Command Palette
Search for a command to run...
LightOnOCR: A 1B End-to-End Multilingual Vision-Language Model for State-of-the-Art OCR
LightOnOCR: A 1B End-to-End Multilingual Vision-Language Model for State-of-the-Art OCR
Said Taghadouini Adrien Cavaillès Baptiste Aubertin
Abstract
We present \textbf{LightOnOCR-2-1B}, a 1B-parameter end-to-end multilingual vision--language model that converts document images (e.g., PDFs) into clean, naturally ordered text without brittle OCR pipelines. Trained on a large-scale, high-quality distillation mix with strong coverage of scans, French documents, and scientific PDFs, LightOnOCR-2 achieves state-of-the-art results on OlmOCR-Bench while being 9× smaller and substantially faster than prior best-performing models. We further extend the output format to predict normalized bounding boxes for embedded images, introducing localization during pretraining via a resume strategy and refining it with RLVR using IoU-based rewards. Finally, we improve robustness with checkpoint averaging and task-arithmetic merging. We release model checkpoints under Apache 2.0, and publicly release the dataset and \textbf{LightOnOCR-bbox-bench} evaluation under their respective licenses.
One-sentence Summary
LightOn researchers introduce LightOnOCR-2-1B, a compact 1B-parameter multilingual vision-language model that directly extracts clean, ordered text from document images, outperforming larger models while adding image localization via RLVR and robustness via checkpoint merging, with open-sourced models and benchmarks.
Key Contributions
- LightOnOCR-2-1B is a compact 1B-parameter end-to-end multilingual vision-language model that achieves state-of-the-art OCR performance on OlmOCR-Bench, outperforming larger 9B-scale models while being 9x smaller and significantly faster.
- The model is trained on a 2.5x larger, high-quality distillation dataset with enhanced coverage of scans, French documents, and scientific PDFs, using higher-resolution inputs and data augmentations to improve robustness and layout fidelity.
- It introduces image bounding box prediction via coordinate supervision during pretraining and RLVR refinement with IoU rewards, validated on the new LightOnOCR-bbox-bench, and boosts reliability using checkpoint averaging and task-arithmetic merging.
Introduction
The authors leverage a compact 1B-parameter end-to-end vision-language model to tackle document OCR without brittle multi-stage pipelines, addressing real-world challenges like ambiguous reading order, dense scientific notation, and noisy scans. Prior systems rely on complex, component-coupled workflows that are costly to adapt and brittle under domain shifts. LightOnOCR-2-1B achieves state-of-the-art results on OlmOCR-Bench while being 9x smaller and faster than prior models, thanks to a 2.5x larger, high-quality training mix with enhanced coverage of French and scientific documents, higher-resolution inputs, and RLVR-guided refinement. It also extends OCR with image localization via predicted bounding boxes, trained with coordinate supervision and IoU-based rewards, and introduces a new benchmark (LightOnOCR-bbox-bench) alongside lightweight weight-space techniques for controllable OCR-bbox trade-offs.
Dataset

-
The authors use a large-scale OCR training corpus built via distillation, where strong vision-language models generate transcriptions from rendered PDF pages. LightOnOCR-1 was trained on the PDFA dataset using Qwen2-VL-72B-Instruct as the teacher; LightOnOCR-2-1B upgrades the teacher to Qwen3-VL-235B-A22B-Instruct for better math fidelity and fewer artifacts.
-
The LightOnOCR-2-1B dataset combines teacher-annotated pages from multiple sources including scanned documents for robustness, plus auxiliary data for layout diversity. It includes cropped regions (paragraphs, headers, abstracts) annotated with GPT-4o, blank-page examples to suppress hallucinations, and TeX-derived supervision from arXiv via the nvpdftex pipeline. Public OCR datasets are added for extra diversity.
-
Training data is normalized to a canonical format: stray Markdown, watermarks, and format drift are stripped; blank pages and embedded images are mapped to fixed targets; deduplication and repetition filtering are applied. LaTeX is validated for KaTeX compatibility, and metadata (e.g., unresolved references, conversion status) is logged to guide filtering.
