Command Palette
Search for a command to run...
Inference-Time Scaling of Verification: Self-Evolving Deep Research Agents via Test-Time Rubric-Guided Verification
Inference-Time Scaling of Verification: Self-Evolving Deep Research Agents via Test-Time Rubric-Guided Verification
Yuxuan Wan Tianqing Fang Zaitang Li Yintong Huo Wenxuan Wang Haitao Mi Dong Yu Michael R. Lyu
Abstract
Recent advances in Deep Research Agents (DRAs) are transforming automated knowledge discovery and problem-solving. While the majority of existing efforts focus on enhancing policy capabilities via post-training, we propose an alternative paradigm: self-evolving the agent's ability by iteratively verifying the policy model's outputs, guided by meticulously crafted rubrics. This approach gives rise to the inference-time scaling of verification, wherein an agent self-improves by evaluating its generated answers to produce iterative feedback and refinements. We derive the rubrics based on an automatically constructed DRA Failure Taxonomy, which systematically classifies agent failures into five major categories and thirteen sub-categories. We present DeepVerifier, a rubrics-based outcome reward verifier that leverages the asymmetry of verification and outperforms vanilla agent-as-judge and LLM judge baselines by 12%-48% in meta-evaluation F1 score. To enable practical self-evolution, DeepVerifier integrates as a plug-and-play module during test-time inference. The verifier produces detailed rubric-based feedback, which is fed back to the agent for iterative bootstrapping, refining responses without additional training. This test-time scaling delivers 8%-11% accuracy gains on challenging subsets of GAIA and XBench-DeepResearch when powered by capable closed-source LLMs. Finally, to support open-source advancement, we release DeepVerifier-4K, a curated supervised fine-tuning dataset of 4,646 high-quality agent steps focused on DRA verification. These examples emphasize reflection and self-critique, enabling open models to develop robust verification capabilities.
One-sentence Summary
Researchers from CUHK, Tencent AI Lab, and collaborators propose DeepVerifier, a rubric-based verifier enabling test-time self-evolution of Deep Research Agents via iterative feedback, outperforming prior judge models by 12%-48% and boosting accuracy 8%-11% on GAIA/XBench, with open-source dataset release to advance community research.
Key Contributions
- We introduce DeepVerifier, a rubrics-based verification module that leverages the asymmetry of verification to self-improve Deep Research Agents at inference time, outperforming agent-as-judge and LLM judge baselines by 12%-48% in meta-evaluation F1 score on GAIA.
- We construct a DRA Failure Taxonomy with five major categories and thirteen sub-categories from real failure trajectories, enabling structured feedback that guides iterative refinement without additional training, yielding 8%-11% accuracy gains on GAIA and XBench-DeepResearch subsets.
- We release DeepVerifier-4K, a 4,646-example supervised fine-tuning dataset focused on reflection and self-critique, empowering open-source models to develop robust verification capabilities and enabling broader community advancement in DRA reliability.
Introduction
The authors leverage the asymmetry between generating and verifying answers to improve Deep Research Agents (DRAs) at inference time, addressing their tendency to produce unreliable outputs due to hallucinations, API errors, or flawed reasoning. Prior test-time scaling methods—like parallel rollouts or agent-as-judge systems—often fail to correct persistent errors or lack structured feedback mechanisms, especially for complex, multi-step DRA tasks. Their main contribution is DeepVerifier, a plug-and-play verification module that uses a taxonomy of 13 DRA failure modes to generate rubric-based feedback, enabling iterative self-refinement without retraining. It outperforms baseline judges by 12–48% in meta-evaluation F1 and boosts accuracy by 8–11% on GAIA and XBench-DeepResearch. They also release DeepVerifier-4K, a 4,646-example SFT dataset to help open models develop robust verification capabilities.
Dataset

- The authors use WebAggregatorQA to construct a DRA Failure Taxonomy, ensuring no data leakage by reserving GAIA, BrowseComp, and XBench-DeepSearch for evaluation.
- They collect 2,997 agent actions across 90 distinct tasks (trajectory lengths: 2–156 steps; correct/incorrect ratio: 0.96) using Cognitive Kernel-Pro with Claude-3.7-Sonnet as the backbone, running on WebAggregatorQA to stress-test multi-step reasoning, web browsing, and tool use.
- For trajectories with incorrect answers, two annotators independently identify 555 error points by comparing agent execution against human reference traces; each error point pinpoints localized failures like missing evidence or invalid sources. Annotator agreement averages 63.0%, with final error points merged and deduplicated.
- The taxonomy is built iteratively by two experienced AI researchers, starting with 50 error points for clustering, then refining labels across rounds to eliminate redundancy and clarify definitions. Final structure includes five major classes and thirteen subclasses (visualized in Figure 3).
