HyperAI
HyperAI
主区域
首页
GPU
控制台
文档
价格
Pulse
报道
资源
论文
教程
数据集
百科
基准测试
SOTA
大语言模型(LLM)
GPU 排行榜
社区
活动
开源
实用工具
搜索
关于
服务条款
隐私政策
中文
HyperAI
HyperAI
Toggle Sidebar
⌘
K
Command Palette
Search for a command to run...
登录
HyperAI
论文
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势
HyperAI
HyperAI
主区域
首页
GPU
控制台
文档
价格
Pulse
报道
资源
论文
教程
数据集
百科
基准测试
SOTA
大语言模型(LLM)
GPU 排行榜
社区
活动
开源
实用工具
搜索
关于
服务条款
隐私政策
中文
HyperAI
HyperAI
Toggle Sidebar
⌘
K
Command Palette
Search for a command to run...
登录
HyperAI
论文
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势
OmniDrive:一种包含反事实推理的自动驾驶综合视觉-语言数据集
自动驾驶
LLM
Shihao Wang, Zhiding Yu, Xiaohui Jiang, et al.
EcoMapper:面向气候的卫星影像生成建模
文生图
图像生成
Muhammed Goktepe, Amir hossein Shamseddin, Erencan Uysal, et al.
JarvisArt:通过智能照片修缮代理解放人类艺术创造力
多模态
计算机视觉
Lin, Yunlong, Lin, et al.
ScaleCap:通过双模态去偏实现推理时可扩展的图像描述生成
图像描述
多模态
Long Xing, Qidong Huang, Xiaoyi Dong, et al.
GRPO-CARE:多模态推理中的一致性感知强化学习
强化学习
多模态
Chen, Yi, Ge, et al.
Skywork-SWE:揭示大型语言模型中软件工程的数据规模定律
代码生成
LLM
Liang Zeng, Yongcong Li, Yuzhen Xiao, et al.
矩阵游戏:互动世界基础模型
视频生成
图生视频
Yifan Zhang, Chunli Peng, Boyang Wang, et al.
AnimaX:使用联合视频-姿态扩散模型在3D中赋予无生命物体以动画效果
扩散模型
3D 生成
Zehuan Huang, Haoran Feng, Yangtian Sun, et al.
基于学习的无人机高效视觉主动跟踪飞行目标方法
目标跟踪
目标检测
Jagadeswara PKV Pothuri, Aditya Bhatt, Prajit KrisshnaKumar, et al.
TritonZ:一种用于探索和救援作业的遥控水下漫游车带机械臂
机器人技术
计算机视觉
Kawser Ahmed, Mir Shahriar Fardin, Md Arif Faysal Nayem, et al.
ReasonFlux-PRM:轨迹感知的PRM用于LLM中的长链推理
监督式微调
偏好
Jiaru Zou, Ling Yang, Jingwen Gu, et al.
Phantom-Data:面向通用主题一致的视频生成数据集
文生视频
图生视频
Zhuowei Chen, Bingchuan Li, Tianxiang Ma, et al.
RLPR:将RLVR外推至无需验证器的一般领域
基准
推理
Tianyu Yu, Bo Ji, Shouli Wang, et al.
LongWriter-Zero:通过强化学习掌握超长文本生成
LLM
文本生成
Yuhao Wu, Yushi Bai, Zhiqiang Hu, et al.
法线之光:通用光度立体的统一特征表示
计算机视觉
图像理解
Hong Li, Houyuan Chen, Chongjie Ye, et al.
利用STATE预测细胞在不同环境下对扰动的反应
深度学习
建模
Abhinav K. Adduri, Dhruv Gautam, Beatrice Bevilacqua, et al.
CodeDiffuser:通过VLM生成的代码增强注意力扩散策略以解决指令模糊性
机器人技术
代码生成
Guang Yin, Yitong Li, Yixuan Wang, et al.
优化多语言文本转语音技术以包含口音和情感
语音生成
统一多模态
Pawar, Pranav, Dwivedi, et al.
VIKI-R:通过强化学习协调具身多智能体合作
具身智能
强化学习
Kang, Li, Song, et al.
PAROAttention:面向模式的重排序以提高视觉生成模型中稀疏和量化注意力机制的效率
Transformer
视频处理
Zhao, Tianchen, Hong, et al.
视觉引导的分块是你所需要的:增强RAG的多模态文档理解
检索增强生成
文档理解
Tripathi, Vishesh, Odapally, et al.
拖放式LLM:零样本提示到权重
LLM
机器学习
Liang, Zhiyuan, Tang, et al.
进化缓存加速现成扩散模型
扩散模型
文生图
Aggarwal, Anirud, Shrivastava, et al.
RE-IMAGINE:用于推理评估的符号基准合成
LLM
推理
Xu, Xinnuo, Lawrence, et al.
