Command Palette
Search for a command to run...
On Data Engineering for Scaling LLM Terminal Capabilities
On Data Engineering for Scaling LLM Terminal Capabilities
Renjie Pi Grace Lam Mohammad Shoeybi Pooya Jannaty Bryan Catanzaro Wei Ping
Abstract
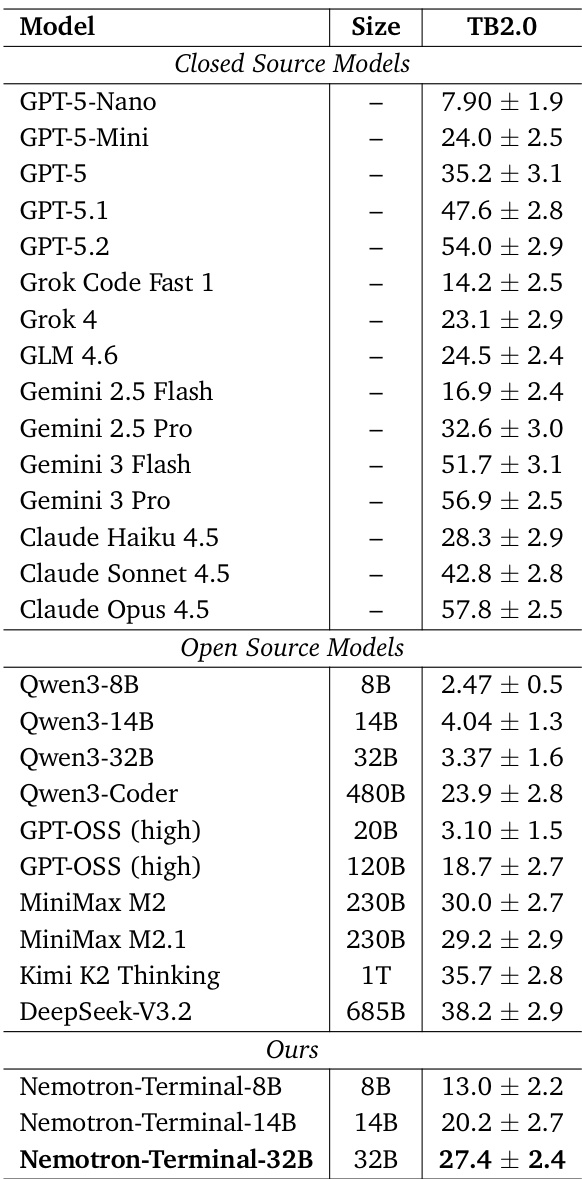
Despite rapid recent progress in the terminal capabilities of large language models, the training data strategies behind state-of-the-art terminal agents remain largely undisclosed. We address this gap through a systematic study of data engineering practices for terminal agents, making two key contributions: (1) Terminal-Task-Gen, a lightweight synthetic task generation pipeline that supports seed-based and skill-based task construction, and (2) a comprehensive analysis of data and training strategies, including filtering, curriculum learning, long context training, and scaling behavior. Our pipeline yields Terminal-Corpus, a large-scale open-source dataset for terminal tasks. Using this dataset, we train Nemotron-Terminal, a family of models initialized from Qwen3(8B, 14B, 32B) that achieve substantial gains on Terminal-Bench 2.0: Nemotron-Terminal-8B improves from 2.5% to 13.0% Nemotron-Terminal-14B improves from 4.0% to 20.2%, and Nemotron-Terminal-32B improves from 3.4% to 27.4%, matching the performance of significantly larger models. To accelerate research in this domain, we open-source our model checkpoints and most of our synthetic datasets at https://huggingface.co/collections/nvidia/nemotron-terminal.
One-sentence Summary
Renjie Pi, Grace Lam, and NVIDIA researchers propose Terminal-Task-Gen, a synthetic pipeline generating Terminal-Corpus to train Nemotron-Terminal models, which outperform larger models on Terminal-Bench 2.0 via skill-based task design and curriculum training, accelerating open terminal agent research.
Key Contributions
- We introduce Terminal-Task-Gen, a scalable synthetic task generation pipeline that combines dataset adaptation and skill-based task construction to produce Terminal-Corpus, addressing the lack of transparent, high-quality training data for terminal agents.
- We systematically evaluate data engineering strategies including filtering, curriculum learning, and long context training, revealing how targeted data composition and scaling improve terminal task performance across model sizes.