-
The nvpdftex pipeline compiles arXiv TeX sources to generate pixel-aligned (image, markup, bounding box) triples, improving alignment over prior methods. These arXiv bounding boxes support RLVR experiments but are excluded from main pretraining. The pipeline also powers the LightOnOCR-bbox-bench benchmark, which evaluates image localization using 290 manually reviewed OlmOCR-Bench samples and 565 automatically annotated arXiv pages.
-
For training, the authors mix data subsets at chosen ratios, re-injecting blank-page examples at controlled rates. Bounding box annotations, though removed from main OCR targets, are retained and reformatted as a separate signal for bounding box addition tasks. The PDFA-derived subset is released under matching license as lightonai/LightOnOCR-mix-0126; normalized bounding box data is released as lightonai/LightOnOCR-bbox-mix-0126.
Method
The authors leverage a modular vision-language architecture for LightOnOCR, designed to perform optical character recognition without requiring task-specific prompts at inference. The framework consists of three primary components: a vision encoder, a multimodal projector, and a language model decoder. The vision encoder, based on a native-resolution Vision Transformer, is initialized from the pretrained Mistral-Small-3.1 vision encoder weights. This choice enables the model to process variable image sizes while preserving spatial structure, which is essential for handling documents with diverse aspect ratios and fine typographic details.
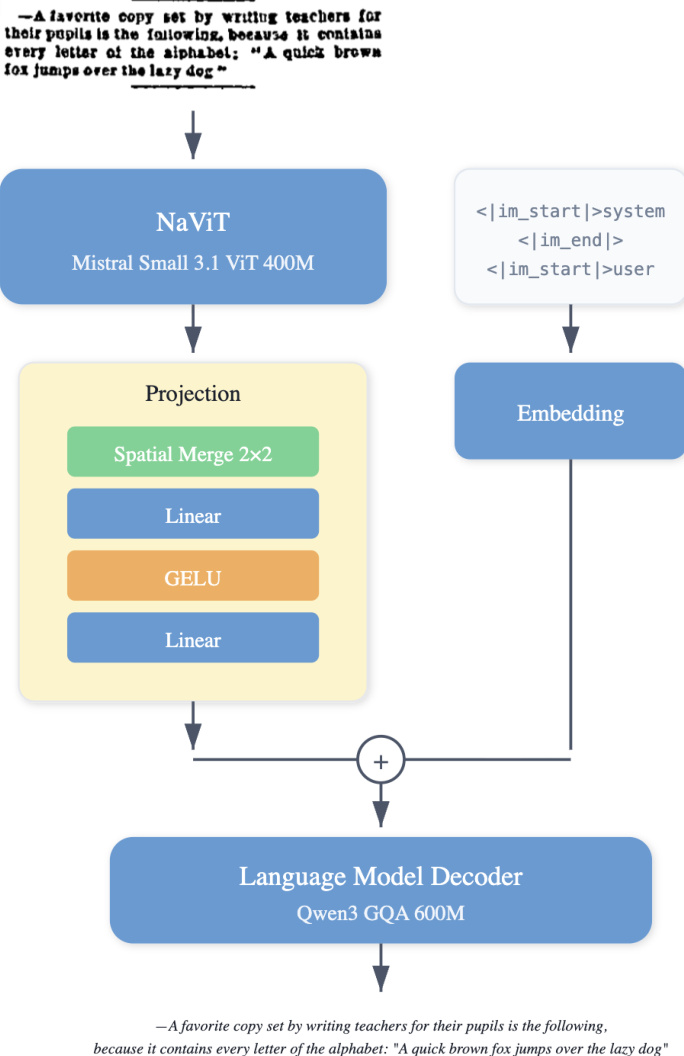
As shown in the figure below, the vision encoder processes the input image and outputs a sequence of visual tokens. To manage sequence length and bridge the vision and language modalities, a two-layer MLP with GELU activation is employed as the multimodal projector. Before projection, spatial merging with a factor of 2 is applied, grouping 2×2 patches and reducing the number of visual tokens by a factor of 4. This step ensures that the overall token count remains manageable for high-resolution inputs while retaining sufficient spatial granularity. The projector is randomly initialized and trained from scratch.