SonicVerse:基于音乐特征的多任务学习字幕生成
多模态
语音生成
Chopra, Anuradha, Roy, et al.
并非一切尽失:无需检查点的LLM恢复
Transformer
模型训练
Blagoev, Nikolay, Ersoy, et al.
日晷:一系列功能强大的时间序列基础模型
Transformer
建模
Yong Liu, Guo Qin, Zhiyuan Shi, et al.
ADRD:基于规则决策系统的LLM驱动自主驾驶
LLM
推理
Fanzhi Zeng, Siqi Wang, Chuzhao Zhu, et al.
改进的迭代精炼方法用于通过结构化指令实现图表到代码的生成
代码生成
多模态
Chengzhi Xu, Yuyang Wang, Lai Wei, et al.
Show-O2:改进的原生统一多模态模型
统一多模态
多模态表征
Jinheng Xie, Zhenheng Yang, Mike Zheng Shou
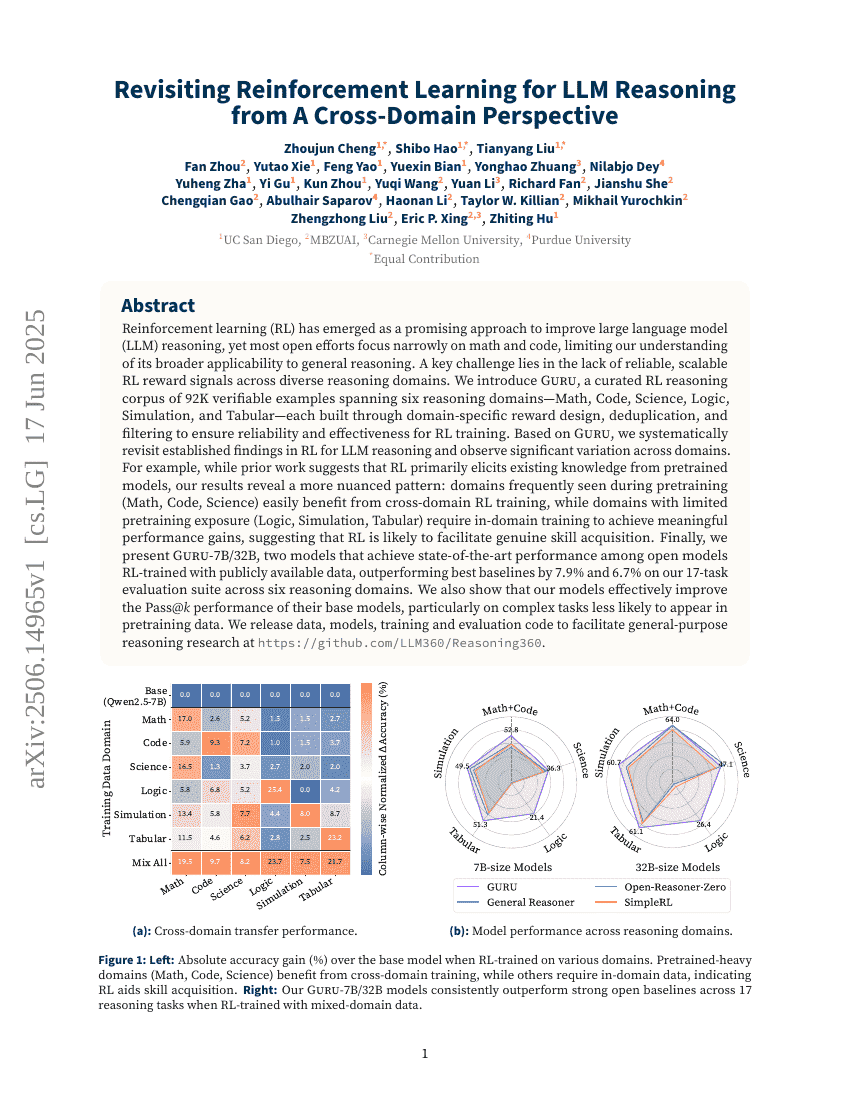
从跨领域视角重新审视强化学习在大语言模型推理中的应用
强化学习
推理
Zhoujun Cheng, Shibo Hao, Tianyang Liu, et al.
Raptor:利用预训练2D基础模型实现可扩展的无训练3D医学体积嵌入
Transformer
医学影像
Ulzee An, Moonseong Jeong, Simon Austin Lee, et al.
1
43
44
45
46
47
48
49
OmniDrive:一种包含反事实推理的自动驾驶综合视觉-语言数据集
自动驾驶
LLM
Shihao Wang, Zhiding Yu, Xiaohui Jiang, et al.
EcoMapper:面向气候的卫星影像生成建模
文生图
图像生成
Muhammed Goktepe, Amir hossein Shamseddin, Erencan Uysal, et al.
