Command Palette
Search for a command to run...
The World is Your Canvas: Painting Promptable Events with Reference Images, Trajectories, and Text
The World is Your Canvas: Painting Promptable Events with Reference Images, Trajectories, and Text
Abstract
We present WorldCanvas, a framework for promptable world events that enables rich, user-directed simulation by combining text, trajectories, and reference images. Unlike text-only approaches and existing trajectory-controlled image-to-video methods, our multimodal approach combines trajectories -- encoding motion, timing, and visibility -- with natural language for semantic intent and reference images for visual grounding of object identity, enabling the generation of coherent, controllable events that include multi-agent interactions, object entry/exit, reference-guided appearance and counterintuitive events. The resulting videos demonstrate not only temporal coherence but also emergent consistency, preserving object identity and scene despite temporary disappearance. By supporting expressive world events generation, WorldCanvas advances world models from passive predictors to interactive, user-shaped simulators. Our project page is available at: https://worldcanvas.github.io/.
One-sentence Summary
Researchers from HKUST, Ant Group, et al. propose WorldCanvas, a framework that uniquely integrates text prompts, motion-encoded trajectories, and reference images for visual grounding to generate controllable world events. Unlike prior text-only or trajectory-limited methods, it enables multi-agent interactions, object entry/exit, and counterintuitive scenarios while preserving emergent consistency, advancing world models into interactive simulators for complex event simulation.
Key Contributions
- WorldCanvas addresses the limitation of existing world models that function as passive predictors with minimal user control, by introducing a framework for generating semantically meaningful "promptable world events" where users can actively shape environmental dynamics beyond simple observation.
- The framework uniquely integrates trajectories for motion and timing, reference images for object identity, and natural language for semantic intent through a Spatial-Aware Weighted Cross-Attention mechanism, enabling precise control over complex events like multi-agent interactions and object entry/exit.
- Generated videos demonstrate temporal coherence and emergent object consistency, preserving identity and scene context during temporary occlusions, while supporting counterintuitive events and reference-guided appearance without requiring quantitative benchmarks or specific datasets.
Introduction
World models traditionally focus on passive prediction through low-level reconstruction, limiting user control to navigation rather than active environmental changes. Prior text-prompted approaches lack spatial and temporal precision for complex events, while trajectory-controlled video generation methods treat motion paths as coarse positional cues without modeling visibility, timing, or object identity, resulting in poor controllability for multi-agent interactions or object entry/exit scenarios. The authors leverage a multimodal framework—WorldCanvas—that integrates natural language for semantic intent, reference images for visual grounding, and trajectories encoding motion, timing, and visibility to enable precise specification of "what, when, where, and who" in world events. Their contribution includes a curated multimodal data pipeline and a Spatial-Aware Weighted Cross-Attention mechanism that fuses these inputs into a pretrained video model, achieving coherent generation of counterintuitive events with emergent object consistency during occlusions. This advances world models from passive predictors to interactive simulators capable of user-directed environmental dynamics.
Dataset
The authors curate a dataset of trajectory-reference-text triplets to enable precise semantic-spatiotemporal alignment in multi-agent scenes. Key details include:
-
Sources and composition:
Built from publicly available videos segmented into shot-consistent clips. Each triplet links a tracked object trajectory, a motion-focused caption, and a transformed reference image. -
Subset processing:
- Tracking: Objects detected via YOLO in the first frame; masks generated with SAM. 1–3 representative keypoints per mask (plus background points) tracked using CoTracker3. Random cropping simulates objects entering the scene, while motion-score filtering (based on cumulative displacement) removes near-static clips.
- Captioning: Trajectories visualized on videos (colored by object identity) are captioned using Qwen2.5-VL 72B. Captions retain minimal subject identifiers (e.g., "a man") paired with motion descriptions, ensuring motion-centric language.
- Reference images: Foreground objects from the first frame undergo mild affine transformations (translation, scaling, rotation) to create flexible starting positions for interactive generation.
-
Usage in training:
The pipeline produces triplets where captions explicitly correspond to individual trajectories. Reference images enable visual grounding, while cropped frames and transformed objects simulate off-screen entry. These triplets train the model’s Spatial-Aware Weighted Cross-Attention to align captions with trajectories, supporting user-controlled animation via drag-and-drop interfaces. No explicit split ratios are specified, but motion-score filtering ensures high-quality dynamic sequences dominate the training data.