- Using Terminal-Corpus, we train Nemotron-Terminal models (8B, 14B, 32B) that achieve 13.0%, 20.2%, and 27.4% on Terminal-Bench 2.0 respectively, matching larger models while releasing checkpoints and datasets to accelerate open research.
Introduction
The authors leverage a structured data engineering approach to address the scarcity of high-quality training data for terminal-capable LLMs, a critical gap as models increasingly interact with command-line environments for software tasks. Prior methods either rely on inefficient multi-agent systems for synthetic data or repurpose non-terminal datasets via adapters that lack environmental fidelity and skill targeting. Their main contribution is Terminal-Task-Gen, a lightweight pipeline that combines dataset adaptation with skill-based synthetic task generation, enabling scalable, targeted data creation for terminal agents. Using this, they train the Nemotron-Terminal family, which achieves significant performance gains over base models and matches larger frontier systems—demonstrating that strategic data design can outperform brute-force scaling.
Dataset
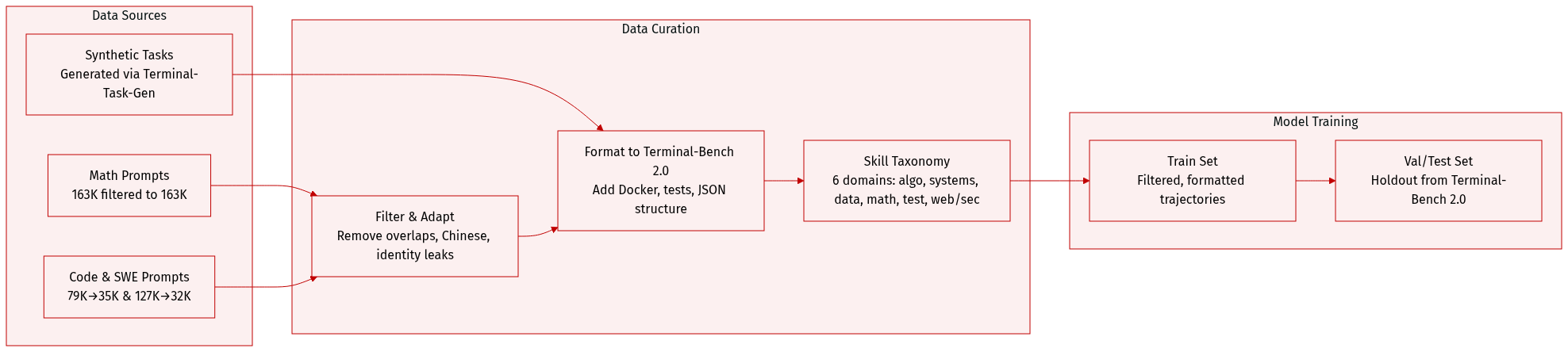
The authors use a hybrid dataset combining curated prompt collections and synthetic terminal tasks to train agents capable of end-to-end terminal workflows.
-
Dataset Composition and Sources:
- Three main prompt subsets from Nemotron-Cascade: Math (163K → 163K filtered), Code (79K → 35K filtered), and SWE (127K → 32K filtered), drawn from OpenMathReasoning, OpenCodeReasoning, and SWE-Bench variants.
- Synthetic tasks generated via Terminal-Task-Gen, using structured seeds and a taxonomy of 6 primitive skill dimensions: algorithmic, systems, data processing, mathematical, testing, and web/security.
- All data is adapted to Terminal-Bench 2.0 format using Terminus 2 templates, with environment Dockerfiles and test cases (except for adapter tasks, which lack test cases).
-
Key Subset Details:
- Math Prompts: 163K prompts filtered to exclude easy questions (based on DeepSeek-R1 response length < 2K tokens).
- Code Prompts: 79K prompts filtered and deduplicated to 35K, targeting challenging coding problems.
- SWE Prompts: 127K instances from multiple SWE benchmarks, filtered to 32K unique prompts, each including problem statements and buggy code files.
- Synthetic Tasks: Generated via LLM (DeepSeek-V3.2) using seed records (problem description, domain, optional solution) or skill-based templates; include test cases, input files, and Docker environments.
-
Data Usage and Processing:
- All trajectories are generated using Terminus 2, which structures outputs in JSON (analysis, plan, commands, task_complete).
- Prompt datasets are mapped to Terminal-Bench format by inserting prompts into the instruction placeholder with domain-specific suffixes.
- Synthetic tasks are formatted with natural language prompts, pytest test cases (with partial credit weights), input files, and Docker environments — matching Terminal-Bench structure.