JarvisArt:通过智能照片修缮代理解放人类艺术创造力
多模态
计算机视觉
Lin, Yunlong, Lin, et al.
ScaleCap:通过双模态去偏实现推理时可扩展的图像描述生成
图像描述
多模态
Long Xing, Qidong Huang, Xiaoyi Dong, et al.
GRPO-CARE:多模态推理中的一致性感知强化学习
强化学习
多模态
Chen, Yi, Ge, et al.
Skywork-SWE:揭示大型语言模型中软件工程的数据规模定律
代码生成
LLM
Liang Zeng, Yongcong Li, Yuzhen Xiao, et al.
矩阵游戏:互动世界基础模型
视频生成
图生视频
Yifan Zhang, Chunli Peng, Boyang Wang, et al.
AnimaX:使用联合视频-姿态扩散模型在3D中赋予无生命物体以动画效果
扩散模型
3D 生成
Zehuan Huang, Haoran Feng, Yangtian Sun, et al.
基于学习的无人机高效视觉主动跟踪飞行目标方法
目标跟踪
目标检测
Jagadeswara PKV Pothuri, Aditya Bhatt, Prajit KrisshnaKumar, et al.
TritonZ:一种用于探索和救援作业的遥控水下漫游车带机械臂
机器人技术
计算机视觉
Kawser Ahmed, Mir Shahriar Fardin, Md Arif Faysal Nayem, et al.
ReasonFlux-PRM:轨迹感知的PRM用于LLM中的长链推理
监督式微调
偏好
Jiaru Zou, Ling Yang, Jingwen Gu, et al.
Phantom-Data:面向通用主题一致的视频生成数据集
文生视频
图生视频
Zhuowei Chen, Bingchuan Li, Tianxiang Ma, et al.
RLPR:将RLVR外推至无需验证器的一般领域
基准
推理
Tianyu Yu, Bo Ji, Shouli Wang, et al.
LongWriter-Zero:通过强化学习掌握超长文本生成
LLM
文本生成
Yuhao Wu, Yushi Bai, Zhiqiang Hu, et al.
法线之光:通用光度立体的统一特征表示
计算机视觉
图像理解
Hong Li, Houyuan Chen, Chongjie Ye, et al.
利用STATE预测细胞在不同环境下对扰动的反应
深度学习
建模
Abhinav K. Adduri, Dhruv Gautam, Beatrice Bevilacqua, et al.
CodeDiffuser:通过VLM生成的代码增强注意力扩散策略以解决指令模糊性
机器人技术
代码生成
Guang Yin, Yitong Li, Yixuan Wang, et al.
优化多语言文本转语音技术以包含口音和情感
语音生成
统一多模态
Pawar, Pranav, Dwivedi, et al.
VIKI-R:通过强化学习协调具身多智能体合作
具身智能
强化学习
Kang, Li, Song, et al.
PAROAttention:面向模式的重排序以提高视觉生成模型中稀疏和量化注意力机制的效率
Transformer
视频处理
Zhao, Tianchen, Hong, et al.
视觉引导的分块是你所需要的:增强RAG的多模态文档理解
检索增强生成
文档理解
Tripathi, Vishesh, Odapally, et al.
拖放式LLM:零样本提示到权重
LLM
机器学习
Liang, Zhiyuan, Tang, et al.
进化缓存加速现成扩散模型
扩散模型
文生图
Aggarwal, Anirud, Shrivastava, et al.
RE-IMAGINE:用于推理评估的符号基准合成
LLM
推理
Xu, Xinnuo, Lawrence, et al.
SonicVerse:基于音乐特征的多任务学习字幕生成
多模态
语音生成
Chopra, Anuradha, Roy, et al.
并非一切尽失:无需检查点的LLM恢复
Transformer
模型训练
Blagoev, Nikolay, Ersoy, et al.
日晷:一系列功能强大的时间序列基础模型
Transformer
建模
Yong Liu, Guo Qin, Zhiyuan Shi, et al.
ADRD:基于规则决策系统的LLM驱动自主驾驶
LLM
推理
Fanzhi Zeng, Siqi Wang, Chuzhao Zhu, et al.
改进的迭代精炼方法用于通过结构化指令实现图表到代码的生成
代码生成
多模态
Chengzhi Xu, Yuyang Wang, Lai Wei, et al.
Show-O2:改进的原生统一多模态模型
统一多模态
多模态表征
Jinheng Xie, Zhenheng Yang, Mike Zheng Shou
从跨领域视角重新审视强化学习在大语言模型推理中的应用
强化学习
推理
Zhoujun Cheng, Shibo Hao, Tianyang Liu, et al.
Raptor:利用预训练2D基础模型实现可扩展的无训练3D医学体积嵌入
Transformer
医学影像
Ulzee An, Moonseong Jeong, Simon Austin Lee, et al.
1
43
44
45
46
47
48
49