Command Palette
Search for a command to run...
LongCLI-Bench: A Preliminary Benchmark and Study for Long-horizon Agentic Programming in Command-Line Interfaces
LongCLI-Bench: A Preliminary Benchmark and Study for Long-horizon Agentic Programming in Command-Line Interfaces
Abstract
Recent advances in AI-assisted programming have empowered agents to execute complex workflows via command-line interfaces, however, existing benchmarks are limited by short task horizons, data contamination from GitHub scraping, and a lack of fine-grained evaluation metrics, fail to rigorously evaluate the long-horizon planning and execution capabilities essential for realistic software engineering. To address these gaps, we introduce LongCLI-Bench, a comprehensive benchmark designed to evaluate agentic capabilities across long-horizon, realistic tasks. We curated 20 high-quality, long-horizon tasks from over 1,000 computer science assignments and real-world workflows, covering four engineering categories: from scratch, feature addition, bug fixing, and refactoring. We propose a dual-set testing protocol for LongCLI-Bench, which measures requirement fulfillment (fail-to-pass) and regression avoidance (pass-to-pass), and incorporates step-level scoring to pinpoint execution failures. Extensive experiments reveal that even state-of-the-art agents achieve pass rates below 20% in LongCLI-Bench. Step-level analysis further indicates that the majority of tasks stall at less than 30% completion, highlighting that critical failures often occur in the early stages. Although self-correction offers marginal gains, human-agent collaboration through plan injection and interactive guidance yields significantly higher improvements. These results highlight that future research must emphasize the development of synergistic human-agent workflows alongside advances in agents' planning and execution capabilities to overcome key challenges in long-horizon task performance.
One-sentence Summary
Researchers from NKU, SII, Shanda AI Research Tokyo, Shanghai AI Lab, and SJTU introduce LongCLI-Bench, a new benchmark evaluating AI agents on long-horizon CLI tasks via dual-set testing and step-level scoring, revealing severe performance gaps and advocating human-agent collaboration to improve real-world software engineering workflows.
Key Contributions
- LongCLI-Bench introduces a new benchmark of 20 long-horizon, real-world CLI tasks curated from over 1,000 CS assignments and workflows, spanning four engineering categories to address limitations in existing benchmarks like short horizons and GitHub data contamination.
- It employs a dual-set evaluation protocol measuring requirement fulfillment (fail→pass) and regression avoidance (pass→pass), enhanced with step-level scoring to identify where agents fail during complex, multi-step executions.
- Experiments show state-of-the-art agents achieve under 20% pass rates, with most failing early in tasks, while human-guided collaboration significantly outperforms self-correction, revealing planning and execution as key bottlenecks in autonomous software engineering.
Introduction
The authors leverage the growing use of AI agents in command-line-based software engineering to address a critical gap: existing benchmarks fail to evaluate long-horizon, multi-step tasks that mirror real-world development. Prior work relies on short, GitHub-scraped tasks with binary pass/fail outcomes, which mask early-stage failures and suffer from data contamination. LongCLI-Bench introduces 20 curated, complex tasks spanning four engineering categories — from scratch, feature addition, bug fixing, and refactoring — sourced from academic assignments and real workflows. It employs a dual-set evaluation (Fail→Pass and Pass→Pass) with step-level scoring to pinpoint where agents falter, revealing that even top agents achieve under 20% success, primarily due to planning and execution breakdowns in early stages. The authors further show that human collaboration — via plan injection or interactive guidance — significantly outperforms self-correction, arguing that future progress must prioritize synergistic human-agent workflows alongside autonomous agent improvements.