The language model decoder is initialized from the pretrained Qwen3 model. It generates a single, linearized representation of the page that preserves reading order and emits structured tokens for non-text elements, such as image placeholders. To simplify the interface between modalities, the decoder is conditioned on a single contiguous block of visual tokens (after spatial merging), followed by text tokens, eliminating the need for image-break and image-end tokens. This design results in a compact end-to-end vision-language model with a consistent generation format across datasets.
The model's initialization from strong pretrained components allows LightOnOCR to inherit robust visual representations and multilingual language modeling capabilities, facilitating effective transfer to OCR tasks with reduced training cost. The architecture is further enhanced in LightOnOCR-2 through updates to the data and training recipe, including scaling the pretraining mixture, improving supervision quality, and increasing the maximum longest-edge resolution. Additionally, an image-localization variant is trained to predict bounding boxes for embedded images by extending the output format with normalized coordinates, which is refined using reinforcement learning with reward functions based on IoU. The training process also incorporates lightweight weight-space techniques, such as checkpoint averaging and task-arithmetic merging, to combine complementary gains and control trade-offs between OCR quality and localization accuracy.
Experiment
- Pretrained on filtered OCR corpus with augmentations and next-token prediction, optimized via AdamW on 96 H100 GPUs; achieved efficient training at 6144-token sequence length.
- Applied RLVR with GRPO to optimize OCR and bbox localization using verifiable rewards; improved performance with KL regularization and multi-rollout sampling.
- LightOnOCR-2-1B achieved 83.2 ± 0.9 on OlmOCR-Bench (excluding headers/footers), outperforming larger models despite 1B parameters; strong gains on ArXiv, math scans, and tables.
- RLVR reduced repetition loops and boosted OCR quality; bbox prediction introduced slight OCR drop, recoverable via task-arithmetic merging (α≈0.1) to balance OCR and IoU=0.677.
- On LightOnOCR-bbox-bench, LightOnOCR-2-1B-bbox surpassed 9B baseline in F1@0.5 and count accuracy while matching mean IoU, proving compact model efficacy for localization.
- Achieved highest inference throughput (pages/sec) on H100 among end-to-end baselines, enabling scalable document processing.
- Vocabulary pruning to 32k tokens improved speed 11.6% with 96% base OCR retention for Latin scripts, but inflated token count 3× for non-Latin scripts like Chinese.
- Model excels on printed scientific PDFs, multi-column layouts, and Latin-script documents; limited on non-Latin scripts and handwritten text due to training data bias.
- Evaluated on OmniDocBench v1.0, showing strong performance in its size class, particularly in reading order and layout fidelity for EN/ZH documents.
- RLVR explicitly rewarded header/footer presence, reducing scores under original OlmOCR-Bench headers/footers metric, which rewards suppression—misaligned with full-page transcription goal.
Results show that LightOnOCR-2-1B achieves the highest overall score on OlmOCR-Bench, outperforming larger models despite its 1B parameter size, with notable improvements in text editing and table accuracy. The model also demonstrates strong performance in localization tasks, achieving high F1 scores and count accuracy on image detection benchmarks while maintaining efficient inference throughput.
