Command Palette
Search for a command to run...
ATLAS: Adaptive Transfer Scaling Laws for Multilingual Pretraining, Finetuning, and Decoding the Curse of Multilinguality
ATLAS: Adaptive Transfer Scaling Laws for Multilingual Pretraining, Finetuning, and Decoding the Curse of Multilinguality
Shayne Longpre Sneha Kudugunta Niklas Muennighoff I-Hung Hsu Isaac Caswell Alex Pentland Sercan Arik Chen-Yu Lee Sayna Ebrahimi
Abstract
Scaling laws research has focused overwhelmingly on English -- yet the most prominent AI models explicitly serve billions of international users. In this work, we undertake the largest multilingual scaling laws study to date, totaling 774 multilingual training experiments, spanning 10M-8B model parameters, 400+ training languages and 48 evaluation languages. We introduce the Adaptive Transfer Scaling Law (ATLAS) for both monolingual and multilingual pretraining, which outperforms existing scaling laws' out-of-sample generalization often by more than 0.3 R^2. Our analyses of the experiments shed light on multilingual learning dynamics, transfer properties between languages, and the curse of multilinguality. First, we derive a cross-lingual transfer matrix, empirically measuring mutual benefit scores between 38 x 38=1444 language pairs. Second, we derive a language-agnostic scaling law that reveals how to optimally scale model size and data when adding languages without sacrificing performance. Third, we identify the computational crossover points for when to pretrain from scratch versus finetune from multilingual checkpoints. We hope these findings provide the scientific foundation for democratizing scaling laws across languages, and enable practitioners to efficiently scale models -- beyond English-first AI.
One-sentence Summary
Researchers from MIT, Stanford, Google Cloud AI, and Google DeepMind introduce ATLAS, a novel scaling law for multilingual models that outperforms prior methods by 0.3+ R², enabling efficient cross-lingual scaling and transfer while addressing the curse of multilinguality for global AI democratization.
Key Contributions
- We introduce ATLAS, a novel adaptive transfer scaling law for monolingual and multilingual pretraining that significantly improves out-of-sample generalization over prior scaling laws, often by more than 0.3 R², based on 774 experiments across 400+ languages and model sizes from 10M to 8B parameters.
- We construct the first large-scale 38×38 cross-lingual transfer matrix, empirically quantifying mutual benefit and interference across 1444 language pairs, offering a foundational resource for understanding multilingual learning dynamics and transfer efficiency.
- We derive practical scaling guidelines for the “curse of multilinguality” and identify computational crossover points between pretraining from scratch and finetuning from multilingual checkpoints, enabling efficient scaling decisions when expanding language coverage.
Introduction
The authors leverage large-scale multilingual experiments to address the lack of scaling laws beyond English, which matters because most real-world AI models serve global users but are optimized using English-centric frameworks. Prior work either focused narrowly on small models, limited language pairs, or ignored how adding languages degrades performance due to capacity constraints—known as the “curse of multilinguality.” Their main contribution is ATLAS, an adaptive transfer scaling law that improves out-of-sample generalization by over 0.3 R², alongside a 38x38 cross-lingual transfer matrix, a scaling law for managing multilingual capacity trade-offs, and a practical formula to decide when pretraining from scratch beats fine-tuning from multilingual checkpoints.
Dataset

The authors use the MADLAD-400 dataset — a CommonCrawl-derived corpus covering 400+ languages — as the primary pretraining source, with curated multilingual filtering and preprocessing. For evaluation, they select 50 languages that overlap between MADLAD-400 and Flores-200, chosen to span diverse families, scripts, and resource levels, using a stratified sampling method with manual adjustments to avoid typological redundancy.
Key subset details:
- MADLAD-400 Test Set: For each of the 50 languages, they sample 20M tokens or 20% of total tokens (whichever is smaller), totaling ~20.5M tokens per language, to ensure stable loss measurements using the vocabulary-insensitive metric from Tao et al. (2024).
- Flores-101: Used as a secondary test set; monolingual sequences are extracted from the parallel corpus to compute comparable sequence-level losses.
Training setup:
- Models range from 10M to 8B parameters, using a 64K SentencePiece vocabulary.
- They train 280 monolingual, 240 bilingual, and 120 multilingual models (including Unimax-style mixtures), plus 130 finetuned models — over 750 total runs.