Method
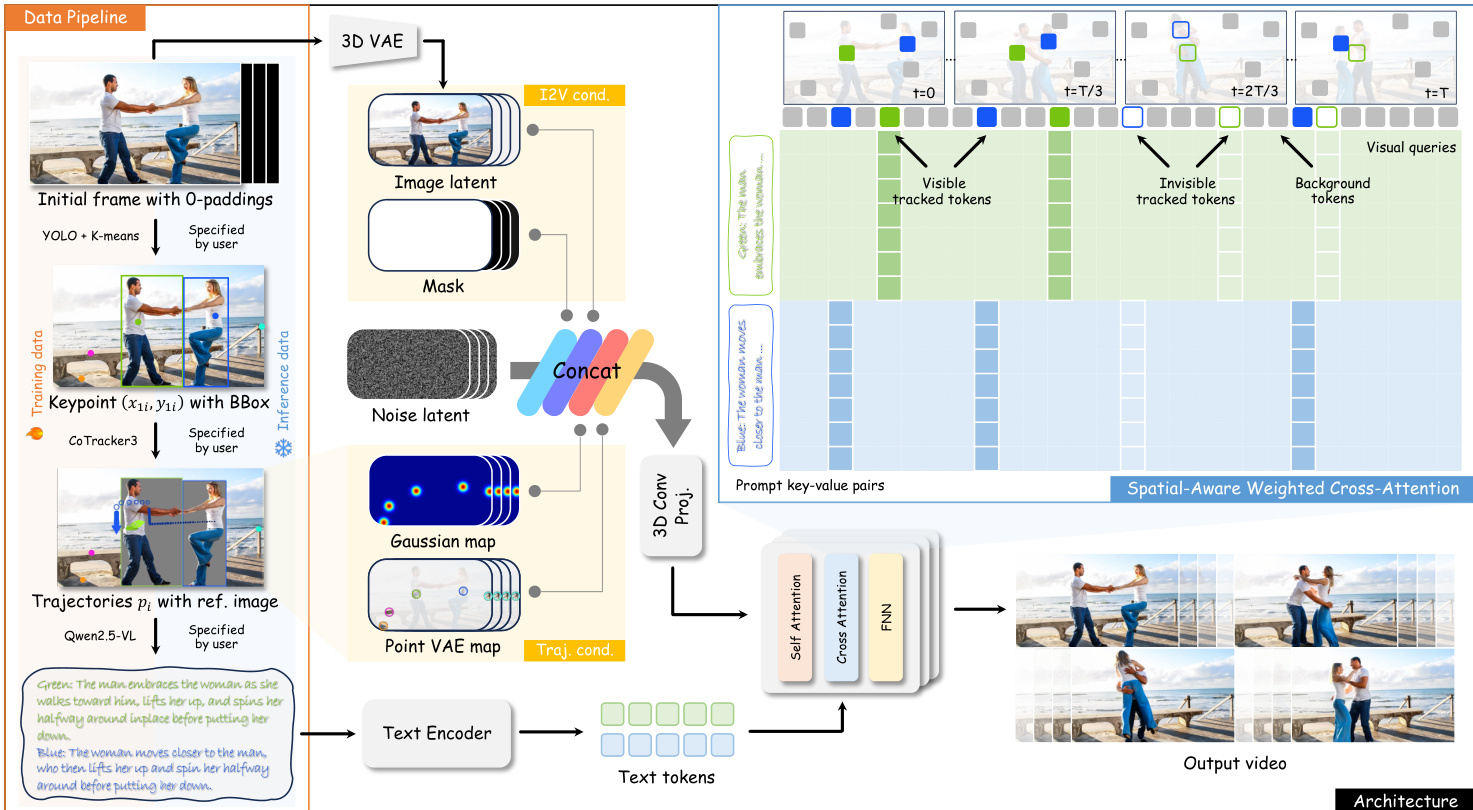
The authors leverage a multimodal conditioning framework built atop the Wan2.2 I2V 14B model to enable fine-grained, trajectory-guided video generation. The core innovation lies in the structured integration of three modalities—trajectories, reference images, and motion-focused text—into the diffusion process, allowing users to specify “when, where, who, and what” for each agent in the scene. The overall architecture is designed to bind textual semantics to spatial motion cues while preserving visual identity through reference conditioning.
Refer to the framework diagram, which illustrates the end-to-end pipeline from data preparation to video synthesis. The system begins with a data curation stage where trajectories are extracted from video frames using CoTracker3, paired with bounding boxes from YOLO + K-means, and annotated with action-centric captions via Qwen2.5-VL. These triplets (pi,bboxi,capi) form the training signal, where pi={(xti,yti,vti)}t=1T encodes 2D positions and visibility per frame, bboxi anchors the object’s initial appearance, and capi describes the motion semantics.