Dataset
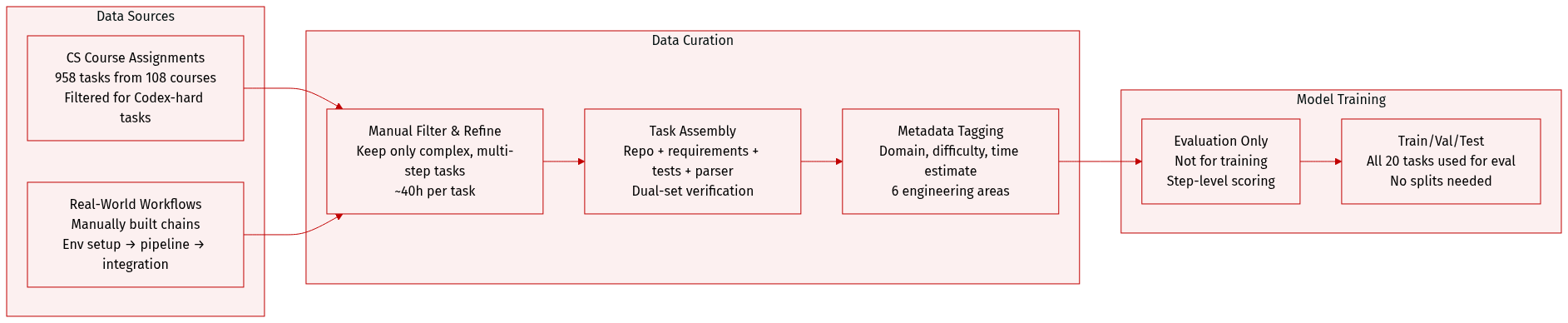
The authors use LongCLI-Bench, a curated benchmark designed to evaluate agents on long-horizon, real-world engineering tasks. Here’s how the dataset is composed and used:
-
Sources and Composition:
Tasks are drawn from two contamination-controlled sources:
• CS course assignments (958 collected from 108 courses), manually filtered to retain only complex, multi-step engineering tasks that Codex struggles with.
• Real-world research and engineering workflows, manually constructed to reflect sequential, interdependent development activities like environment setup, pipeline building, and code integration. -
Key Subset Details:
• Final benchmark contains 20 curated tasks.
• Each task includes: an initial repo, requirement doc, isolated environment, human-authored solution repo, dual-set test suite, scoring parser, and metadata (domain, difficulty, estimated human time).
• Domains span six areas: System Programming, Web Development, Data Engineering, Machine Learning, Applications, and DevOps.
• Average task size: 15,000+ LoC, 104 files, across languages like C, Python, Java, JavaScript.
• Expert completion time averages 1000+ minutes per task — significantly longer than short-benchmarks like Terminal-Bench@2. -
Data Usage in Model Training/Evaluation:
• The benchmark is not used for training; it serves as an evaluation suite to test agent planning, context retention, and execution over long, complex workflows.
• Tasks are evaluated via step-level scoring using a parser that interprets test outputs.
• Dual-set verification ensures solution correctness and regression safety. -
Processing and Construction:
• Tasks undergo iterative refinement with manual verification to ensure solvability and alignment with benchmark goals.
• No automatic scraping — all tasks are manually authored or filtered to avoid contamination.
• Each task takes ~40 hours to construct, including requirement writing, solution path design, test environment setup, and script creation.
• Metadata includes domain, difficulty, and time estimates to support granular analysis.
Method
The authors leverage a structured pipeline to construct a robust evaluation benchmark for code generation systems, emphasizing reproducibility, contamination control, and granular assessment. The process begins with sourcing task specifications from two domains: CS course assignments and real-world workflows. These are processed through a filtering mechanism that discards candidates exhibiting short-horizon solutions or easily passable execution results, ensuring task complexity and meaningful evaluation.
Refer to the framework diagram for the end-to-end workflow. The pipeline initiates with the Data Collect & Filter stage, where over a thousand task files are ingested. These are then refined into human-written requirement documents using CodeX, followed by expert review to validate task difficulty, step count, and completion status. For CS assignments, the authors partially rewrite requirements by substituting variable names and narrative context to mitigate retrieval-based contamination. For real-world tasks, requirements are manually authored from scratch to ensure originality and clarity.