- No oracle solutions are generated for synthetic tasks; correctness is verified via synthesized tests.
-
Filtering and Curation:
- Decontamination: Remove prompts with 14-gram overlap with Terminal-Bench 2.0 test samples.
- Quality filters: Remove identity leaks and responses containing Chinese characters.
- Optional trajectory filtering: Discard incomplete or failing trajectories to encourage conciseness and correctness.
- Skill taxonomy ensures coverage across domains including security, software engineering, data science, and system administration.
Method
The authors leverage a two-stage synthetic data generation pipeline to construct a large-scale, high-quality dataset for training terminal-based autonomous agents. The framework begins with dataset adaptation, which ingests existing problem repositories—such as Math, Code, and Software Engineering (SWE) datasets—and transforms them into terminal-compatible tasks through prompt filtering, deduplication, and structural adaptation. This stage ensures broad foundational coverage by converting abstract problem statements into executable terminal workflows that include explicit file I/O requirements and verification criteria.
As shown in the figure below, the synthetic task generation stage operates in parallel, drawing from two distinct sources: seed data and a curated taxonomy of primitive terminal skills. Seed-based generation uses high-quality problem specifications from adjacent domains (e.g., scientific computing or algorithmic challenges) and prompts an LLM to reframe them as self-contained terminal tasks. The LLM adapter augments each problem with concrete engineering constraints—such as package installation, input/output file paths, and test case generation—while ensuring solution isolation to prevent leakage. The resulting tasks are paired with pre-built domain-specific Docker images that encapsulate common dependencies, enabling efficient, scalable task creation without per-task environment construction.
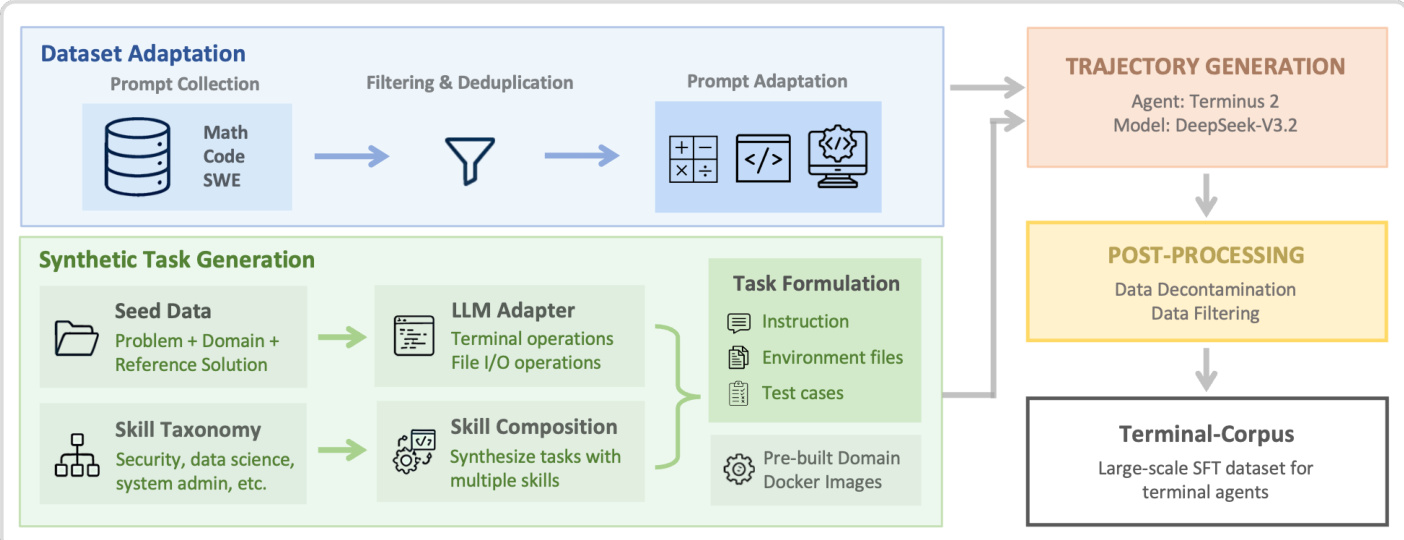
Skill-based generation, in contrast, synthesizes novel tasks from a structured set of primitive terminal operations—such as file manipulation, dependency management, or debugging—organized into nine domain-specific categories. The LLM is prompted to creatively combine 3–5 primitives per task, ensuring novelty while maintaining verifiability. Domain-specific modules, such as those for Data Science or Security, are injected into a standardized system prompt template to guide task formulation. These modules enforce domain-appropriate constraints—for example, requiring statistical analysis pipelines in Data Science or exploit payload crafting in Security—while preserving a uniform output format for downstream processing.