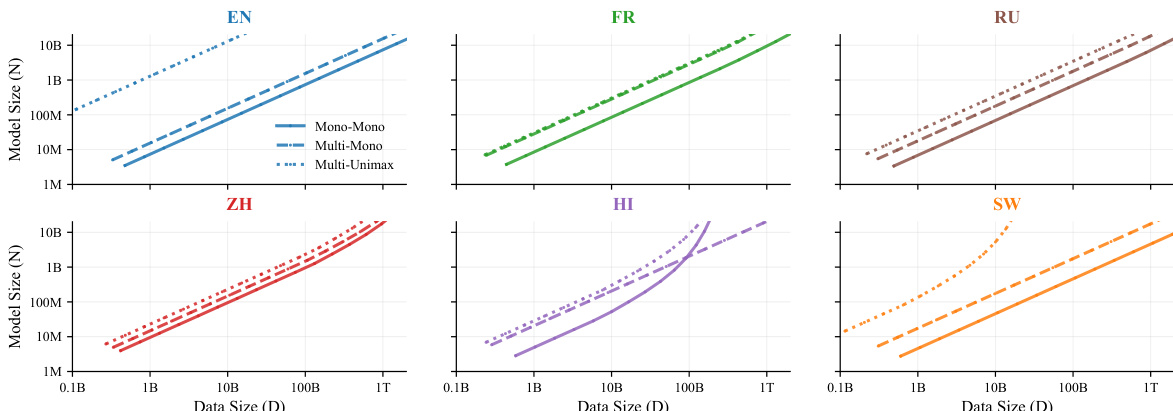
- Experiments vary model size (N), training tokens (D), and language mixtures (M), with core focus on English, French, Chinese, Hindi, Swahili, Russian, Spanish, Portuguese, and Japanese.
- Training hyperparameters follow Kudugunta et al. (2024), with refinements based on recent work.
Evaluation strategy:
- Scaling laws are evaluated via R² on held-out test sets, separately for four dimensions: largest model sizes (N), largest token counts (D), highest compute (C), and unseen language mixtures (M).
- R² is averaged across languages: [EN, FR, RU, ZH, HI, SW] for monolingual, plus [ES, DE] for multilingual settings.
- The vocabulary-insensitive loss ensures fair cross-lingual comparison across all test sets.
Method
The authors introduce the Adaptive Transfer Scaling Law (ATLAS), a unified framework designed to model scaling behavior in both monolingual and multilingual settings while accounting for data repetition and cross-lingual transfer effects. ATLAS builds upon the standard scaling law form, which expresses loss as a function of model size N and effective data exposure Deff, given by:
L(N,Deff)=E+NαA+DeffβBThe core innovation lies in the definition of Deff, which decomposes total data exposure into three distinct components: a monolingual term for the target language, a transfer language term capturing cross-lingual influence, and a remainder term for all other languages. This decomposition is formalized as:
Deff=MonolingualSλ(Dt;Ut)+Transfer Languagesi∈K∑τiSλ(Di;Ui)+Other LanguagesτotherSλ(Dother;Uother)Each component uses a saturation function Sλ(D;U) to model the diminishing returns of data repetition beyond one epoch. This function is defined as:
Sλ(D;U)={D,U[1+λ1−exp(−λ(D/U−1))],D≤U(≤1 epoch)D>U(>1 epoch)The parameter λ governs the rate of saturation and is shared across all data sources, ensuring consistency in how repetition affects effective data exposure. The transfer weights τi and τother are learned parameters that quantify the relative contribution of each language group to the target language's performance. These weights are initialized using language transfer scores derived from prior analysis, enabling ATLAS to adaptively model cross-lingual transfer dynamics.
The framework is designed to be robust across varying data collection constraints and training regimes. By explicitly separating monolingual and transfer contributions, ATLAS avoids the limitations of prior approaches that either ignore data repetition or fail to distinguish between different types of cross-lingual effects. This modular design allows the model to generalize effectively to out-of-sample dimensions, including larger model sizes, extended data ranges, and unseen language mixtures. The inclusion of a single, shared repetition parameter λ and a flexible transfer weight structure ensures that ATLAS remains computationally efficient while capturing complex scaling behaviors in multilingual settings.