As shown in the figure below:
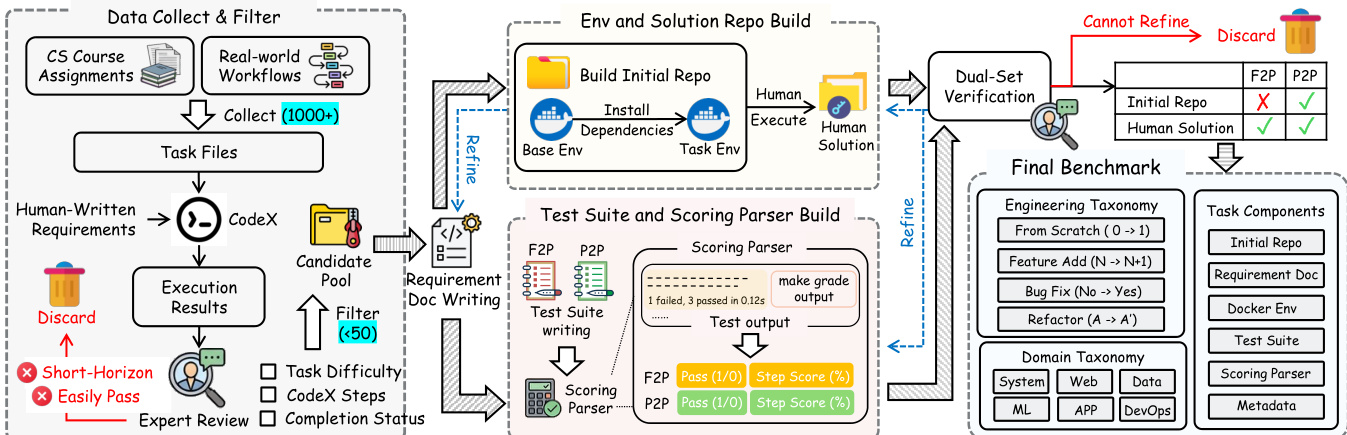
The next phase involves building the execution environment and solution codebase within Docker containers. The authors iteratively solve each task from a base image, recording all dependencies. These are then encapsulated into a Dockerfile to ensure environment consistency, while the human-authored solution forms the reference codebase for solvability verification. This dual output—environment and solution—is subjected to dual-set verification: the initial repo is tested against the human solution, and only those passing both F2P and P2P criteria proceed.
The Test Suite and Scoring Parser Build module generates structured test cases and a scoring mechanism. The parser evaluates agent outputs against functional and behavioral requirements, producing granular metrics such as pass/fail status and step scores. These are aggregated into an overall score, enabling fine-grained analysis of agent performance across functional correctness and procedural fidelity.
The final benchmark comprises two taxonomies: Engineering Taxonomy, which classifies tasks by development phase (e.g., Feature Add, Bug Fix, Refactor), and Domain Taxonomy, which categorizes by application domain (e.g., System, Web, ML, DevOps). Each benchmark entry includes the requirement document, Docker environment, test suite, scoring parser, and metadata, ensuring comprehensive and reproducible evaluation.
The agent evaluation loop, depicted in the top portion of the first figure, illustrates how an agent interacts with a terminal and toolbox, executes code, and receives test outputs over multiple attempts. The results are scored against a detailed test suite that maps requirements to functional checks, with overall metrics reflecting both functional pass rate and step-wise correctness. This architecture enables systematic, scalable, and interpretable assessment of code generation systems.
Experiment
- Tests are designed independently from implementation to avoid bias, using F2P (requirement completion) and P2P (regression prevention) sets to validate both task fulfillment and system stability.
- Tasks must satisfy strict verification: F2P fails initially but passes post-solution, while P2P passes in both states; failed tasks undergo iterative expert review or are discarded.
- Evaluation runs in isolated Docker environments, with scoring based on step-level completion; optional multi-attempt and self-correction modes allow iterative refinement.