The system prompt template, as illustrated in the figure below, mandates that generated tasks be self-contained, realistic, and programmatically verifiable. It enforces strict rules against solution leakage and requires explicit specification of file paths, formats, and test requirements. Each task must include a prompt, test cases, metadata, and environment configuration, all encoded in XML tags for structured parsing. The prompt also specifies that tasks should be challenging to solve but easy to verify, ensuring that agents must reason rather than retrieve.

For dataset adaptation, domain-specific instruction templates are applied to seed problems. For instance, the Math adapter instructs the agent to write the final answer to /app/solution.txt, while the SWE adapter directs the agent to localize bugs, generate SEARCH/REPLACE edits, and save the diff to /app/solution.patch. These templates ensure consistent task structure across domains while preserving the semantic intent of the original problem.


Generated tasks are then executed by the Terminus 2 agent, which operates within a sandboxed Docker container via an interactive tmux session. At each step, the agent receives terminal output and responds with a structured JSON action plan containing analysis, next-step reasoning, and a sequence of keystrokes to execute. The agent’s model, DeepSeek-V3.2, is fine-tuned on the resulting trajectory data, which undergoes post-processing for decontamination and filtering before being compiled into the final Terminal-Corpus dataset. This end-to-end pipeline enables systematic coverage of terminal-based problem-solving skills while maintaining scalability and domain coherence.
Experiment
- Validated that Nemotron-Terminal models, trained on curated synthetic data, significantly outperform larger base models on Terminal-Bench 2.0, achieving competitive results with modest compute resources.
- Demonstrated that synthetic trajectory data enables small models to acquire domain-specific terminal skills—such as debugging, security, and data querying—that base models entirely lack.
- Confirmed that combining diverse data sources (math, code, SWE) yields stronger performance than any single source, highlighting the value of data diversity.
- Found that filtering trajectories during training harms performance; retaining incomplete or failed trajectories improves robustness by exposing models to realistic error recovery patterns.
- Showed that extending context length beyond standard limits does not improve performance and may degrade it due to noisy long-tail data.
- Established that mixed-stage curriculum learning offers no advantage over concurrent training, supporting simpler data mixing strategies.
- Verified that both model scale and training data volume positively impact performance, with larger models benefiting more from increased data.
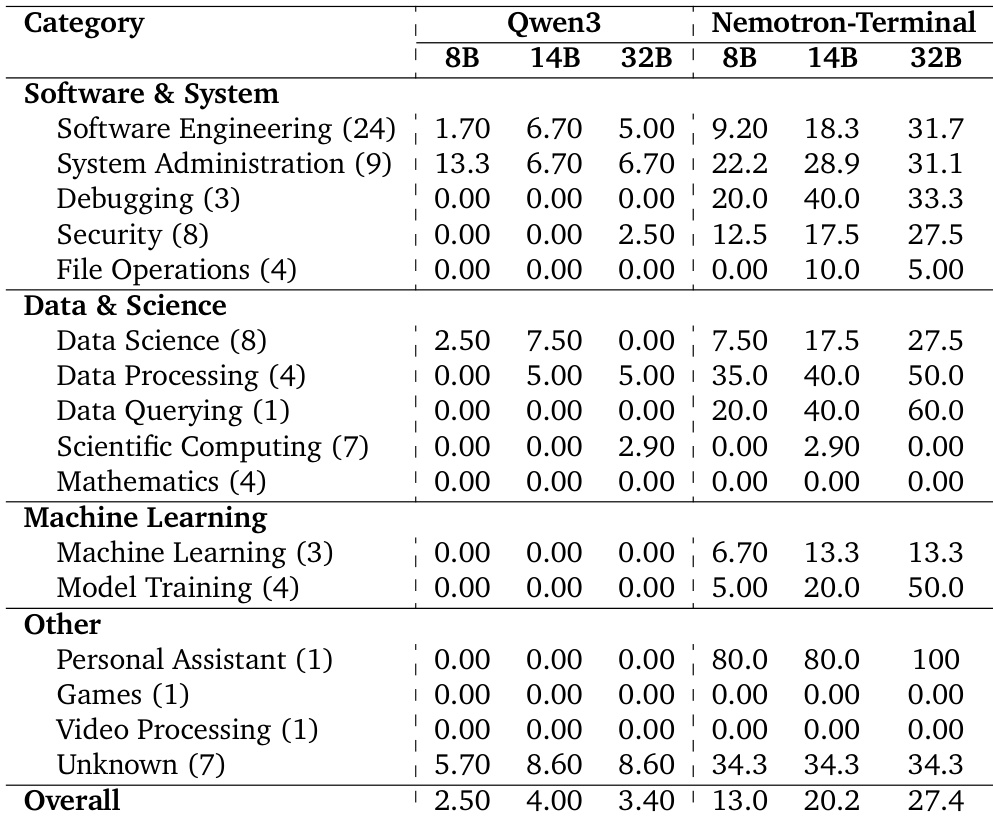
The authors use synthetic terminal trajectory data to fine-tune Qwen3 models, achieving performance that rivals or exceeds much larger models on Terminal-Bench 2.0 despite modest parameter counts. Results show that their Nemotron-Terminal variants significantly outperform base Qwen3 models and even surpass several closed-source and open-source systems, demonstrating that high-quality, domain-specific training data can close the capability gap with frontier models. The gains are especially pronounced in functional categories like Data Querying, Security, and Debugging, where base models previously failed entirely.