During training, trajectory information is injected into the DiT backbone via two complementary representations: a Gaussian heatmap encoding spatial occupancy and a Point VAE map that propagates the initial-frame VAE latent from each trajectory’s keypoint across its temporal path. These are concatenated with the standard DiT inputs—noise latent, image latent, and mask—and processed through a 3D convolutional projection layer to align dimensions. This injection mechanism enables the model to condition motion generation on user-specified paths while preserving temporal coherence.
To resolve ambiguity in multi-agent scenarios, the authors introduce Spatial-Aware Weighted Cross-Attention. For each trajectory-caption pair, the model computes a spatial coverage region centered at each point (xti,yti) with dimensions matching bboxi. Visual query tokens Qi falling within this region are assigned higher attention weights when attending to the key-value pair KVi derived from capi. The weight bias Wqk is defined as:
Wqk={log(w),0,if vti=1 and Qq∈Qi and Kk∈Kiotherwisewhere w=30 is empirically set. The final attention output is computed as:
Attention(Q,K,V)=Softmax(DQKT+W)VThis mechanism ensures that each motion caption influences only the visual tokens spatially aligned with its trajectory, enabling localized semantic control without sacrificing global context.
Training follows a flow matching objective with L1 reconstruction loss. Given noise x0∼N(0,I), timestep t∈[0,1], and ground-truth video latent x1, the model predicts velocity vt=x1−x0 from the interpolated input xt=tx1+(1−t)x0. The loss is:
L=Ex0,x1,t,C[∥u(xt,t,C;θ)−vt∥2]where C aggregates all conditioning signals and θ denotes model parameters.
During inference, users interact with an intuitive interface that accepts trajectories as point sequences with configurable timing, spacing (for speed), and visibility flags (for occlusion or entry/exit). Each trajectory is bound to a motion caption, and reference images are inserted into the initial frame to define object appearance. The model then synthesizes a video that adheres to the specified spatiotemporal, semantic, and visual constraints.
Experiment
- Outperformed Wan2.2 I2V, ATI, and Frame In-N-Out on a custom benchmark of 100 image-trajectory pairs, achieving ObjMC 1.82 (vs. baselines 2.15–2.38), Appearance Rate 94.3% (vs. 89.7%–92.1%), and CLIP-T 0.31 (vs. 0.26–0.28), demonstrating superior trajectory following and semantic alignment.
- Achieved precise multi-subject trajectory-text alignment in complex scenarios (e.g., correctly binding distinct motions to textual descriptions in Fig. 4) where baselines failed, and maintained reference image consistency in guided generation.
- Validated robust consistency maintenance for objects and scenes during occlusions or off-screen intervals, preserving visual identity across frames (Fig. 5).
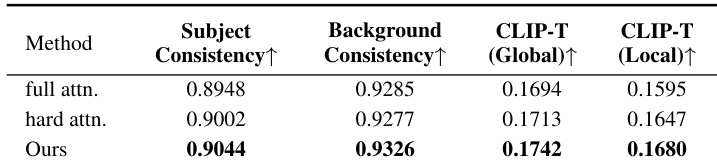
- Ablation confirmed Spatial-Aware Weighted Cross-Attention's necessity, as its removal increased ObjMC to 2.38 and reduced CLIP-T scores, causing semantic-action misalignment.
- Human evaluation showed 78.3% preference for trajectory following and 76.0% for prompt adherence, significantly surpassing all baselines across all criteria.
The authors evaluate WorldCanvas against three baselines using human judgments across five criteria, including trajectory following, prompt adherence, and reference fidelity. Results show WorldCanvas significantly outperforms all baselines, achieving the highest scores in every category, particularly in text-trajectory alignment and reference fidelity. This demonstrates its superior ability to generate controllable, semantically accurate, and visually consistent world events.

The authors evaluate their Spatial-Aware Weighted Cross-Attention mechanism against full and hard attention variants using consistency and semantic alignment metrics. Results show their method achieves the highest scores in both subject and background consistency, as well as global and local CLIP-T scores, confirming its effectiveness in aligning text with trajectories. This demonstrates that spatial weighting improves multi-agent event generation by preserving semantic and visual fidelity.
The authors evaluate WorldCanvas against three baselines using quantitative metrics for trajectory following, temporal consistency, and semantic alignment. Results show that WorldCanvas achieves the best performance across all metrics, including the lowest ObjMC score and highest Appearance Rate, Subject Consistency, and Background Consistency, demonstrating superior control and fidelity in generating promptable world events.