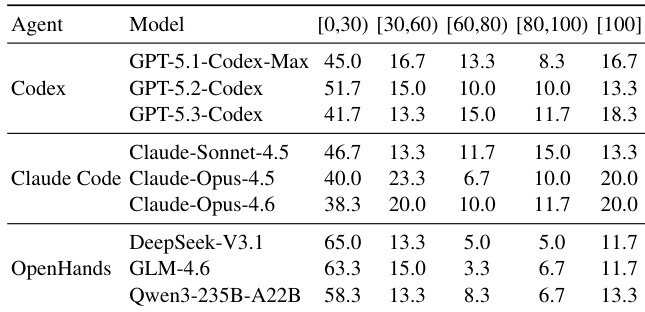
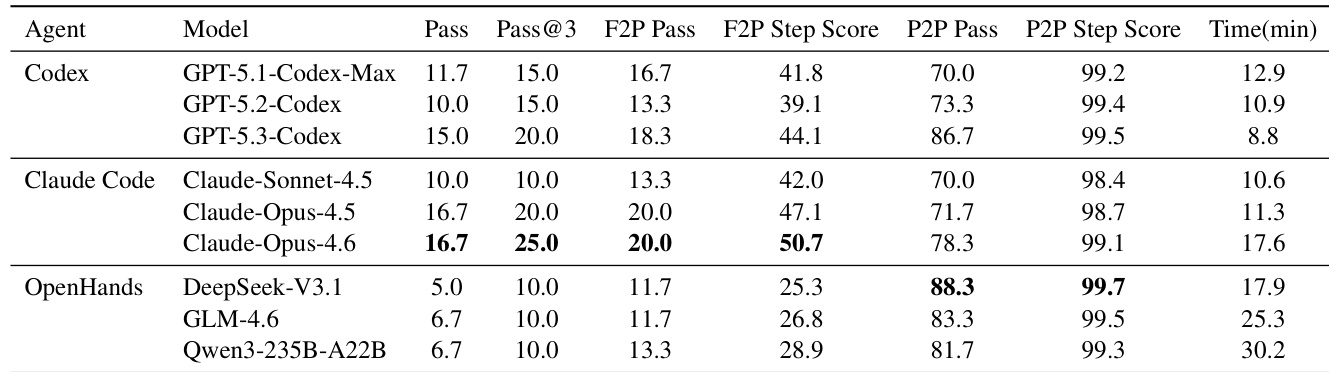
- Commercial agents (Codex, Claude) outperform open-source ones (DeepSeek, GLM, Qwen) in requirement completion, but all struggle with long-horizon tasks; top pass rate is only 16.7%.
- High P2P step scores (>98%) mask low pass rates (70–88%), revealing that agents frequently break existing functionality while adding new features.
- Failures concentrate early in tasks (<30% step score), indicating poor initial planning; commercial agents show stronger early-stage reasoning.
- Self-correction improves pass rates, especially from T1 to T2, but later rounds risk introducing regressions; time cost varies without consistent trend.
- Human collaboration—via static plan injection or dynamic guidance—significantly boosts performance; combined approach yields best results with fewer interventions.
- Failures stem not from syntax errors but from strategic breakdowns: repetitive loops, misdiagnosed environment issues, and context drift leading to regressions.
The authors use LongCLI-Bench to evaluate agent performance on complex, long-horizon CLI tasks, revealing that even top commercial models achieve pass rates below 20%, highlighting a significant gap in long-term planning and environmental awareness. Results show that while most agents maintain high step-level accuracy on regression tests, their binary pass rates are much lower, indicating frequent unintended breakage of existing functionality during modifications. Open-source agents under the OpenHands framework show lower overall completion but higher regression stability, suggesting that limited execution scope can reduce error surface area in complex tasks.
The authors evaluate agent performance under human collaboration modes, finding that combining static plan injection with dynamic interactive guidance yields the highest pass rates and step scores while reducing the average number of required human interventions. Results indicate that structured planning upfront improves efficiency, but real-time human guidance better handles unforeseen execution issues, highlighting the value of hybrid human-agent workflows over full autonomy.
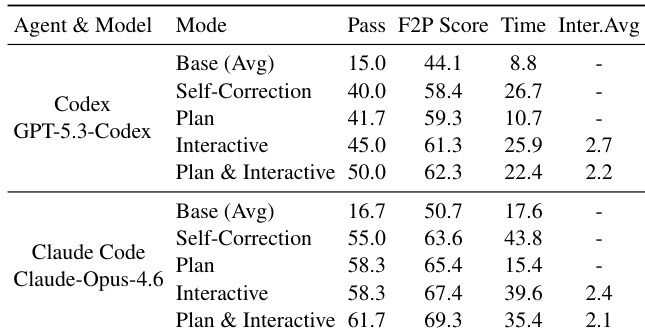
The authors use LongCLI-Bench to evaluate agent performance on complex, long-horizon CLI tasks requiring environmental awareness and multi-step planning, contrasting it with simpler benchmarks like Terminal-Bench@2. Results show that even top commercial agents achieve low pass rates, revealing significant gaps in long-term reasoning and regression prevention, while human collaboration and structured planning substantially improve outcomes.

The authors use step-level scoring to analyze where agents fail during long-horizon CLI tasks, revealing that most failures occur early in execution, with the majority of task attempts scoring below 30%. Commercial agent-model pairs show stronger early-stage performance than open-source frameworks, suggesting better initial planning, while the concentration of low scores highlights persistent challenges in maintaining workflow continuity and environmental awareness across complex, multi-step tasks.