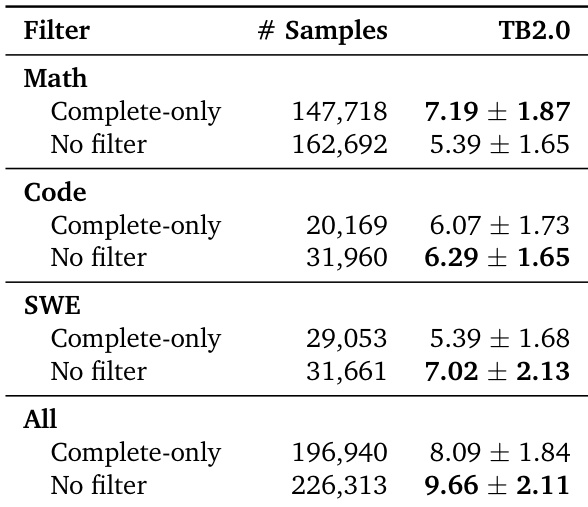
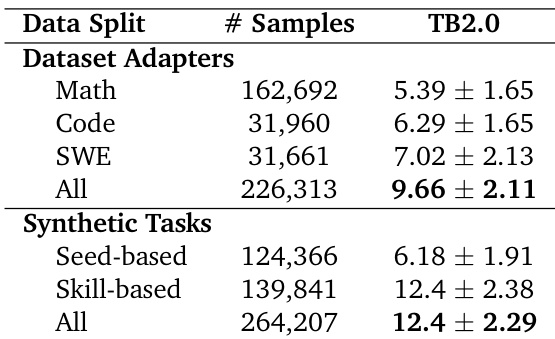
The authors evaluate trajectory filtering strategies on dataset adapters and find that applying no filter consistently yields higher performance than complete-only filtering, particularly when combining all data sources. Results show that retaining incomplete trajectories improves model outcomes, suggesting that exposure to partial or failed attempts provides valuable learning signals. This indicates that strict filtering may discard useful training data and reduce overall effectiveness.
The authors evaluate the impact of different training data sources on model performance, finding that combining multiple domains yields stronger results than any single source alone. Synthetic tasks, particularly those based on skills, drive the largest performance gains, while adding seed-based data improves robustness without increasing mean scores. Results confirm that diverse, high-quality data is more effective than relying on any single data type.
The authors use synthetic trajectory data to fine-tune Qwen3 models, resulting in Nemotron-Terminal variants that significantly outperform their base counterparts across nearly all terminal task categories. Results show that even smaller models like the 8B and 14B versions achieve substantial gains, with the 32B model rivaling much larger systems by mastering previously inaccessible domains such as data querying and model training. The improvements highlight that targeted data curation, rather than model scale alone, is key to unlocking robust terminal-based capabilities.
The authors compare two fine-tuning strategies for Qwen3-8B on Terminal-Bench 2.0, finding that a mixed single-stage training approach outperforms a two-stage curriculum strategy. Results show the mixed strategy achieves a higher score of 13.03 ± 2.16 compared to 10.39 ± 1.71 under curriculum learning, indicating no benefit from staged data exposure in this setting.
