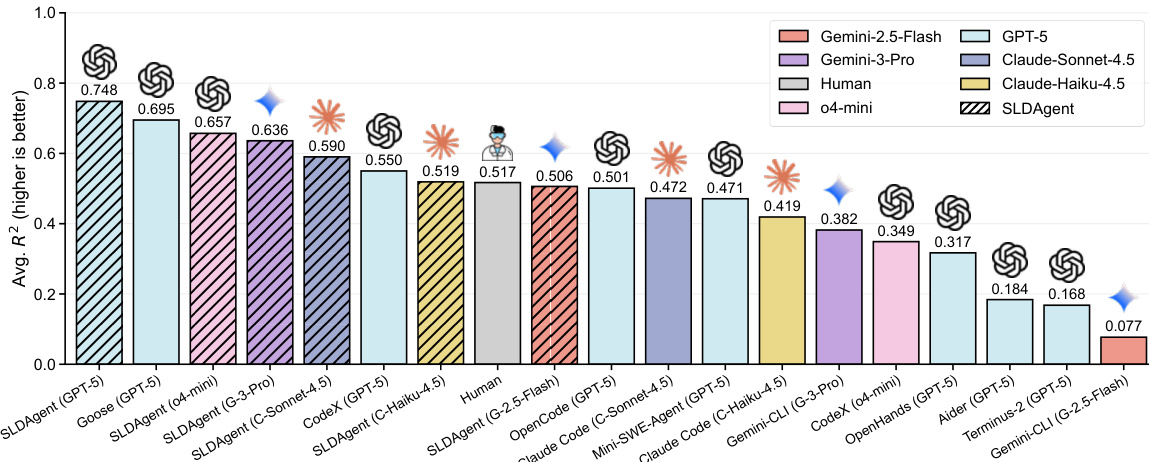
Results show that SLDAgent consistently outperforms native CLI systems across all model families, achieving higher average R2 scores on most tasks. When paired with GPT-5, SLDAgent matches or exceeds human performance on every task, achieving the highest overall average R2 of 0.748.