Experiment
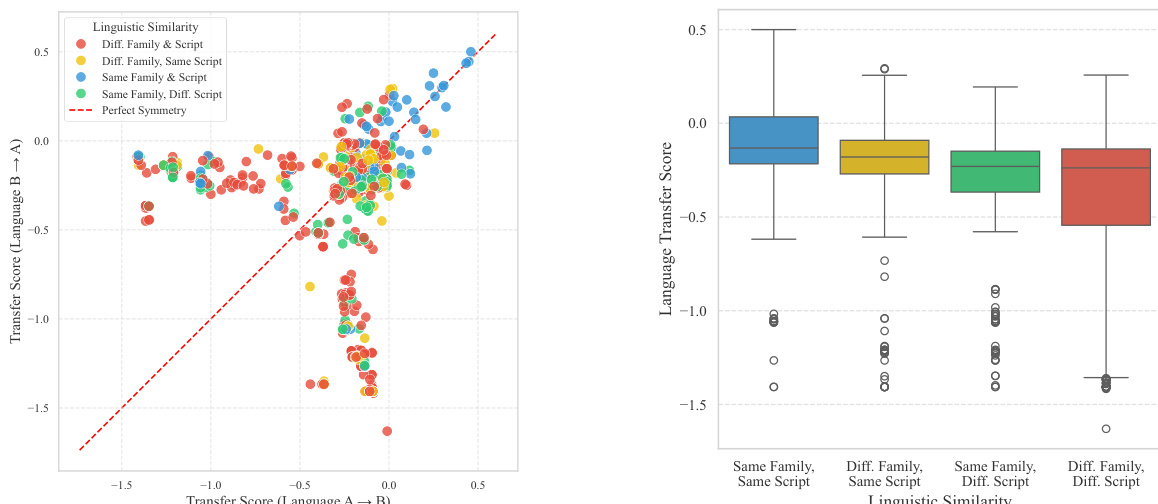
- Constructed a 30×30 (and 38×38) cross-lingual transfer matrix using Bilingual Transfer Score (BTS), revealing that English is the top source language for 19/30 targets, followed by French (16/30), Spanish (13/30), and Hebrew (11/30); low-resource languages like Urdu and Pashto show consistent negative transfer.
- Found strong correlation between positive transfer and shared script (mean BTS: -0.23) or language family (p < 0.001), with script having larger effect size than family; transfer is symmetric only within shared script/family pairs (e.g., French-Spanish), but asymmetric otherwise (e.g., Chinese-Farsi).
- Quantified the “curse of multilinguality”: adding languages (K) increases target loss, mitigated more effectively by scaling model size (N) than data (D); scaling law L(K,N,D) = L∞ + A·K^φ/N^α + B·K^ψ/D^β fitted with φ=0.11, ψ=-0.04 (R²≥0.87), confirming mild capacity penalty offset by positive transfer.
- Derived compute-optimal scaling: to expand from K to r·K languages without loss degradation, scale model size by r^(φ/α) ≈ r^0.11/α and total tokens by r^(1+ψ/β) ≈ r^(1-0.04/β); e.g., 4× languages requires 1.4× N and 2.74× D_tot, enabling 32% less data per language via transfer.
- For pretrain vs finetune: finetuning from Unimax checkpoint outperforms scratch pretraining under 144B–283B tokens; beyond that, scratch pretraining wins; compute threshold modeled as log(C) = 1.1M × N^1.65, enabling practitioners to choose based on budget and model size.
- Validated BTS scalability: transfer scores improve with larger models and stabilize early in training; larger models mitigate negative transfer (e.g., en→zh), turning interference toward neutrality, while synergistic pairs (e.g., es→pt) show modest gains.
The authors use bilingual transfer scores to measure how training on a source language affects the performance of a target language, with positive scores indicating beneficial transfer and negative scores indicating interference. The results show that language similarity, particularly shared language families and scripts, strongly predicts transfer effectiveness, with English being the most beneficial source language for many targets, while low-resource languages often exhibit negative transfer.
The authors use a comprehensive set of experiments to measure cross-lingual transfer and the impact of multilingual training on model performance. Results show that language similarity, particularly shared language family and script, strongly predicts positive transfer, with English being the most beneficial source language for many targets. Additionally, larger models mitigate negative interference and improve transfer efficiency, while the curse of multilinguality is partially offset by positive cross-lingual transfer.
The authors use bilingual transfer scores to measure how training on a source language affects the performance of a target language, finding that language similarity—particularly shared language family and script—strongly predicts positive transfer. Results show that pairs sharing both family and script exhibit the most symmetric and positive transfer, while those with differing family and script show greater asymmetry and negative transfer, with script similarity having a stronger effect than family.
The authors use a range of model scales from 10 million to 8 billion parameters, with varying numbers of attention heads, layers, embedding sizes, and feedforward widths, to study multilingual learning dynamics. The table provides the specific architectural configurations for each scale, which are used in experiments to measure language transfer and model capacity effects.
The authors compare scaling laws for monolingual and multilingual models, finding that their proposed multilingual scaling law achieves strong performance across different evaluation metrics. The [Ours] ATLAS (Dt + Dother + ∑κt Di) model outperforms existing baselines, particularly in multilingual settings, with high R² values indicating robust fit and generalization.