- Key failure categories: Finding Sources (most frequent, e.g., wrong evidence or generic searches), Reasoning (premature conclusions, hallucinations), Problem Understanding (goal drift, misinterpretation), Action Errors (UI/format mistakes), and Max Step Reached (indicating cascading early failures).
- Annotation guidelines are detailed in Appendix A; the taxonomy informs model debugging and training design but is not directly used for training the model itself.
Method
The authors leverage a three-stage multi-module framework in DeepVerifier, designed to enhance the verification and test-time scaling capabilities of deep research agents. The overall architecture, illustrated in the framework diagram, consists of a decomposition agent, a verification agent, and a judge agent, each playing a distinct role in the verification pipeline. The process begins with an agent generating an unverified answer and its corresponding trajectory. This trajectory is then passed to the decomposition agent, which initiates a structured analysis to identify potential errors and formulate targeted follow-up questions.
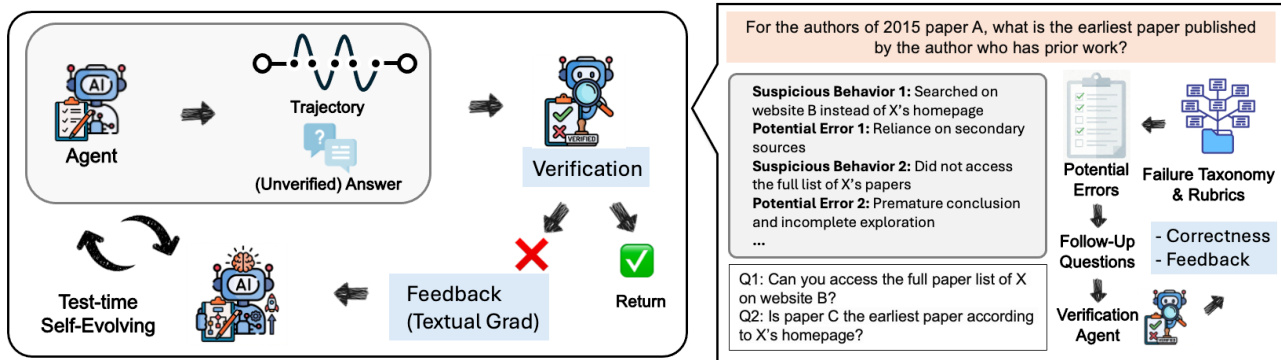
The decomposition agent operates in three sequential steps. First, it performs trajectory summarization, condensing the agent’s full trajectory—often exceeding 8.2 million tokens—into a compact, step-indexed synopsis. This summary captures the sources visited and the concrete information retrieved at each step, such as facts, numbers, or quotes, without interpretive commentary. This step ensures downstream modules can operate efficiently within limited context windows. Second, the agent identifies potential errors by scanning the summary against a predefined failure taxonomy. It generates structured pairs of the form 〈behavior〉⇒〈potential error + taxonomy label〉, each accompanied by a brief justification, thereby localizing likely failure points. Third, the agent formulates high-leverage follow-up questions that target the flagged vulnerabilities. These questions are designed to be answerable via external evidence and are intended to decisively confirm or refute specific claims, enabling focused verification.
The verification agent then retrieves answers to these follow-up questions sequentially. In the implementation, the authors use the CK-Pro agent, a modular multi-agent system where a main agent orchestrates the process by decomposing tasks into sub-tasks assigned to specialized sub-agents. These sub-agents interact with specific resources, such as search engines or document readers, and generate Python code to perform actions, ensuring adaptability across diverse scenarios. The answers to the follow-up questions are then passed to the judge agent, which evaluates the original unverified answer. The judge agent produces a concise explanation and assigns a score from 1 to 4, where 1 indicates the answer is entirely incorrect, 2 indicates it is mostly incorrect, 3 indicates it is mostly correct, and 4 indicates it is entirely correct. This evaluation incorporates the trajectory summary, the list of potential errors, the follow-up questions, and their corresponding answers.
The framework further supports test-time scaling through a self-evolving loop. After verification, the agent receives feedback from the judge agent, which includes actionable instructions to retry tasks and avoid repeating mistakes, as well as suggestions for correct answers when available. This feedback enables the agent to refine its approach iteratively, improving its performance over multiple attempts. The process repeats until a satisfactory answer is achieved or a retry limit is reached.
Experiment
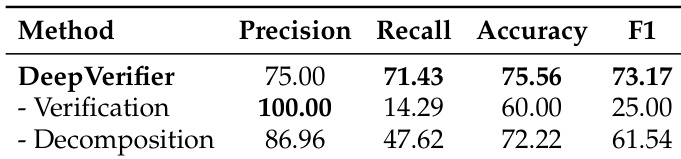
- DeepVerifier validates effectively in DRA verification, achieving 12%–48% F1 improvement over ablated versions and highest accuracy by decomposing verification into targeted sub-questions to catch subtle reasoning and factual errors.