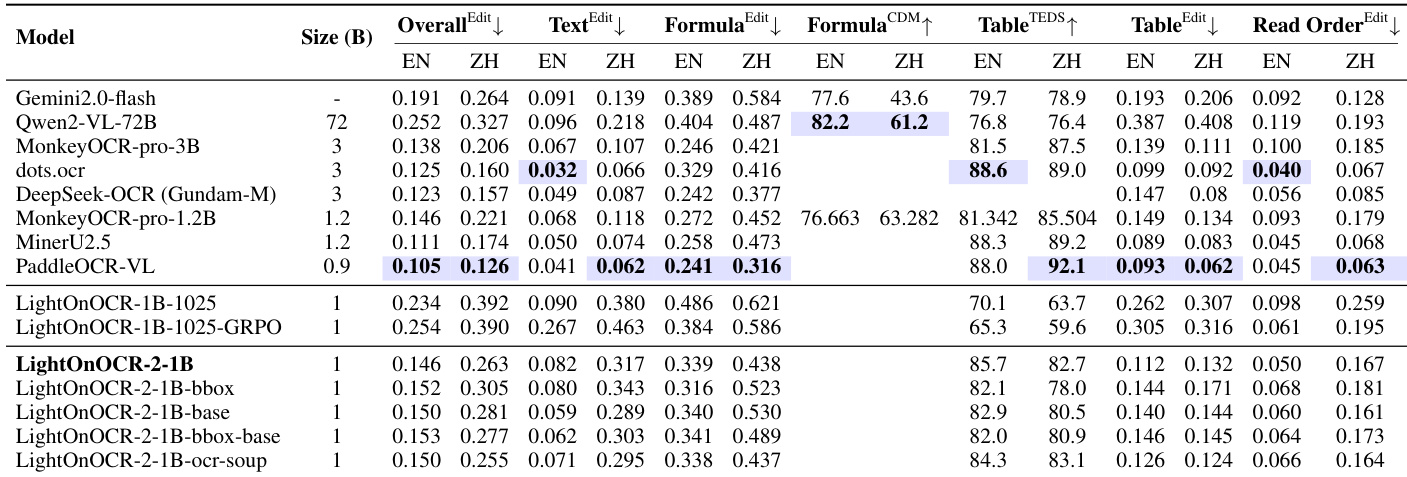
Results show that LightOnOCR-2-1B-bbox achieves higher F₁@0.5 and count accuracy than Chandra-9B on both OlmOCR and arXiv subsets, while maintaining comparable mean IoU, indicating improved detection of image presence and number with accurate localization. The bbox-soup variant slightly reduces performance compared to the base model but retains strong OCR quality.

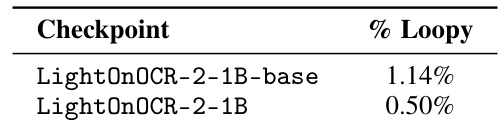
Results show that applying RLVR reduces the fraction of loopy generations in LightOnOCR-2-1B, with the base checkpoint exhibiting 1.14% loopy outputs and the RLVR-optimized version dropping to 0.50%. This indicates that the reinforcement learning process effectively mitigates repetition loops in model outputs.
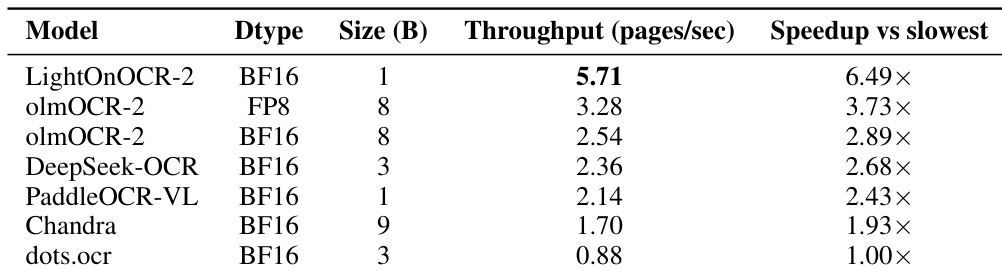
Results show that LightOnOCR-2 achieves a throughput of 5.71 pages per second, significantly outperforming olmOCR-2 and Chandra, which achieve 3.28 and 1.70 pages per second respectively, demonstrating its superior inference efficiency on a single NVIDIA H100 GPU.
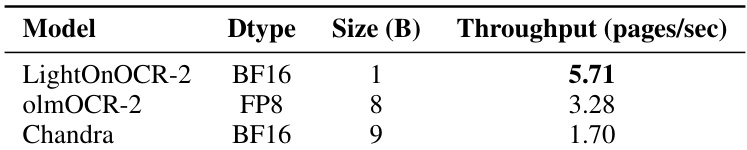
The authors evaluate the inference throughput of LightOnOCR-2 and compare it to other end-to-end OCR models, reporting that LightOnOCR-2 achieves a throughput of 5.71 pages per second, which is 6.49 times faster than the slowest model in the comparison. This demonstrates that LightOnOCR-2 provides substantially higher throughput than larger end-to-end baselines, making it practical for high-volume document processing.