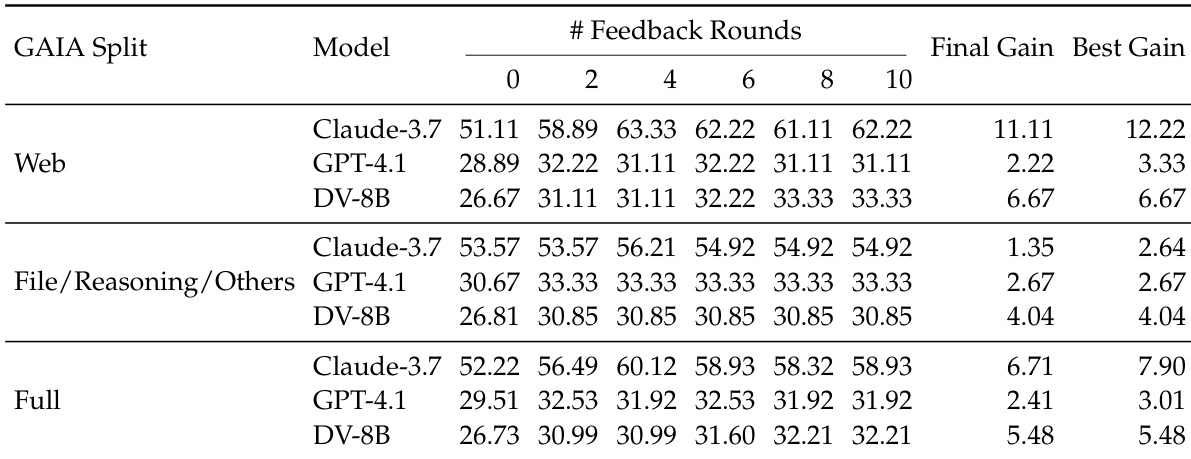
- On GAIA-Full with Claude-3.7-Sonnet, DeepVerifier boosts accuracy from 52% to 60.1% (+8%) over 4 feedback rounds; GAIA-Web sees larger gains (52% → 63.5%), showing strong benefit for web-retrieval tasks.
- Generalizes across models: GPT-4.1 improves from 29.5% to 32.5% and maintains scaling trend; also effective on XBench-DeepSearch (+6.0) and BrowseComp (+5.0), confirming cross-dataset robustness.
- Fine-tuning Qwen3-8B on DeepVerifier-4K yields DeepVerifier-8B, which achieves 32.2% accuracy after 10 rounds on GAIA—5.5% better than non-reflective baseline—demonstrating reflection ability transfer to open-source models.
Results show that DeepVerifier enhances the performance of Deep Research Agents through test-time scaling, with accuracy improving across feedback rounds and peaking at the fourth round for most models. The method achieves significant gains on the GAIA dataset, particularly on web-based tasks, and generalizes to other models and benchmarks, demonstrating robustness and effectiveness in iterative verification.
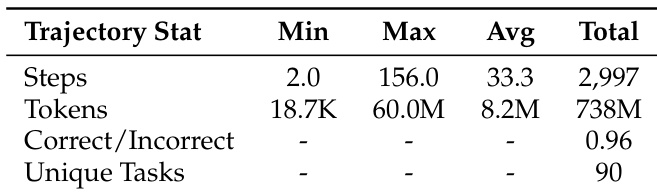
The authors use the table to present trajectory statistics from their experiment, showing that the average number of steps per task is 33.3 with a maximum of 156.0, and the average token count is 8.2 million across 738 million tokens. The data indicates that the system processes 90 unique tasks, with a correct-to-incorrect ratio of 0.96, suggesting a high level of accuracy in the agent's performance.
Results show that DeepVerifier achieves the highest accuracy and F1 score compared to its ablated versions. Removing the verification module leads to perfect precision but low recall and accuracy, indicating an inability to detect subtle errors, while removing the decomposition module results in lower recall and accuracy due to ineffective step-by-step validation.
Results show that the incorrect-to-correct transition rate decreases sharply across feedback rounds, dropping to 0% by round 5, while the correct-to-incorrect transition rate remains low but persistent, with a peak of 3.03% at round 5. This indicates that the verification process effectively corrects errors early but continues to risk rejecting correct answers, leading to a performance peak around round 4.

Results show that DeepVerifier enhances performance across multiple datasets through iterative feedback, with DeepSearch achieving a final gain of 3.0 and a best gain of 6.0, while BrowseComp reaches a final gain of 4.0 and a best gain of 5.0. The performance peaks early in the feedback process, indicating that the verifier's ability to correct errors diminishes over rounds due to a trade-off between fixing incorrect answers and incorrectly rejecting correct ones.
